1. Definition
Die Textvisualisierung als Teilbereich der Informationsvisualisierung befasst sich mit der visuellen Repräsentation komplexer Textdaten und der Manipulierbarkeit dieser Repräsentation durch interaktive Softwareinterfaces (vgl. Card et al. 1999). Visuelle Darstellungen können neue Einsichten in Textdaten und deren innere Zusammenhänge liefern.
Textvisualisierungen unterstützen sowohl die Kommunikation von Forschungsergebnissen als auch die explorative Analysetätigkeit. Hierbei sind grundlegend drei verschiedene Arten von Daten zu unterscheiden, die für die Visualisierung herangezogen werden können:
- Der unbearbeitete Text, aus dem mithilfe statistischer Verfahren oder Natural Language Processing Datensätze generiert werden. Ein Beispiel hierfür ist die Berechnung von Worthäufigkeiten.
- Mit Zusatzinformationen, d. h. mit manuell oder automatisch erzeugten Annotationen angereicherter Text.
- Textexterne Metadaten (wie Erscheinungsdatum, Autorenangaben, Titel etc.) oder andere Daten, die sich mit Annotationen verknüpfen lassen (etwa Geokoordinaten mit annotierten Ortsnennungen).
In der Praxis kommen zudem häufig auch Kombinationen dieser verschiedenen Datenarten zum Einsatz, die mit unterschiedlichen Visualisierungen jeweils unterschiedliche Perspektiven auf den Text (oder die Textsammlung) ermöglichen.
2. Anwendungsbeispiel
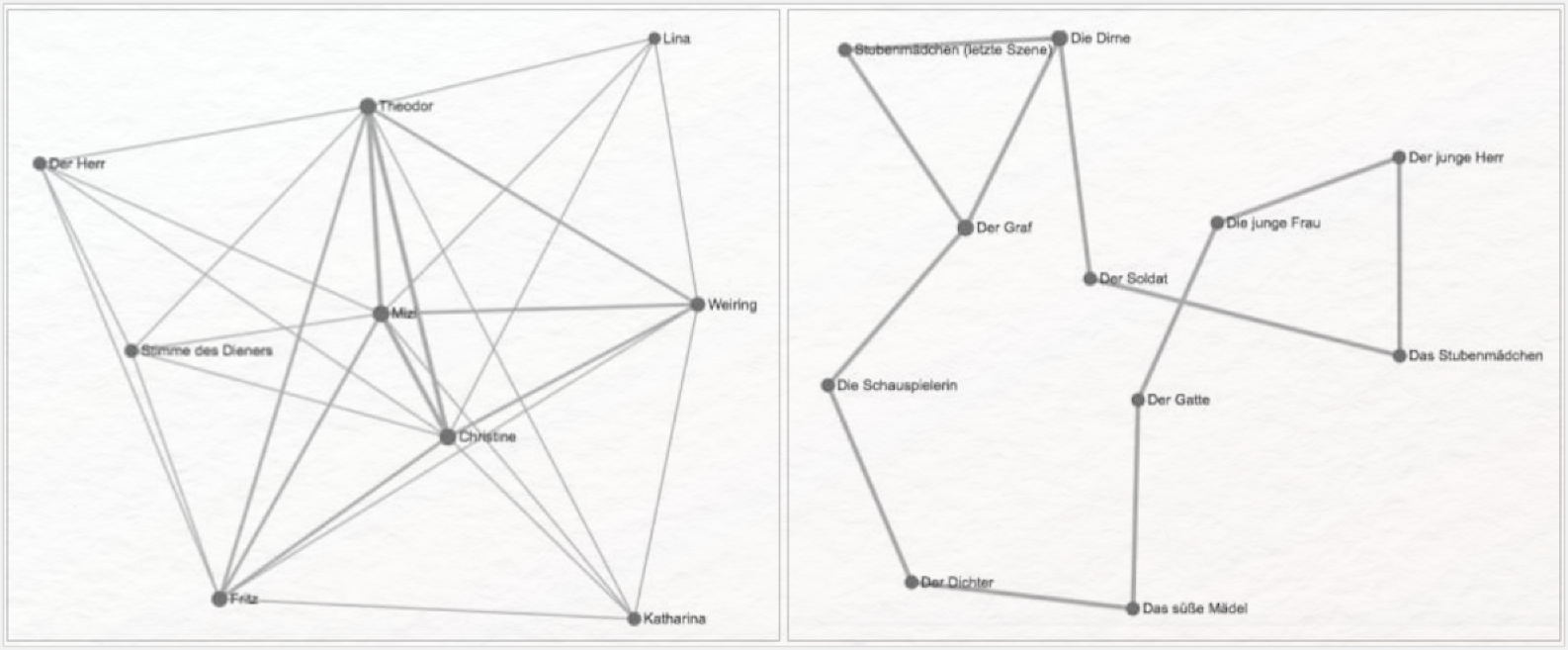
Sie erforschen Figurenkonstellationen in deutschsprachigen Dramen um 1900. Um deutlich zu machen, dass die Interaktionen der Figuren in den einzelnen Dramen sehr unterschiedlicher Art sind, entscheiden Sie sich, die Figurenkonstellationen als Netzwerke zu visualisieren und einander gegenüber zu stellen. Auch Betrachter*innen, die beispielsweise Arthur Schnitzlers Reigen nicht gelesen haben, wird so die besondere Interaktionsstruktur dieses Dramas augenfällig.
