1. Kurzbeschreibung
Das DWDS ist ein digitales Lexikon, das Ihnen die freie Suche nach Begriffen der deutschen Sprache und ihrer historischen und gegenwärtigen Bedeutung ermöglicht. Sie können bestimmen, in welchen der großen Textsammlungen (z. B. DWDS-Kernkorpora des 19., 20. oder 21. Jahrhunderts, Zeitungs-, Blog-, Webkorpora etc.) und welcher Textsorte (Belletristik, Wissenschaft, Gebrauchsliteratur oder Zeitungen) gesucht werden soll.
Steckbrief
- https://www.dwds.de
- Projekt der Berlin-Brandenburgischen Akademie der Wissenschaften zur Erstellung eines digitalen allgemein zugänglichen Wörterbuchsystems mit derzeit 13. 521. 774 .869 Tokens
- Referenzkorpora zum 19. (→ Deutsches Textarchiv (DTA)), 20. und 21. Jahrhundert: Das Kernkorpus zum 20. Jahrhundert (über 121 Millionen Tokens) ist über das gesamte Jahrhundert gestreut und nach Textsorten ausgewogen: Belletristik (28,42 %), Zeitung (27,36 %), wissenschaftliche Fachtexte (23,15 %) und Gebrauchstexte (21,05 %); das Kernkorpus zum 21. Jahrhundert (derzeit gut 15 Millionen Tokens) wird laufend erweitert, ist noch nicht ausgewogen, jedoch ebenfalls zeitlich und nach Textsorten differenziert
- verknüpfte lexikalische Informationstypen: Artikel des Wörterbuchs der deutschen Gegenwartssprache (WDG) inkl. automatisch generierter Informationen zu Synonymen, Hyponymen und Hyperonymen, Textbeispiele aus den DWDS-Kernkorpora und statistische Kookkurrenz-Informationen
- mehr als 10.000 registrierte Benutzer*innen (einige Korpora benötigen zur Recherche eine kostenfreie Registrierung)
- Wörterbücher: Wörterbuch der deutschen Gegenwartssprache (WDG), DWDS-Wörterbuch, Etymologisches Wörterbuch des Deutschen, Deutsches Wörterbuch von Jacob Grimm und Wilhelm Grimm (DWB), Das Große Wörterbuch der deutschen Sprache in 10 Bänden (Duden 1999), OpenThesaurus
- Zeitungskorpora: BILD (1996–2018), Berliner Zeitung (1945–2005), Frankfurter Rundschau (1997–2000), neues deutschland (1946–1990), NZZ (1970–2018), SPIEGEL (1947–2014), Der Standard (2000–2016), Süddeutsche Zeitung (1992–2017), Tagesspiegel (1996–2005), taz (1986–1999), Welt (1997–2018), Die ZEIT (1946–2018)
- Spezialkorpora: Blogs, Webkorpus (Auswahl von Webseiten auf Deutsch), Dortmunder Chat-Korpus, Filmuntertitel, Polytechnisches Journal, DDR (1100 Texte von 1949–1990), Gesprochene Sprache (Transkripte von Reden, Parlamentsprotokollen, Interviws des 20. Jhs.), Text+Berg (Jahrbuch Schweizer-Alpenclub), Berliner Wendekorpus (77 Interviews mit Ost- und Westberliner*innen)
2. Anwendungsbeispiel
Sie vergleichen drei literarische Werke aus dem 19., 20. und 21. Jahrhundert in gendertheoretischer Perspektive und begegnen dabei unterschiedlichen Verwendungen des Begriffs „Geschlecht”. Eine Recherche im DWDS bietet Ihnen die diversen Bedeutungen des Begriffes, seine Etymologie, Verknüpfungen mit einem Thesaurus, ein Wortprofil mit einer interaktiven Wordcloud, automatisch generierte Beispiele aus den DWDS-Korpora wie „Aber jeder von uns besitzt alle nötigen Gene für beide Geschlechter” aus der Süddeutschen Zeitung am 07. November 2003 (https://www.dwds.de/wb/Geschlecht, Zugriff: 07. Mai 2019), Angaben über die Worthäufigkeit, eine Wortverlaufskurve (die ihren Höhepunkt um 1800 hat), Zugriffsmöglichkeiten auf die älteren Wörterbücher DWB und WDG sowie Angaben über Trefferquoten in den einzelnen Korpora des DWDS (sodass Sie bei literaturwissenschaftlichem Interesse auch noch in die Referenzkorpora zu den einzelnen Jahrhunderten schauen können).
