1. Definition
Die oft synonym verwendeten Begriffe Sentimentanalyse, Stimmungsanalyse oder -erkennung und Opinion Mining bezeichnen einen Teilbereich des Fachgebiets „Information Retrieval” (u. a. Teilbereich der Computerlinguistik und Informatik), in dem die gezielte Suche nach Informationen aus großen Textmengen im Fokus steht. Wie der Begriff Sentiment (aus dem Franz. le sentiment für Gefühl, Stimmung) bereits verrät, handelt es sich bei der Sentimentanalyse um die automatisierte Analyse von in Texten dargestellten menschlichen Gefühlen, Empfindungen und/oder Meinungen, die verbalisiert und dadurch nach außen getragen werden. In diversen Anwendungen geht es v. a. darum, durch eine Sentimentanalyse ein Stimmungsbild zu erzeugen und die im Text manifestierten Meinungen und Gefühle herauszufiltern.
Die Sentimentanalyse ist – oft als kommerzielle Dienstleistung – fester Bestandteil diverser Kommunikationsunternehmen und gehört zum Methodenkanon der Sozialwissenschaften. Die Anwendungen betreffen u. a. die automatisierte Extraktion der in sozialen Netzwerken vermittelten Gefühlslagen, die Überwachung von Internet-Foren sowie die Erkennung von negativen Äußerungen (Flaming) und deren Entfernung oder die Analyse von Kundenfeedback und Online Reviews zur Produktverbesserung (vgl. Ortner 2014; Liu 2015). Neben die analytische Funktion der Stimmungsanalyse tritt eine prognostische: Sentimentanalysen werden ebenfalls eingesetzt, um Hypothesen über mögliche zukünftige menschliche Reaktionen – z. B. auf ein Produkt oder zu einem bestimmten Thema – anstellen zu können (vgl. Liu 2015, 3). Als spezifische Methode der Textanalyse ist die Sentimentanalyse in ein interdisziplinäres Forschungsfeld eingebettet, und übernimmt Techniken aus den Bereichen Natural Language Processing und Data- bzw. Web-Mining (vgl. Zhang und Liu 2014).
2. Anwendungsbeispiel
Literaturwissenschaftliche Fragestellungen, die sich durch eine Sentimentanalyse beantworten ließen, können auf der Makro- wie auch der Mikroebene von Texten ansetzen. Auf Korpusebene kann z. B. untersucht werden, ob Jean Pauls Werke in der literaturkritischen Berichterstattung des 18. Jahrhunderts eher positiv oder eher negativ bewertet wurden. Wenn Sie ein einzelnes Dokument untersuchen möchten, kann auf einer übergeordneten Dokumentebene z. B. nach den Stimmungen gefragt werden, die den Handlungsverlauf in Arthur Schnitzlers Der grüne Kakadu begleiten. Es können aber auch noch kleinere Einheiten betrachtet werden, indem auf der Satzebene z. B. analysiert wird, ob es sich bei Karl Moor aus Friedrich Schillers Drama Die Räuber um eine Figur handelt, die mit eher positiven oder negativen Sentiments in Verbindung steht. Die prognostische Funktion der Sentimentanalyse kann bspw. auf die Vorhersage eines glücklichen bzw. unglücklichen Endes von Erzählungen (vgl. Zehe et al. 2016) oder auf Genreklassifikationen abzielen (vgl. Kim, Padó und Klinger 2017).
3. Literaturwissenschaftliche Tradition
Die Sentimentanalyse steht in der Tradition psychoanalytischer, linguistischer, sozial- und kulturwissenschaftlicher sowie literaturwissenschaftlicher Forschungsansätze, die sich mit dem Zusammenhang zwischen Sprache und Emotionen beschäftigen. Die Auseinandersetzung mit Emotionen ist als wichtiger Bestandteil von der Rhetorik oder der Poetik seit Platon und Aristoteles eine der „[...] größten Konfliktzonen des Denkens und der Wissenschaft [...].“ (Von Koppenfels und Zumbusch 2016, 1) und blickt folglich auf eine weitaus längere Traditionslinie zurück als der rein literaturwissenschaftlich geprägte Diskurs. Klassische Emotionstheorien, die eine Verbindung zwischen Philosophie, Emotionen und Dichtung berücksichtigen, existieren seit dem 17. Jahrhundert (vgl. Landweer und Renz 2008, 5).