Weil Sie außerdem deutlich machen wollen, wann im Verlauf der Dramen die jeweiligen Figuren auftreten, entscheiden Sie sich für eine Visualisierung der Figurendistribution über den Textverlauf als Balkendiagramm. Für den Reigen sieht das beispielsweise so aus:
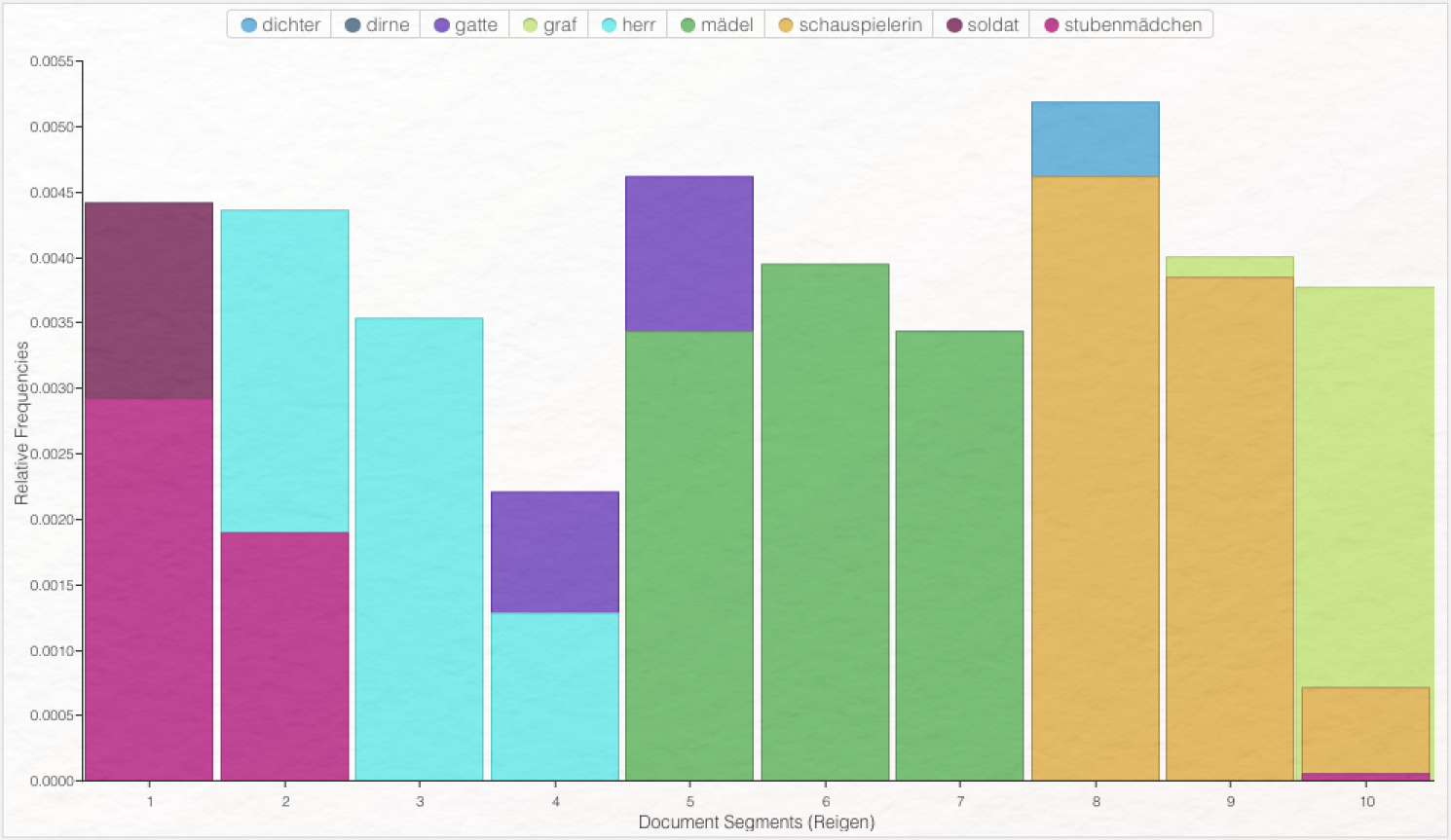
Viele weitere Visualisierungsmöglichkeiten werden Ihnen einen jeweils anders gearteten Blick auf Ihre Textsammlung oder einzelne Texte darin ermöglichen. Je nach Fragestellung sind einzelne Visualisierungsmöglichkeiten mehr oder weniger geeignet. Hermeneutisch anspruchsvollere Fragen lassen sich häufig in der Kombination möglichst reichhaltiger Textannotationen mit den statistischen Textdaten selbst verfolgen und Visualisierungen dieser kombinierten unterschiedlichen Datentypen halten häufig literaturwissenschaftlich relevante Erkenntnisse bereit.
3. Literaturwissenschaftliche Tradition
Die Vorteile, die es mit sich bringt, (textliche) Phänomene zu visualisieren und damit zu veranschaulichen, wurden in der Literatur (und dann auch in der Literaturwissenschaft) schon früh erkannt. Schon Goethe stellte in seinen Naturwissenschaftlichen Schriften zur Erkenntnisfunktion von visuellen Eindrücken fest: „Das Ohr ist stumm, der Mund ist taub; aber das Auge vernimmt und spricht. In ihm spiegelt sich von außen die Welt, von innen der Mensch" (Goethe: WA II, 5 (2), 12).
Solange es Texte gibt, wurden diese mit bildlichen Darstellungen kombiniert und zu diesen in Bezug gesetzt, besonders kunstvoll in der Buchmalerei der Spätantike und des Mittelalters, die mit ihren Bordüren und Drolerien weit über verzierte Initialen hinaus ging und Textinhalt und Verzierung eng miteinander verknüpfte. Wenn eine zeitgenössische Autorin wie Cornelia Funke ihre Bücher mit Illustrationen der darin vorkommenden Figuren und Orte versieht, führt sie diese Tradition fort. Aber auch bereits die Verwendung unterschiedlicher Schriftarten oder -farben (wie beispielsweise in Michael Endes Roman Die unendliche Geschichte [1979]) oder die häufige Verwendung von Kursivierungen in John Irvings Romanen gibt visuellen Elementen die Möglichkeit, Textinhalte semantisch anzureichern (zur visuellen Materialität von Literatur vgl. bspw. Kammer 2014). Künstlerisch in das Zentrum der Aufmerksamkeit gestellt wird die Verbindung von Text und Bild in der ihrerseits auf eine lange Tradition zurückblickenden visuellen Dichtung (vgl. Adler und Ernst 1987), bei der die räumliche Verortung von Wörtern oder Wortgruppen bereits zur Aussage des jeweiligen Gedichtes beiträgt.
Diese Formen von Text-Bild-Relationen beziehen sich jedoch auf literarische Primärtexte und nicht selten auf die Präsentation des gesamten Textes. Definieren wir Textvisualisierung jedoch als visuelle Repräsentation von Textdaten, wie wir es oben getan haben, tritt die Sekundärliteratur in den Fokus der Aufmerksamkeit, innerhalb derer diese Repräsentation i. d. R. stattfindet.
Die visuelle Repräsentation von Textdaten (oder auch von Metatextdaten) findet in der literaturwissenschaftlichen Forschung mehrere Vorgänger. Einige davon sind so alltäglich, dass sie uns kaum noch als Textvisualisierung bewusst werden, wie z. B. in der Versanalyse, in der es standardisierte Darstellungsweisen bspw. für Hebungen, Senkungen und Zäsuren in der Versfußnotation oder für akzentuierte Silben, Pausen, Taktgrenzen etc. in der Silbenakzentnotation gibt.