3. Diskussion
3.1 Kann ich Textsammlung x für wissenschaftliche Arbeiten nutzen?
Ja. Das DWDS ist bibliographisch referenzierbar und bei der Textauswahl und Aufbereitung wurde und wird auf inhaltliche und qualitative Streuung geachtet, sodass der deutsche Wortschatz von 1600 bis in die Gegenwart repräsentativ dargestellt wird. Zur Recherche von Volltexten bietet sich das DWDS jedoch nicht an. Stattdessen ermöglicht es dezidiert, Wörter in ihren Gebrauchskontexten zu erforschen. Volltexte finden Sie für das Referenzkorpus des 19. Jahrhunderts auf der Webseite des → Deutschen Textarchivs (DTA). Für das 20. und 21. Jahrhundert können Volltexte aufgrund des Urheberrechts i. d. R. noch nicht angeboten werden, das DWDS stellt in dieser Hinsicht keine Ausnahme dar. Die Metadaten der hinterlegten Dokumente sind auf sehr hohem Niveau (die Redaktion achtet auf Vollständigkeit und Einheitlichkeit) und die mit dem DWDS gefundenen Belege können unter Beachtung der Nutzungsbedingungen frei weiterverwendet werden. Zudem bietet das DWDS eine Zitationshilfe an.
3.2 Wie benutzerfreundlich ist die Arbeit mit Textsammlung x?
Das DWDS kann in den meisten Bereichen intuitiv bedient werden und die Webseite ist übersichtlich gestaltet. Etliche Korpora können ohne vorherige Registrierung kostenfrei durchsucht werden und vor allem die Visualisierung von bis zu vier Begriffen als Verlaufskurven (siehe Abb. 2) stellt ein hilfreiches Tool zur Herstellung von Übersichten dar.
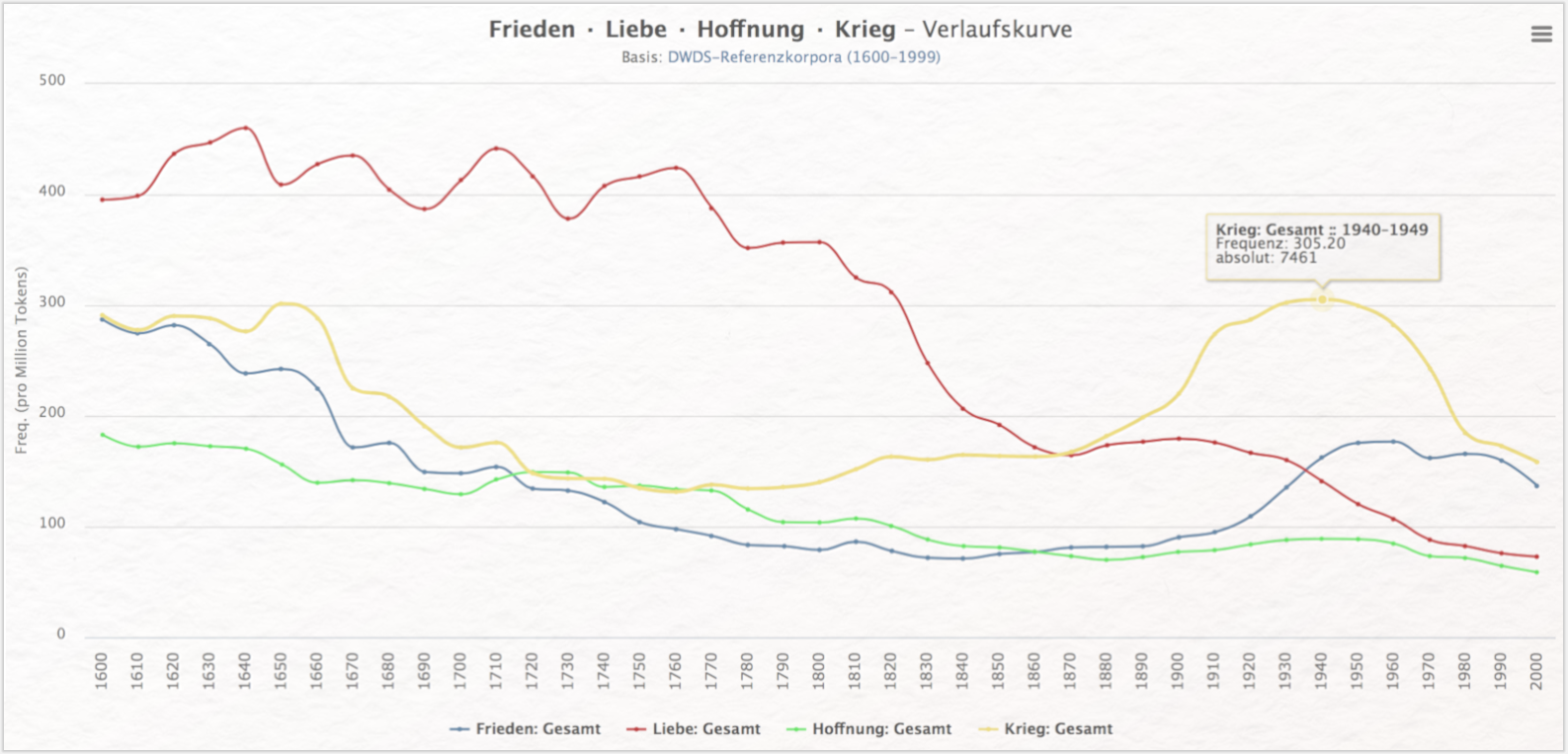