Literarische Texte stellen einen Phänomenbereich dar, der eine besonders intensive Symbiose von Sprache und Emotionen aufweist. Sowohl in narrativen Texten selbst als auch in der literaturwissenschaftlichen Interpretation spielt die Analyse von Emotionen und Empfindungen deshalb eine Rolle. Die unterschiedlichen Ansätze gehen i. d. R. entweder vom Leser oder vom Text aus und verfolgen dementsprechend ein gemeinsames Forschungsinteresse, bei dem Fragen nach der emotionalen Wirkung von Literatur den Ausgangspunkt bilden (vgl. Mellmann 2016, 158). So existieren zahlreiche Einzelfallstudien, in denen die sprachliche Repräsentation von Emotionen in literarischen Texten und deren Prozessualität thematisiert werden. Gängiges Vorgehen ist hierbei die Untersuchung einer oder mehrerer Emotionen innerhalb eines bestimmten Werks oder – deutlich unterrepräsentiert – größer angelegte Studien, in denen große Textkorpora hinsichtlich der Emotionsmanifestationen im Text und deren Konzeptualisierungen untersucht werden (vgl. Hufnagel 2013 über Trauer in der Nibelungensage; Hindinger 2013 über Leid und Qual in der Literatur des 18. und 19. Jahrhunderts; Wieland 2013 über Emotionen in Max Frischs Homo Faber und Montauk; größer angelegte Studien: Alfes (1995) über Gefühle als Bestandteile literarischer Prozesse oder Winko (2003) über Emotionen in Gedichten und nicht zuletzt das Handbuch Literatur und Emotionen, in dem unterschiedliche theoretische Zugänge zum Zusammenspiel beider Bereiche erläutert werden).
Literaturwissenschaftliche Vorläufer der Sentimentanalyse finden sich auch in der Rezeptionsästhetik. Die Frage danach, wie künstlerische Werke wahrgenommen werden, ob die Möglichkeit einer emotionalen Wahrnehmung im Werk selbst angelegt ist oder sich erst im Prozess der Rezeption entfaltet (vgl. Winko 2003), setzt u. a. eine Untersuchung des emotiven bzw. expressiven oder emotionalen Gehalts literarischer Texte voraus. Die drei – leider oft synonym verwendeten Begriffe – beziehen sich auf unterschiedliche Ebenen, auf denen Emotionen analysiert werden: Varianten des Begriff emotional sind v. a. der Beschreibung und Analyse psychischer Phänomene vorbehalten, der Terminus emotiv bezeichnet Kategorien des Emotionalen in der Sprache und expressiv betrifft die Intensität eines emotionalen Gefühlsausdrucks (vgl. Ortner 2014, 68).
Im Kern lassen sich drei Phasen der literaturwissenschaftlichen Behandlung von Emotionen unterscheiden. Bis in die 1960er Jahre wurde die Forschung von der „Autorität des einfühlenden Interpreten” (Winko 2003, 10) geprägt, der aufgrund seiner Expertenkompetenz Aussagen über einen Text und die durch ihn bekundeten Gefühle tätigte. Im Zuge der szenischen Wende in den 70er Jahren wurden Emotionen als subjektives und deshalb nicht objektivierbares Phänomen aufgefasst, das sich nicht literaturwissenschaftlich erforschen lässt. Der Zusammenhang zwischen Gefühlen, Emotionen und Literatur wurde aufgrund dieser vermeintlich charakteristischen Unzugänglichkeit in der Literaturwissenschaft der 70er und 80er Jahre kaum thematisiert. Weder in strukturalistisch fundierten Analysen literarischer Texte, die v. a. den kognitiven Gehalt von Literatur behandelten, noch in philosophischen oder wissenschaftlichen Bezugstheorien wurde das Gefühlsthema aufgegriffen. Ab den 90er Jahren wurden Emotionen als Thema literarischer und nicht-literarischer Texte, aber auch in der Psychologie, der Philosophie und der Soziologie, wieder häufiger untersucht (vgl. Winko 2003, 10f.).