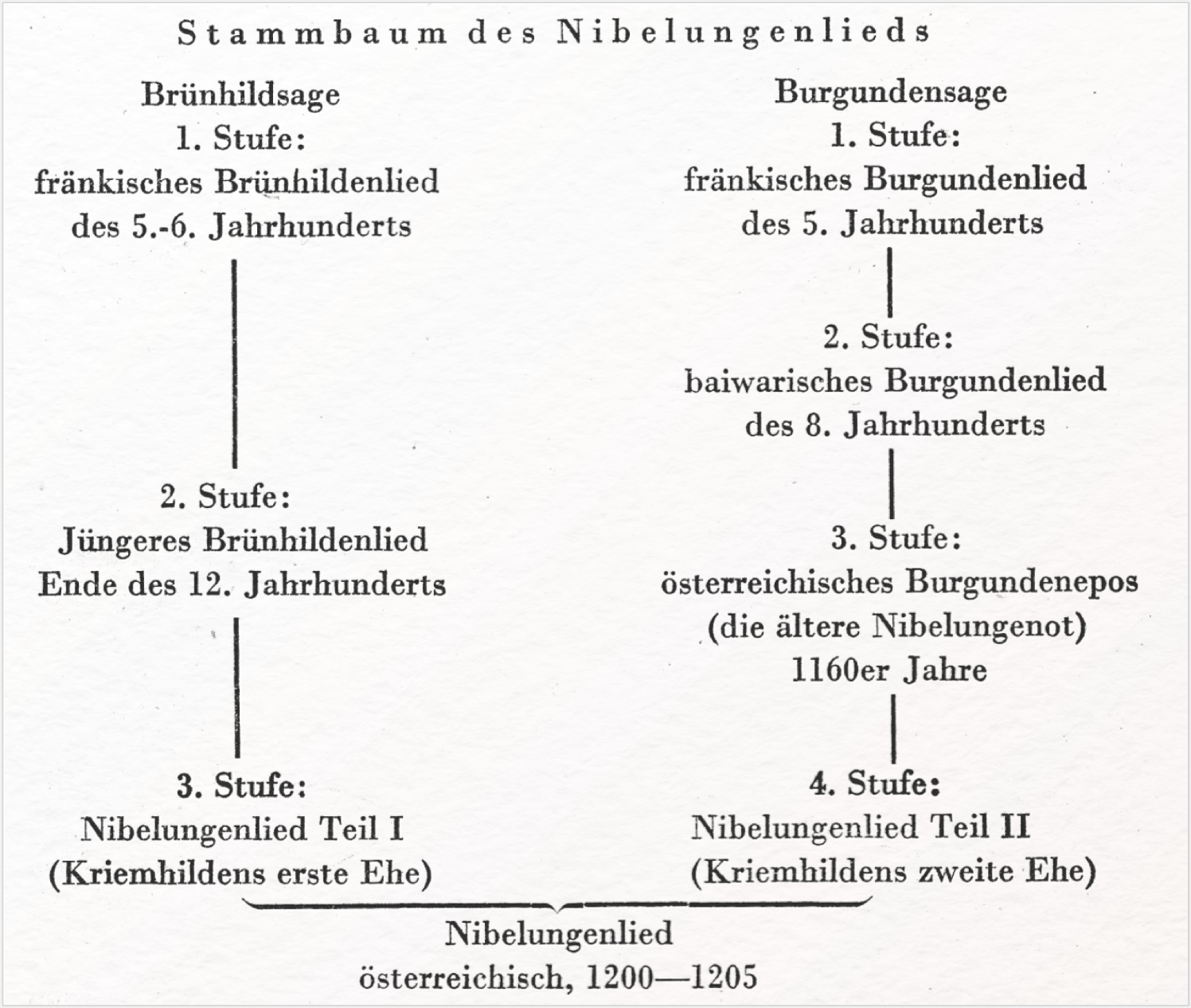
Ebenso häufig werden Figurenkonstellationen als Netzwerke visualisiert. Eder (2007, 239) nennt als mögliche Ebenen der Verbindungen zwischen den einzelnen Figuren 1. handlungsfunktionale Verhältnisse, 2. körperliche, psychische, soziale, symbolische Ähnlichkeiten und Kontraste und 3. die „Positionen innerhalb einer Aufmerksamkeitshierarchie”. Damit beschreibt er nichts anderes als die Knoten (= Figuren) und Kanten (= Verbindungen) in einer Netzwerkvisualisierung (vgl. → Netzwerkanalyse). Die im Anwendungsbeispiel oben dargestellten Netzwerke zeigen jedoch noch eine andere Form von Verbindungen, nämlich die Kopräsenz von Figuren im jeweiligen Drama. In der Dicke der Kanten spiegelt sich dann die von Eder benannte Aufmerksamkeitshierarchie. Ähnlich werden gelegentlich auch Abstammungsverhältnisse literarischer Figuren nicht nur sprachlich erläutert, sondern visuell als Stammbaum dargestellt. Dies geschieht auch mit einzelnen Überlieferungsstufen älterer Texte wie des Nibelungenliedes:
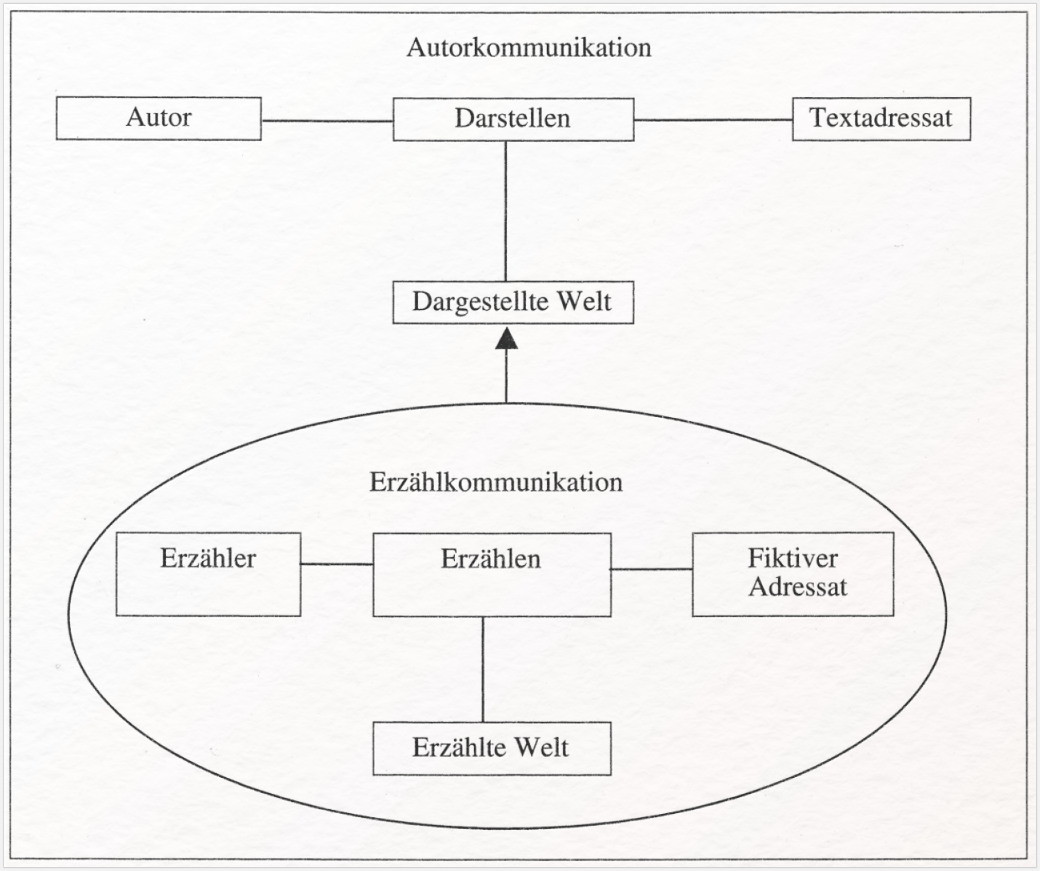
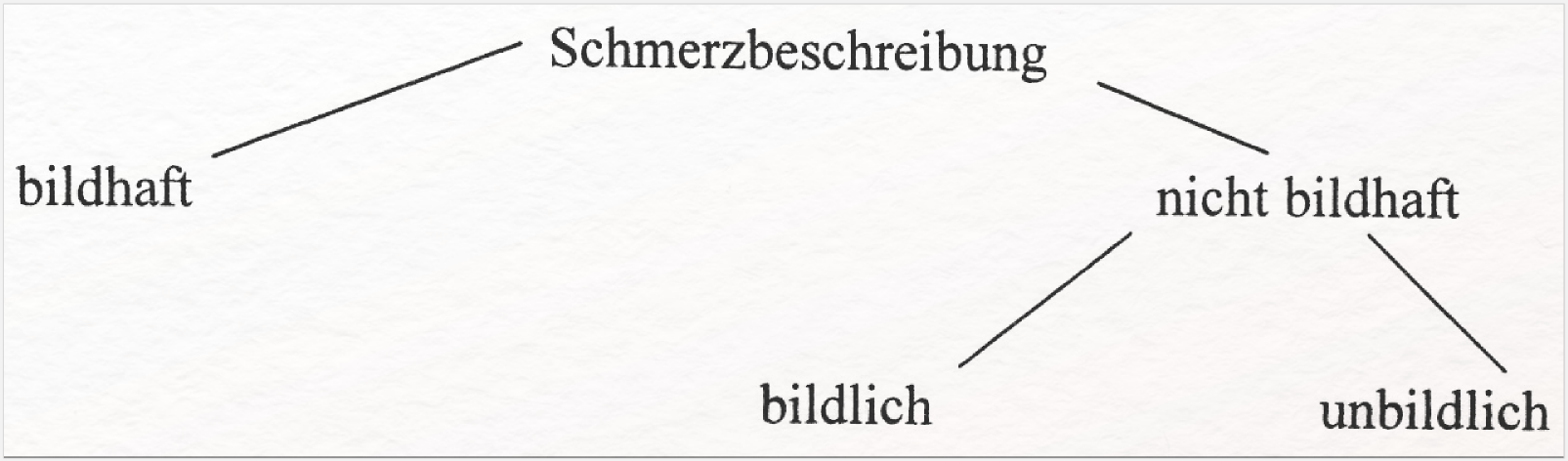
Häufig nutzt die Forschung auch abstrahierende Darstellungen z. B. von Kommunikationsverhältnissen (wie sie besonders in der Erzähltheorie beliebt sind) oder veranschaulichende Visualisierungen von Zusammenhängen struktureller oder kategorialer Merkmale (wie bspw. von bildhafter vs. bildlicher Versprachlichung von Schmerz in literarischen Texten als Baumdiagramm).