Diese in unterschiedlichen Formaten exportierbaren Verlaufskurven bieten nicht nur einen synoptischen Überblick, sondern können auch interaktiv exploriert werden. Die Diagramme lassen sich zudem mit einem Klick dahingehend ausdifferenzieren, dass die einzelnen Textsorten zu den ausgewählten Begriffen getrennt voneinander visualisiert werden (siehe Abb. 3).
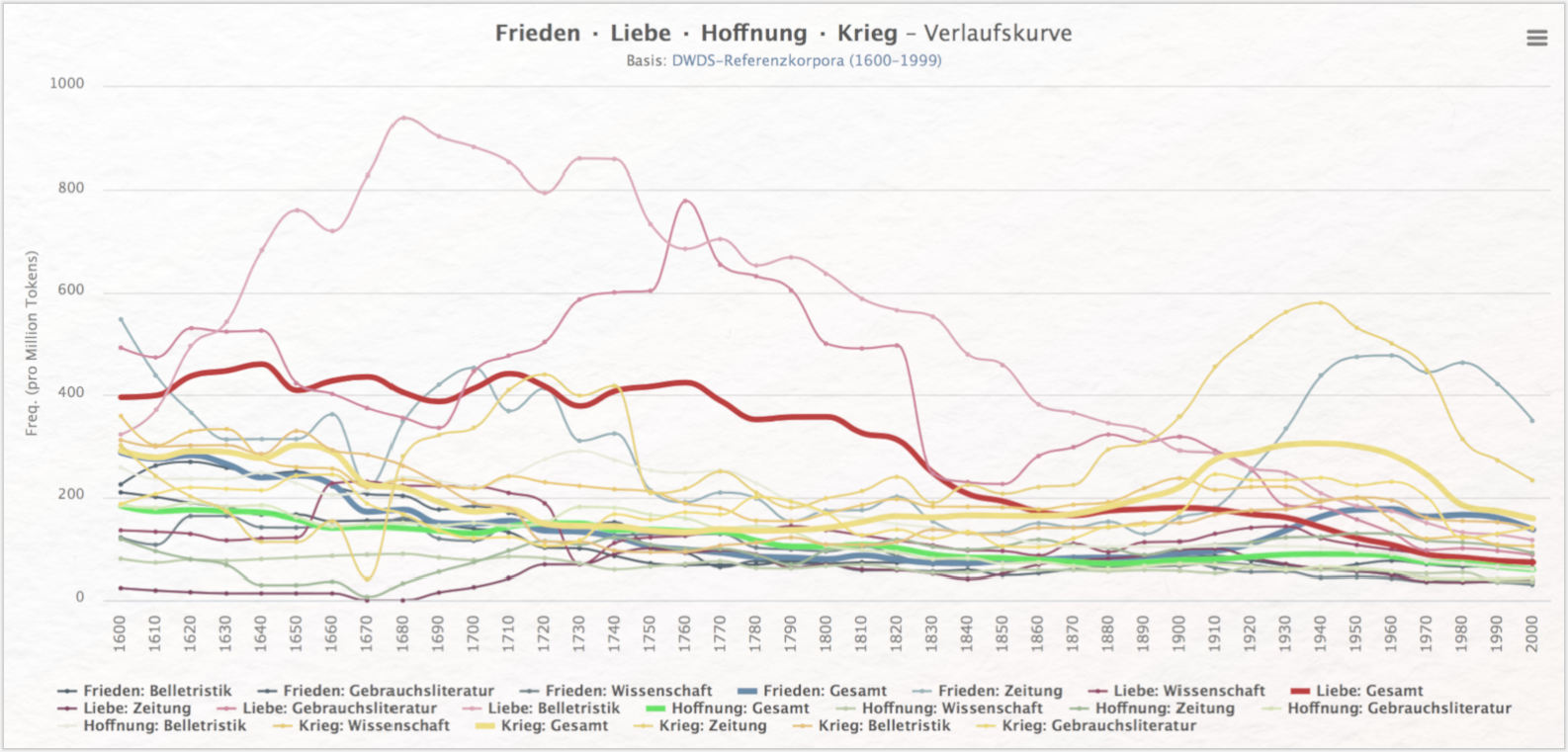
Insbesondere der große Funktionsumfang der Suchoptionen bedarf jedoch einer genaueren Einarbeitung; eine kompakt gestaltete Überblicksseite ermöglicht Ihnen hierbei den Einstieg in die Grammatik der Suchabfragen. Einige Korpora des DWDS können aufgrund von Nutzungsvereinbarungen mit den Rechtegebern lediglich mit vorheriger Registrierung – dann jedoch ebenfalls kostenfrei – genutzt werden.