Ebenfalls werden in der Forschung Karten oder topografische Repräsentationen von sprachlich erzeugtem Raum bzw. der Bewegung in diesem Raum erstellt und reflektiert – so vergleicht bspw. Ryan (2003) Visualisierungen kognitiver Karten auf Grundlage von García Márquez’ Roman Crónica de una muerte anunciada (1981), und Piatti (2008) mappt in ihrer Monografie – der 17 Karten beiliegen – fiktive Handlungsräume auf tatsächliche Georäume.
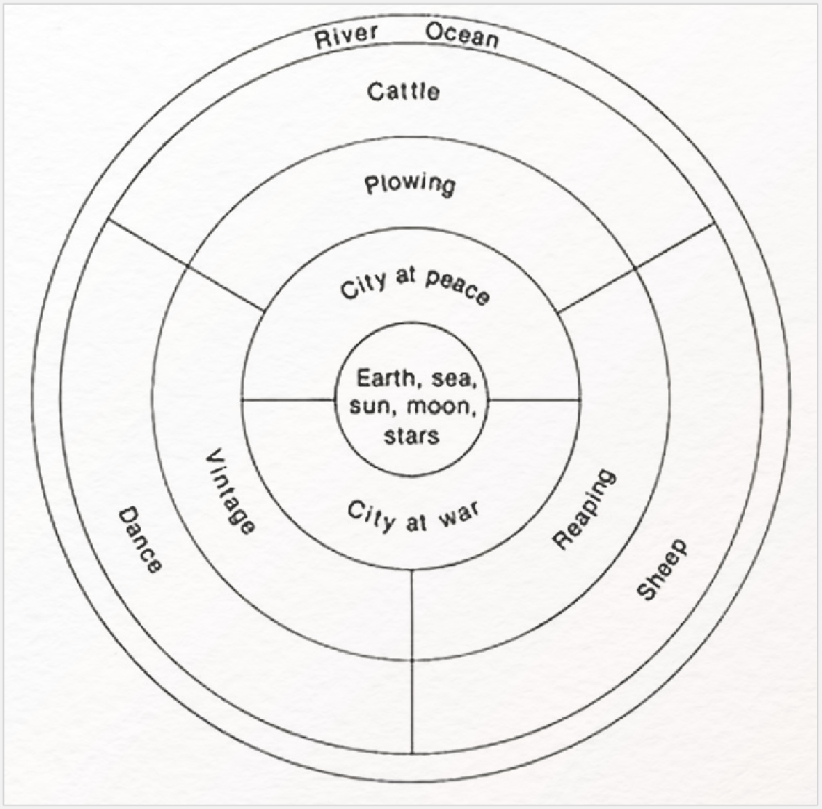
Gelegentlich kommt es zudem vor, dass literarische Ekphrasen in der zugehörigen Forschungsliteratur visualisiert werden, d. h. ursprünglich sprachlich beschriebene Bilder erfahren eine direkte visuelle Umsetzung, gelegentlich auch in abstrahierter Form wie bspw. das Schild des Achilles – eine der ältesten und berühmtesten Ekphrasen überhaupt – bei Willcock (1976, 210):
Es lässt sich in der traditionelleren Literaturwissenschaft eine klare Tendenz hin zu qualitativen Textvisualisierungen ausmachen. In den Digital Humanities sind es vor allem die quantitativen Strukturen von Textdaten, die visualisiert werden. Die digitale Literaturwissenschaft ist momentan daher darum bemüht, Visualisierungsmöglichkeiten zu entwickeln, die qualitative und quantitative Aspekte der Textdaten fruchtbar miteinander verknüpfen (vgl. z. B. das Projekt 3DH), und in diesem Bereich gibt es noch viel Entwicklungspotential.
4. Diskussion
Wenngleich analoge Visualisierungen, wie wir gesehen haben, auf eine längere Tradition zurückblicken, so müssen Textvisualisierungen im Sinne der im ersten Abschnitt angeführten Definition als digitale, textdatengetriebene Visualisierungen als ein relativ junges Phänomen in der Literaturwissenschaft verstanden werden. Da die visuelle Repräsentation quantitativer Textdaten im Analogen einen erheblich größeren Aufwand bedeuten würde, ermöglichen die digitalen Methoden neue Perspektiven.
Der Hauptvorteil, der durch das digitale Medium geschaffen wird, besteht in der direkten Interaktion und der dadurch geschaffenen Möglichkeit der Exploration. Seifert et al. (2014) beschreiben Textvisualisierung als „an effective enabler for exploratory analysis, making it a powerful tool for gaining insight into unexplored data sets.” Darüberhinaus erlaubt Interaktivität flüssige Bewegungen zwischen Übersichtsdarstellungen, der Darstellung von Teilbereichen und Details (vgl. Shneiderman 1996).
Das Setzen von Filtern, das Selektieren von Teilbereichen, das Nebeneinanderstellen dieser verschiedenen Perspektiven auf die Daten ermöglicht es, auf schnelle Art und Weise Vergleiche herzustellen und Schlussfolgerungen zu ziehen (vgl. Card et al. 1999). Die kognitive Belastung beschränkt sich hierbei auf ein Minimum, da die Textvisualisierung (bzw. allgemeiner Informationsvisualisierung) sich die herausragenden Fähigkeiten des visuellen Wahrnehmungssystems des Menschen zunutze macht (vgl. Ware 2012).
Die Vorteile digitaler Textvisualisierung treten dabei nicht nur im Distant Reading hervor, auch wenn dieser Bereich in den vergangenen Jahren eine vermehrte Aufmerksamkeit in der Anwendung von Visualisierungstechniken gefunden hat. Auch die im Zusammenhang mit einem Close Reading digital erstellten Annotationen (→ Manuelle Annotation) sind besonders bei einer hohen Anzahl von Annotationen in ihrem Zusammenhang nicht mehr übersichtlich darzustellen. Textvisualisierung kann hier eingesetzt werden, um eine komprimierte Übersichtsdarstellung zu geben, die nach unterschiedlichen Kriterien strukturiert werden kann.
Typische Anwendungsbereiche von Textvisualisierungen im Distant Reading sind beispielsweise stilometrische Analysen (→ Stilometrie), Häufigkeitsanalysen (von Wörtern, N-Gramms, Annotationen), Darstellungen von Verteilungen von Wörtern oder Annotationen über Textlängen, zeitliches Erscheinen von Werken einer Textsammlung, Netzwerkdiagramme von Figuren, Geovisualisierungen von Ortsnennungen in Texten oder Verteilung von Themen über eine Textsammlung im Topic Modeling. Abbildung 8 zeigt beispielhaft Visualisierungen für diese unterschiedlichen Anwendungsfälle.
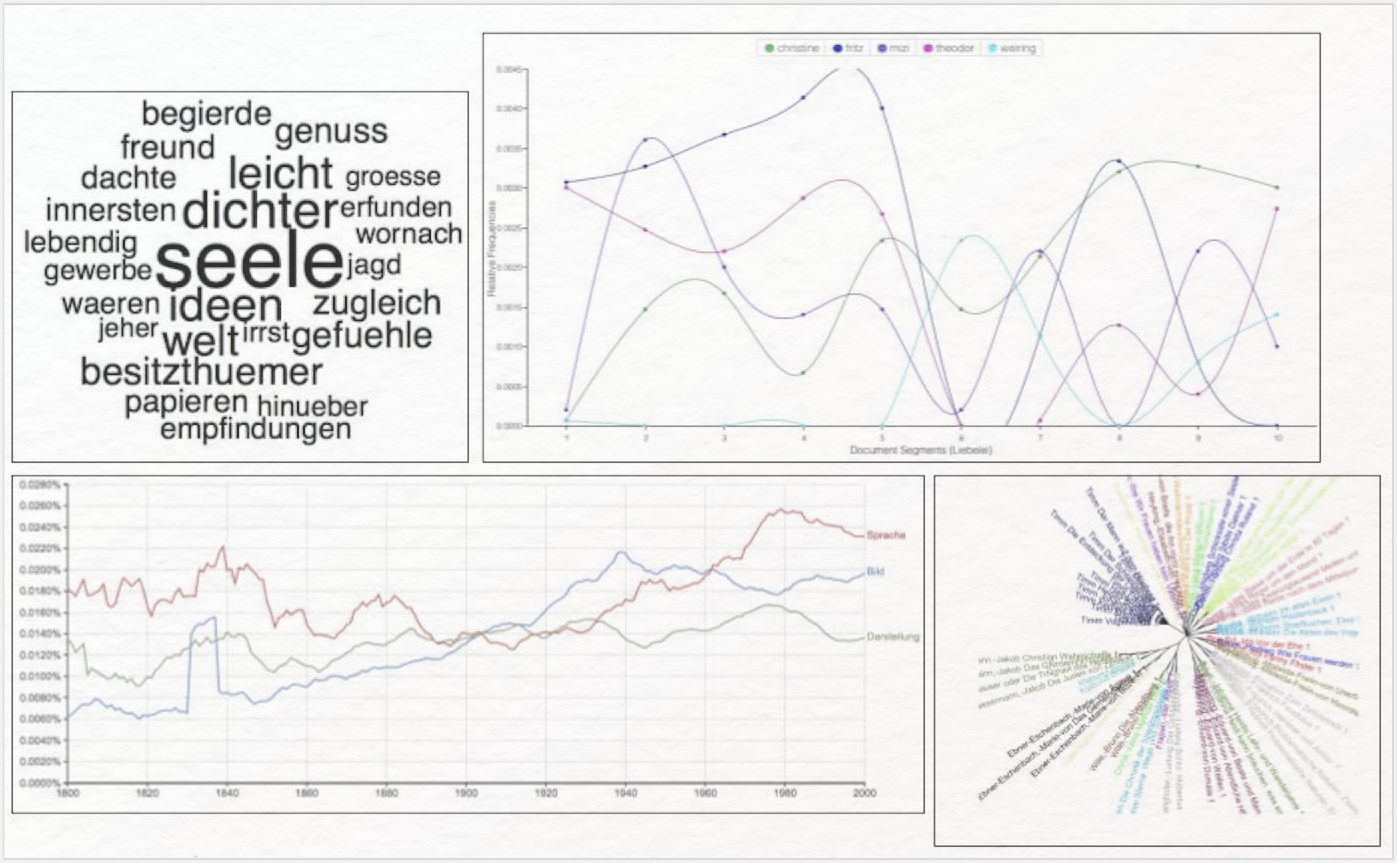
Eine Übersicht über gängige Visualisierungsformen in der digitalen Literaturwissenschaft in den Bereichen Close und Distant Reading geben Jänicke et al. (2015).
Der Einsatz von Visualisierungen in der digitalen Literaturwissenschaft und den Digital Humanities generell wird jedoch auch kritisch betrachtet. Ein häufig geäußerter Einwand bezieht sich auf die visuelle Darstellung von Ergebnissen literaturwissenschaftlicher Arbeit als vermeintlich objektive Fakten. Drucker (2011) schlägt etwa vor, die geisteswissenschaftliche Konstruiertheit („constructedness”) von Daten stärker zu berücksichtigen (in diesem Zusammenhang spricht sie von „capta” statt „data”) und geeignete visuelle Darstellungsformen zu verwenden, die in der Lage sind, typische literaturwissenschaftliche Deutungsdimensionen wie Unsicherheit und Mehrdeutigkeit zu kommunizieren. Zunehmend lässt sich ein Zusammenwachsen des vormaligen Gegensatzpaares quantitativ/qualitativ feststellen. Quantitativ erzeugte Daten werden so etwa durch unterschiedliche Visualisierungen einer kritischen Betrachtungsweise zugänglich, während qualitative Daten in der distanzierten Übersicht dargestellt einen schnellen Zugriff auf die zugrundeliegenden annotierten Textstellen erlauben.
Auch wenn einfach zu benutzende generische Visualisierungstools grundsätzlich zu begrüßen sind, so stellen sie auch eine gewisse Gefahr da. Gerade bei fehlenden Grundlagenkenntnissen im Bereich der Text- bzw. Informationsvisualisierung können Visualisierungen unwissentlich zu einer Verzerrung der produzierten Ergebnisse führen, z. B. durch die Verwendung eines Kuchendiagramms für Prozentwerte, die nicht Teile eines Ganzen darstellen. Außerdem können Farben unglücklich eingesetzt, Datenattribute mit wenig geeigneten visuellen Variablen repräsentiert oder ganz generell Visualisierungsformen verwendet werden, die eine bestimmte Datenstruktur voraussetzen und bei abweichenden Strukturen eine verzerrende Aussage zur Folge haben können.
Insgesamt lässt sich konstatieren, dass das Potential interaktiver Textvisualisierungstools noch nicht ausgeschöpft ist. So wird Textvisualisierung in der Praxis vornehmlich als Repräsentation eines vermeintlichen Endergebnisses eines Forschungsprozesses eingesetzt, während der Prozess selbst, den häufig die Produktion einer Vielzahl von Visualisierungen und deren Interpretation ausmacht, ignoriert wird. Die Stärke von Visualisierungen nicht nur zu kommunizieren, sondern auch Exploration zu ermöglichen und das Entstehen von Schlussfolgerungen zu befördern, wird hier nur im Prozess für die Forschenden sichtbar, nicht jedoch für das spätere Publikum der Forschungsarbeit. Ein vermehrter Einsatz von Visualisierungen auch als wesentlicher Teil der Argumentation steht derzeit noch aus.