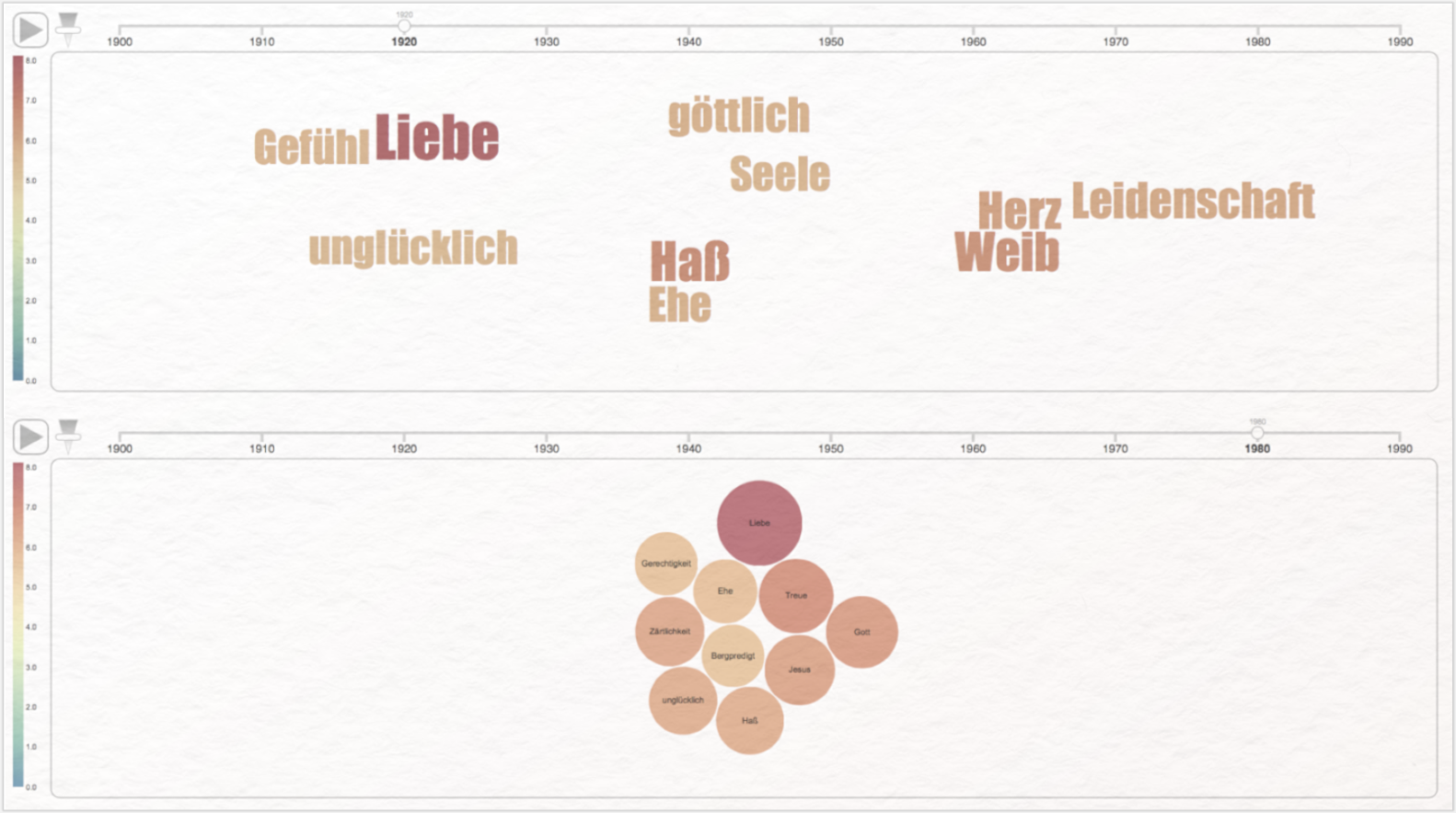
Das mit beinahe allen Korpora im DWDS verknüpfte, von der Forschungsinfrastruktur CLARIN-D entwickelte Analysetool DiaCollo zur diachronen Kollokationsanalyse ermittelt typische Wortverbindungen nach deren zeitlichem Auftreten. Der ausgewählte Begriff wird auf Grundlage des jeweils bestimmten Korpus zusammen mit anderen in seinem Umfeld häufig vorkommenden Begriffen bspw. als animierte Wordcloud oder animierte Bubble-Visualisierung dargestellt (siehe Abb. 4). Wie das etwa mit dem Begriff „Liebe” im Verlauf des 20. Jahrhunderts aussieht, können Sie hier verfolgen.