5. Technische Grundlagen
Die Bandbreite an Software, mit der sich Textvisualisierungen erzeugen lassen, ist groß. Grundlegend lassen sich generische Tools und Programmiersprachen unterscheiden. Generische Tools bieten unterschiedliche Standardvisualisierungsformen an, für ihre Nutzung sind in der Regel keine tiefergehenden Programmierkenntnisse notwendig. Programmiersprachen hingegen erlauben statistische Auswertungen oder eine sprachliche Analyse von Texten und/oder eine Ausgabe berechneter Daten in unterschiedlichen Visualisierungen.
In ihrer einfachsten Variante erlauben generische Tools eine unmittelbare automatische Analyse und Visualisierung von Texten. Ein solches Beispiel ist die niederschwellige Webapplikation → Voyant, die beispielsweise mithilfe von Word Clouds Worthäufigkeiten visualisiert oder Verteilungen von Wörtern über den Gesamttext als Liniendiagramme darstellt. Manuell erstellte Annotationen in digitalen Texten lassen sich mit Tools wie → CATMA analysieren und auf verschiedene Weisen visualisieren.
Einige Programmiersprachen haben sich für die Textanalyse und -visualisierung in der Praxis besonders bewährt. Mit R lassen sich beispielsweise Topic Models generieren (→ Topic Modeling) und in Form von Word Clouds visualisieren. Python ist besonders für die Textanalyse im Bereich Natural Language Processing geeignet und erlaubt mit entsprechenden Bibliotheken auch eine Visualisierung der erzeugten Daten.
Mit der Javascript-Bibliothek D3 lassen sich unterschiedlichste Datensätze (nicht nur Textdaten) in vorgefertigten Visualisierungen darstellen, aber auch vollkommen neue Visualisierungen erstellen. Die Anwendung aller dieser Sprachen erfordert Programmierkenntnisse im Allgemeinen und grundlegende bis fortgeschrittene Kenntnisse der jeweiligen Sprache im Speziellen.
Für eine Vielzahl dieser Tools existiert im Web eine umfangreiche Sammlung an Tutorials und Dokumentationen, die als Lernmaterial genutzt werden können. Weiterführende Literatur und Links finden Sie unten (Abschnitt 7).
Für einen adäquaten Einsatz von Visualisierungstools ist die Kenntnis einiger Grundprinzipien der Textvisualisierung entscheidend. Zunächst sollten Sie sich fragen, was für Daten Sie repräsentieren möchten. Abhängig davon, was Sie an einem Text oder einer Textsammlung analysieren möchten, arbeiten Sie mit unterschiedlichen Datensätzen (siehe Abschnitt 1). Normalerweise besteht ein Datensatz aus einzelnen Entitäten (in der Regel Zeilen in der Datentabelle), die sich wiederum aus einzelnen Datenattributen zusammensetzen. Menge und Art der Attribute haben Einfluss auf die Visualisierungstypen, die für Ihre Visualisierung in Betracht kommen.
Man unterscheidet drei grundlegende Datenattribute: Quantitativ, kategorisch (auch: nominal) und ordinal. Unter quantitativen Daten versteht man numerische Daten, mit denen Berechnungen angestellt werden können, wie beispielsweise die Häufigkeit von Wörtern in einem Text. Geografische oder zeitliche Daten können als Sonderform quantitativer Daten betrachtet werden, die gewissen formalen Beschränkungen unterliegt. Im Gegensatz dazu spricht man von kategorischen Daten, wenn diese nicht-numerisch sind und voneinander unabhängige Werte darstellen. Ein Beispiel hierfür sind etwa die unterschiedlichen Namen der Figuren in einem Text. Ordinale Daten ähneln kategorischen Daten, unterscheiden sich aber durch die in Ihnen zum Ausdruck kommende Reihenfolge. Eine Bewertung wie „klein, mittel, groß” fällt beispielsweise unter diese Bezeichnung.
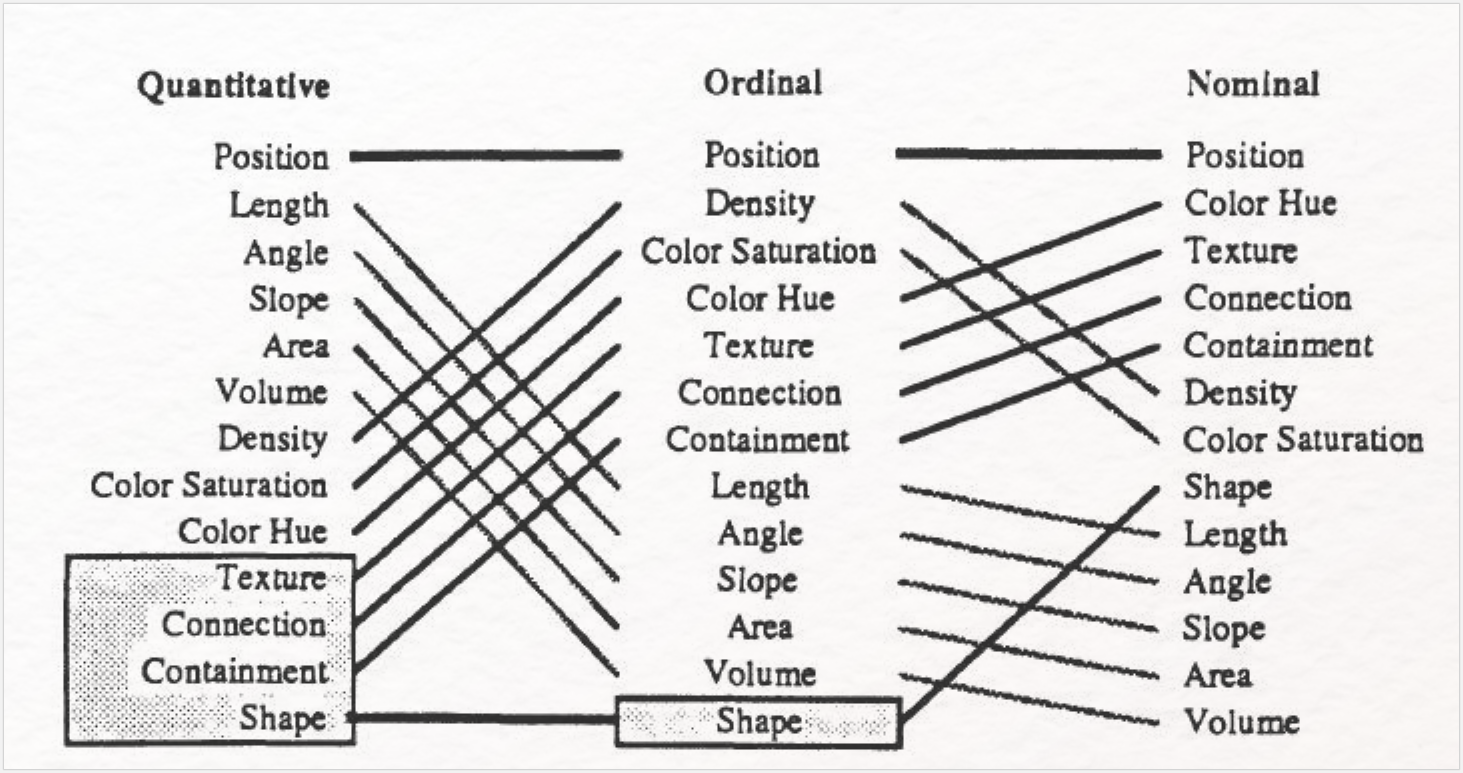
Die bei den jeweiligen Datenattributen auftretenden Werte können zudem Relationen untereinander haben, die ebenfalls im Datensatz kodiert sein können. Um diese unterschiedlichen Datenattribute zu repräsentieren, stehen verschiedene sogenannte „Visuelle Variablen” (Bertin 1974) zur Verfügung, von denen die wichtigsten in Abbildung 9 aufgeführt sind.
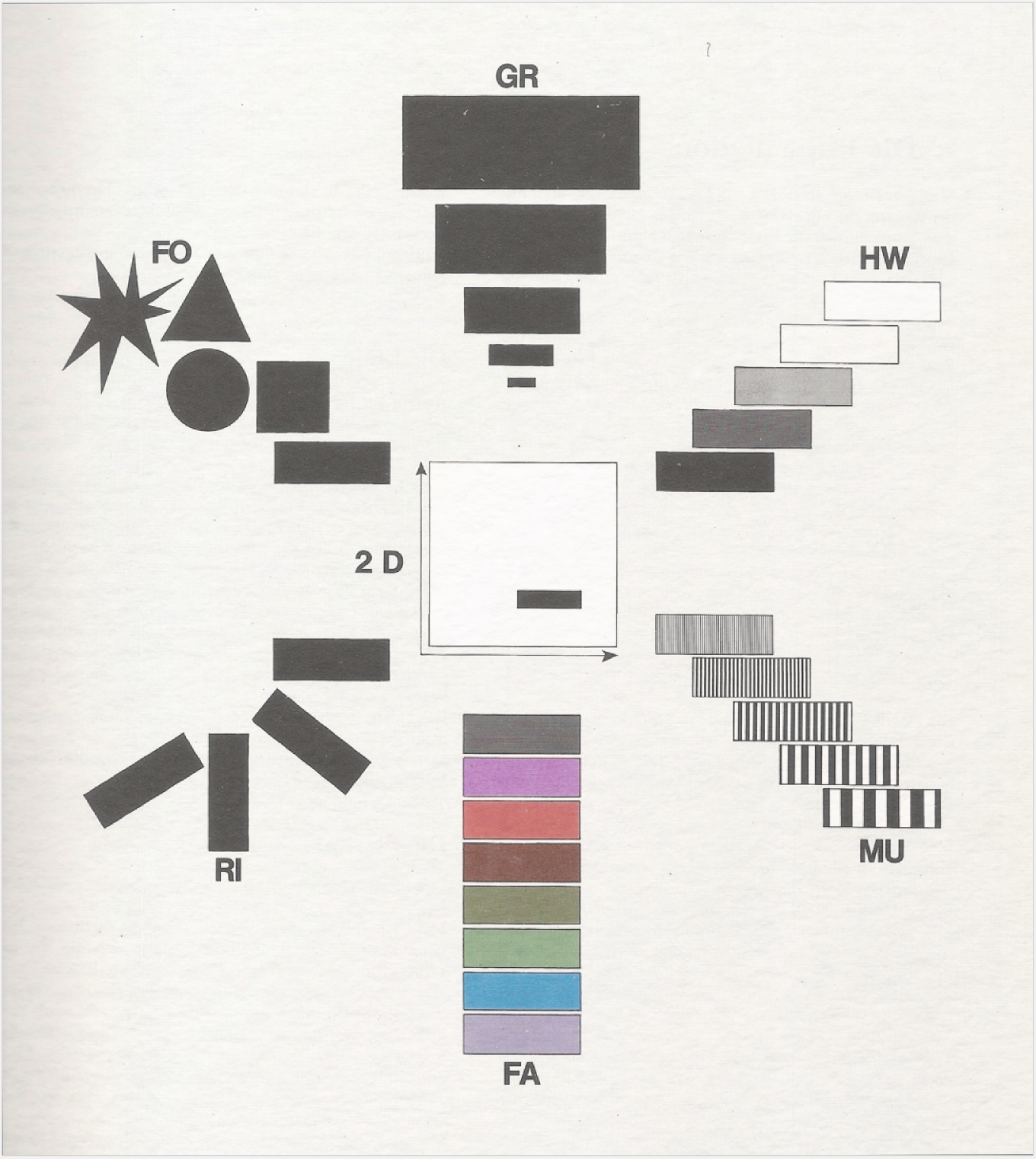
Im einzelnen sind dies: Form, Größe, Helligkeitswert, Muster, Farbe, Richtung und Position. Um visuelle Variablen und Gestaltgesetze sinnvoll anwenden zu können, sind einige Regeln zu beachten. Je nach Datenattribut sind visuelle Variablen unterschiedlich gut geeignet, um Datenwerte zu repräsentieren: Während sich z. B. die visuelle Variable Farbe besonders eignet, um kategorische Werte darzustellen, so ist sie nicht geeignet, um quantitative Werte zu kodieren. In der untenstehenden Tabelle ist eine Übersicht über sinnvolle Kodierungen als visuelle Variablen der einzelnen Datenattribute in Spalten abgebildet (mit von oben nach unten abnehmender Eignung). Die genannten visuellen Variablen wurden durch weitere ergänzt, die in Spezialfällen zur Anwendung kommen können. Im Normalfall ist die oben dargestellte Auswahl von sieben Variablen ausreichend.
Visualisierungen, die Relationen darstellen, wie beispielsweise Netzwerke oder Hierarchien, orientieren sich an den sog. Gestaltgesetzen. Für die Textvisualisierung sind hier besonders die Gesetze Nähe, Ähnlichkeit, Verbundenheit und Gemeinsame Regionen wichtig:

Auch im Bereich der Interaktion haben sich im Laufe der Zeit einige Techniken etabliert, deren Eignung sich in der Praxis besonders bewährt hat. Normalerweise gestatten generische Tools nur sehr eingeschränkt eine Beeinflussung der Interaktionen, die mit einer Textvisualisierung möglich sind. Auch in R und Python findet die Interaktion eher auf Code-Ebene statt. Die Gestaltung und Programmierung eines vollständigen User-Interfaces, bei dem die Interaktionen frei zu bestimmen sind, kann in der Regel nur unter Beteiligung von Programmierern und Designern mit Webtechnologien wie HTML/CSS und Javascript umgesetzt werden. Dennoch sollen die wichtigsten wissenschaftlichen Erkenntnisse kurz vorgestellt werden.
Ein Prinzip, das sich in der Praxis immer wieder bewährt hat, ist das sogenannte Shneiderman’s Visual Information Seeking Mantra: „Overview first, zoom and filter, then details-on-demand” (Shneiderman 1996). Visualisierungen sollten zunächst einen Überblick über die Daten vermitteln, durch Interaktionen wie Zoomen und Filtern die Auswahl eines Teilbereiches erlauben und schließlich Detailinformationen für einzelne Datenpunkte bei Bedarf anzeigen (z. B. durch einen Mausklick).