4. Wie funktioniert die Textsuche in Textsammlung x?
Die Begriffssuche im DWDS funktioniert denkbar einfach: Bereits auf der Startseite haben Sie ein großes Sucheingabefeld, in das Sie Ihren Begriff eintippen können. Bereits während Sie tippen, werden Ihnen aus den Korpora des DWDS automatisch Vervollständigungen angeboten, wie Sie das auch von der Arbeit mit größeren onlinebasierten Suchmaschinen kennen. Sie können Ihren Begriff nun entweder vollständig eingeben (Groß- oder Kleinschreibung spielt hierbei keine Rolle) und dann die Suche starten (per Klick auf das Lupensymbol oder die Enter-Taste), oder Sie wählen einen der vorgeschlagenen Begriffe per Mausklick aus. Anschließend gelangen Sie zur Übersichtsseite des jeweiligen Begriffes mit allen oben im Abschnitt Anwendungsbereich beschriebenen Kategorien.
Auf dieser Ergebnisseite sehen Sie in der rechten Spalte außerdem die sog. Korpustreffer. Klicken Sie hier auf das von Ihnen präferierte Korpus, gelangen Sie zu den einzelnen Vorkommnissen des gesuchten Begriffes im ausgewählten Korpus. Dort finden Sie außerdem eine differenzierte Suchmaske, um einzelne Korpora, Textsorten und genauer definierte Zeitabschnitte zu durchsuchen. Die Korpussuche bietet Ihnen zudem die Möglichkeit, Suchergebnisse in unterschiedlichen Ansichten darzustellen.
Wie im → Deutschen Textarchiv (DTA) ist es im gesamten DWDS möglich, die Suchabfragesprache der korpuslinguistischen Suchmaschine DDC zu verwenden, mithilfe derer komplexe Suchanfragen bspw. nach Wortgruppen, Phrasen, Lemmata, Satzanfängen etc. vorgenommen werden können.
5. Nachweise und weiterführende Literatur
- Barbaresi, Adrien (2016): „Efficient construction of metadata-enhanced web corpora“. In: Proceedings of the 10th Web as Corpus Workshop, Berlin: Association for Computational Linguistics, 7–16. URL: https://www.aclweb.org/anthology/W16-2602.
- Barbaresi, Adrien und Kay-Michael Würzner (2014): „For a fistful of blogs: Discovery and comparative benchmarking of republishable German content“. In: Proceedings of NLP4CMC workshop (KONVENS 2014), Hildesheim University Press, 2–10.
- Geyken, Alexander (2014): „Methoden bei der Wörterbuchplanung in Zeiten der Internetlexikographie“. In: Lexicographica. 30 (1), 77–111.
- Herold, Axel (2011): „Retrodigitalisierung und Modellierung des Wörterbuchs der deutschen Gegenwartssprache“. In: Andreas Kraft und Carmen Spiegel (Hrsg.): Sprachliche Förderung und Weiterbildung – transdisziplinär. Frankfurt am Main: Peter Lang.
- Klappenbach, Ruth und Helene Malige-Klappenbach (1980): „Das Wörterbuch der deutschen Gegenwartssprache. Entstehung, Werdegang, Vollendung“. In: Werner Abraham und Jan F. Brand (Hrsg.): Studien zur modernen deutschen Lexikographie. Auswahl aus den lexikographischen Arbeiten. Erweitert um drei Beiträge von Helene Malige-Klappenbach. Amsterdam: Benjamins, 3–58.
- Klein, Wolfgang und Alexander Geyken (2010): „Das Digitale Wörterbuch der Deutschen Sprache DWDS“. In: Lexicographica. 26, 79–96.
- Schmidt, Thomas, Alexander Geyken und Angelika Storrer (2008): „Refining and Exploiting the Structural Markup of the eWDG“. In: Proceedings of the XIII EURALEX International Congress, Barcelona, Spain, 469–481.
- Verzeichnis der DWDS-Publikationen: https://www.dwds.de/d/publikationen.