Ein weiteres Prinzip ist das Semantic Zooming. Hierbei handelt es sich um eine hilfreiche Strukturierung zoombarer Interfaces, wie sie z. B. von Google Maps eingesetzt werden: Mit jeder Zoomstufe, die man weiter hineinzoomt, werden mehr Details auf der Karte angezeigt. Auf diese Weise lässt sich vermeiden, dass sich eine Vielzahl von visuellen Elementen oder Beschriftungen überlagert, die auf einer bestimmten Zoomstufe noch gar nicht relevant ist.
Bei mehreren Visualisierungen, die durch die Daten miteinander in Verbindung stehen, bietet sich schließlich Brushing+Linking als Prinzip an, um die Verbindung auch visuell deutlich zu machen. Mit Brushing wird die Auswahl eines Teilbereichs der Daten einer Visualisierung bezeichnet, mit Linking die Hervorhebung dieser Daten in anderen verknüpften Visualisierungen, die den gleichen Datensatz mit einer anderen Perspektive repräsentieren (z. B. andere Datendimensionen oder ein gänzlich anderer Visualisierungstyp).
Eine Vielzahl von Websites und Infografiken geben grundlegende Hilfestellung zur Auswahl geeigneter Visualisierungen. Durch Eingabe von Informationen zu Ihrem Datensatz (oder das Verfolgen von Pfaden in einer Baumstruktur) schränken Sie die Zahl in Frage kommender Visualisierungen schrittweise ein. In Abschnitt 7 sind hierzu einige Links aufgeführt.
6. Nachweise
- Adler, Jeremy und Ulrich Ernst (1987): Text als Figur. Visuelle Poesie von der Antike bis zur Moderne. Weinheim: Acta humaniora, VCH.
- Bertin, Jacques (1974): Graphische Semiologie: Diagramme, Netze, Karten. Berlin: de Gruyter.
- Card, Stuart K., Jock Mackinlay und Ben Shneiderman (1999): Readings in information visualization: Using vision to think. San Francisco: Kaufmann.
- Drucker, Johanna (2011): „Humanities Approaches to Graphical Display“. In: Digital Humanities Quarterly. 5 (1).
- Eder, Jens (2007): „Figurenkonstellation“. In: Dieter Burdorf; Christoph Fasbender und Burkhard Moenninghoff (Hrsg.): Metzler Lexikon Literatur. Begriffe und Definitionen. Stuttgart, Weimar: Metzler, 239.
- Goethes Werke (1887–1919). Weimarer Ausgabe (WA), hrsg. im Auftrage der Großherzogin Sophie von Sachsen. Abteilung II, Band 5 (2): Paralipomena zu Band 1–5. Register zu Band 1–5.
- Heusler, Andreas (1955): Nibelungensage und Nibelungenlied. Die Stoffgeschichte des deutschen Heldenepos. Dortmund: Ruhfus.
- Jänicke, Stefan, Greta Franzini, Muhammad Faisal Cheema und Gerik Scheuermann (2015): „On close and distant reading in digital humanities: A survey and future challenges“. In: Eurographics Conference on Visualization (EuroVis) - STARs, The Eurographics Association.
- Kammer, Stephan (2014): „Visualität und Materialität der Literatur“. In: Benthien, Claudia und Brigitte Weingart (Hrsg.) Handbuch Literatur & Visuelle Kultur. Berlin, Boston: de Gruyter, 31–47.
- Koller, Erwin (2000): „Unbildliche, bildliche und bildhafte Versprachlichung von Schmerz (bei A. Döblin, R. Musil, Th. Mann und M. Walser)“. In: Ulla Fix und Hans Wellmann (Hrsg.): Bild im Text - Text und Bild. Heidelberg: Winter, 129–153.
- Mackinlay, Jock (1986): „Automating the design of graphical presentations of relational information“. In: ACM Transactions on Graphics. 5 (2), 110–141.
- Mellmann, Katja (2007): „Versanalyse“. In: Handbuch Literaturwissenschaft, Bd. 2: Methoden und Theorien. Stuttgart, Weimar: Metzler, 81–97.
- Piatti, Barbara (2008): Die Geografie der Literatur. Schauplätze, Handlungsräume, Raumphantasien. Göttingen: Wallstein.
- Ryan, Marie-Laure (2003): „Cognitive Maps and the Construction of Narrative Space“. In: David Herman (Hrsg.): Narrative Theory and the Cognitive Sciences. Stanford: CSLI Publications, 214–242.
- Schmid, Wolf (2007): „Textadressat“. In: Thomas Anz (Hrsg.): Handbuch Literaturwissenschaft, Bd. 1: Gegenstände und Grundbegriffe. Weimar: Metzler, 171–181.
- Seifert, Christin, Vedran Sabol, Wolfgang Kienreich, Elisabeth Lex und Michael Granitzer (2014): „Visual analysis and knowledge discovery for text“. In: Large-Scale Data Analystics. New York: Springer, 189–218.
- Shneiderman, Ben (1996): „The eyes have it: A task by data type taxonomy for information visualizations“. In: Proceedings 1996 IEEE Symposium on Visual Languages, 336–343.
- Ware, Colin (2012): Information Visualization: Perception for Design. 3. Aufl. Waltham: Elsevier.
- Wertheimer, Max (1923): „Untersuchungen zur Lehre von der Gestalt. II“. In: Psychologische Forschung. 4 (1), 301–350.
- Willcock, Malcolm M. (1976): A Companion to the Iliad: Based on the Translation by Richmond Lattimore. Chicago, London: The University of Chicago Press.
7. Weiterführende Literatur und Ressourcen
Generische Visualisierungstools
Text
- Voyant: https://voyant-tools.org/ (vgl. → Voyant)
- CATMA: http://catma.de/ (vgl. → CATMA)
- Prism: https://www.graphpad.com/features
Allgemein (für aus Texten generierte Daten)
- Data Wrapper: datawrapper.de
- Plot.ly: plot.ly
- RAW: rawgraphs.io
R: The R project for Statistical Computing
- Webseite: https://www.r-project.org/
- Tutorials und Einführungen
- A gentle Introduction to Text Mining Using R: https://eight2late.wordpress.com/2015/05/27/a-gentle-introduction-to-text-mining-using-r/
- Introduction to Text Analysis and Topic Modeling with R: http://www.matthewjockers.net/materials/dh-2014-introduction-to-text-analysis-and-topic-modeling-with-r/
Python
- Webseite: https://www.python.org/
- Natural Language Toolkit: http://www.nltk.org/
- Tutorials und Einführungen
- Python Programming for the Humanities: http://www.karsdorp.io/python-course/
- Natural Language Processing with Python (Buch): http://www.nltk.org/book/
- Text Analysis with Topic Models: https://de.dariah.eu/text-analysis-with-topic-models
D3 (fortgeschrittene Programmierkenntnisse notwendig)
- Webseite: https://d3js.org/
- Tutorials und Einführungen
- Überblick und kurze Einführung: https://d3js.org/#introduction
- Sammlung von Tutorials: https://github.com/d3/d3/wiki/Tutorials
Textvisualisierung und Visualisierung im Allgemeinen
Die im Folgenden aufgeführten Webseiten und Grafiken leisten Hilfestellung bei der Wahl geeigneter Visualisierungen für unterschiedliche Datensätze
- Principles of Information Visualization: http://www.themacroscope.org/?page_id=469
- Data and Design Handbook: https://trinachi.github.io/data-design-builds/copyright-page01.html
- Data Viz Project: https://datavizproject.com/
Chart Chooser Diagram: https://www.labnol.org/software/find-right-chart-type-for-your-data/6523/