Die hieran anschließende Forschung zum Verhältnis zwischen Literatur und in textueller Gestalt erscheinenden Emotionen lässt sich in produktions- oder rezeptionsbezoge argumentierende Forschungsarbeiten gruppieren. Es finden sich u. a. empirische literaturwissenschaftliche Forschungsansätze (vgl. Alfes 1995), poststrukturalistische Arbeiten( vgl. Keitel 1996; Barthes 1973), formalistische bzw. strukturalistische Ansätze (vgl. Tomaševskij 1985) und kontextbezogene Ansätze (vgl. Boeschenstein 1954; Fick 1993; Meier 1993), die meistens auf eine Gesamtdeutung oder die Deutung einzelner Textstellen abzielen. Einen systematischen Forschungsüberblick sämtlicher literaturwissenschaftlicher Ansätze, die sich mit dem Thema Literatur und Emotionen auseinandersetzen (produktionsbezogene und rezeptionsbezogene Ansätze, imaginationstheoretische Modelle, Affektlehre, Rhetorik, die Kitsch-Debatte, die philosophische Debatte im angelsächsischen Raum, poststrukturalistische Ansätze, formalistische, strukturalistische und poststrukturaliatiche Ansätze) liefert Winko (2003). Textbezogene Ansätze behandeln Emotionen als explizite (also z. B. durch eine Figur oder die Erzählinstanz konkret thematisierte) oder implizite (also z. B. durch eine Handlung oder das Verhalten einer Figur indirekt ausgedrückte) Größe. Obwohl gerade in literarischen Texten Emotionen v. a. implizit vorliegen, dominieren explizite Ansätze (vgl. Winko 2003, 47).
4. Diskussion
Die digitale Literaturwissenschaft knüpft zum einen an diese Traditionslinien an und greift außerdem – als ein per se interdisziplinär ausgerichteter Fachbereich – auf die methodische und konzeptuelle Arbeit aus Informatik und Informationswissenschaft zurück. Beispiele für auf literarischen Texten basierende Sentimentanalysen stellen die in Abbildung 1 und 2 dargestellten Untersuchungen literarischer Texte hinsichtlich des Zusammenhangs zwischen Handlungsverlauf und Emotionen (vgl. Jockers 2014; Jockers 2015) dar.
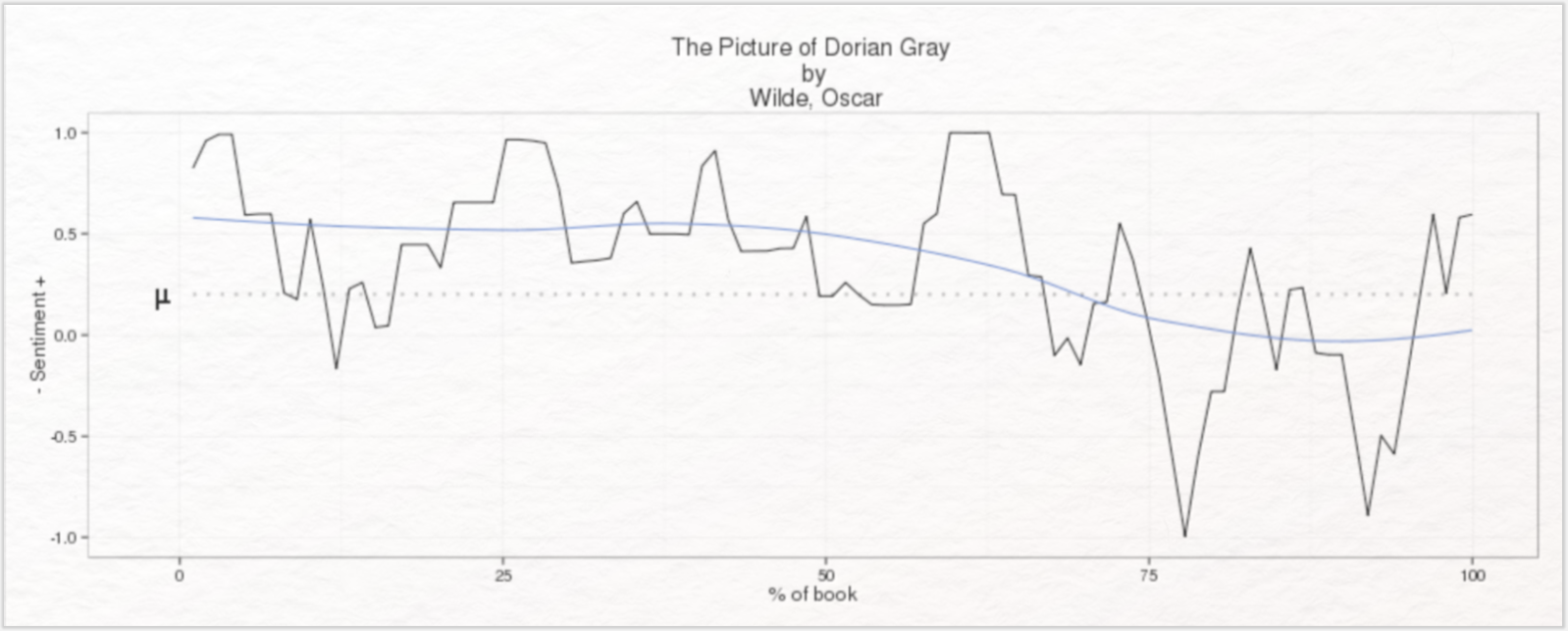
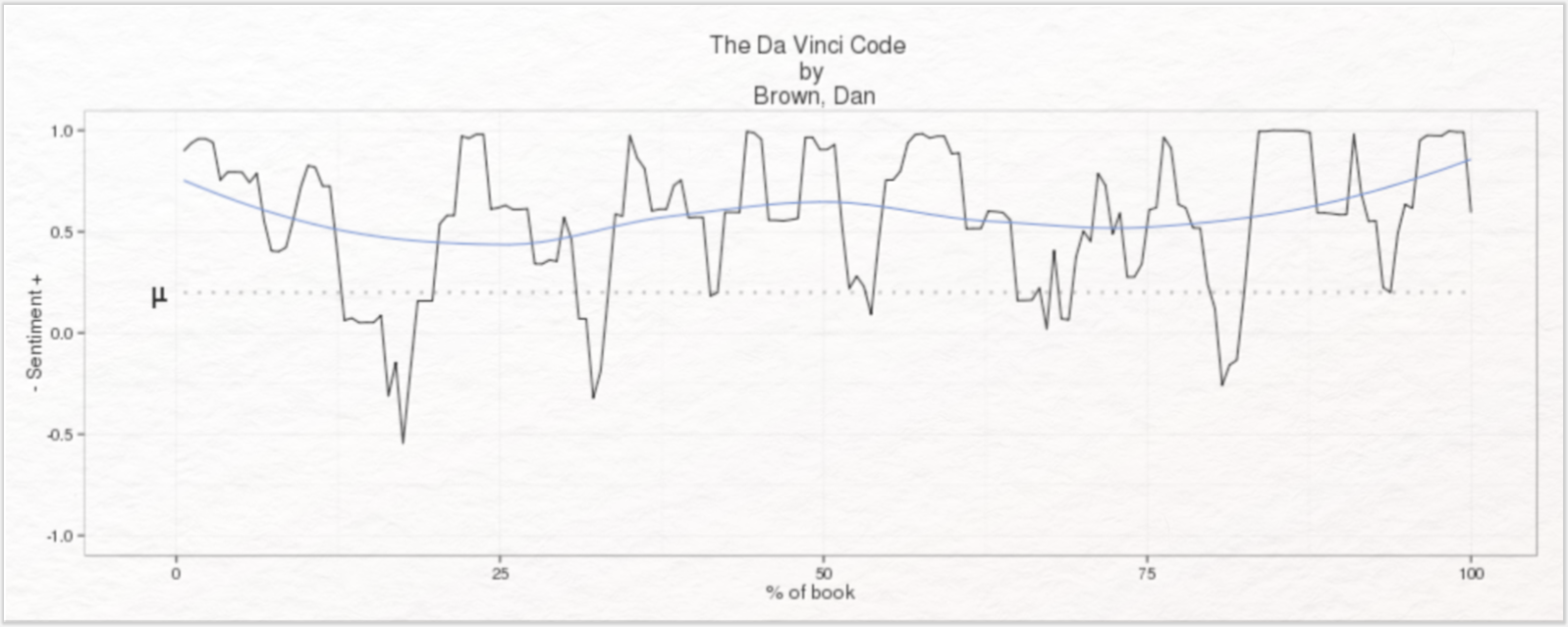
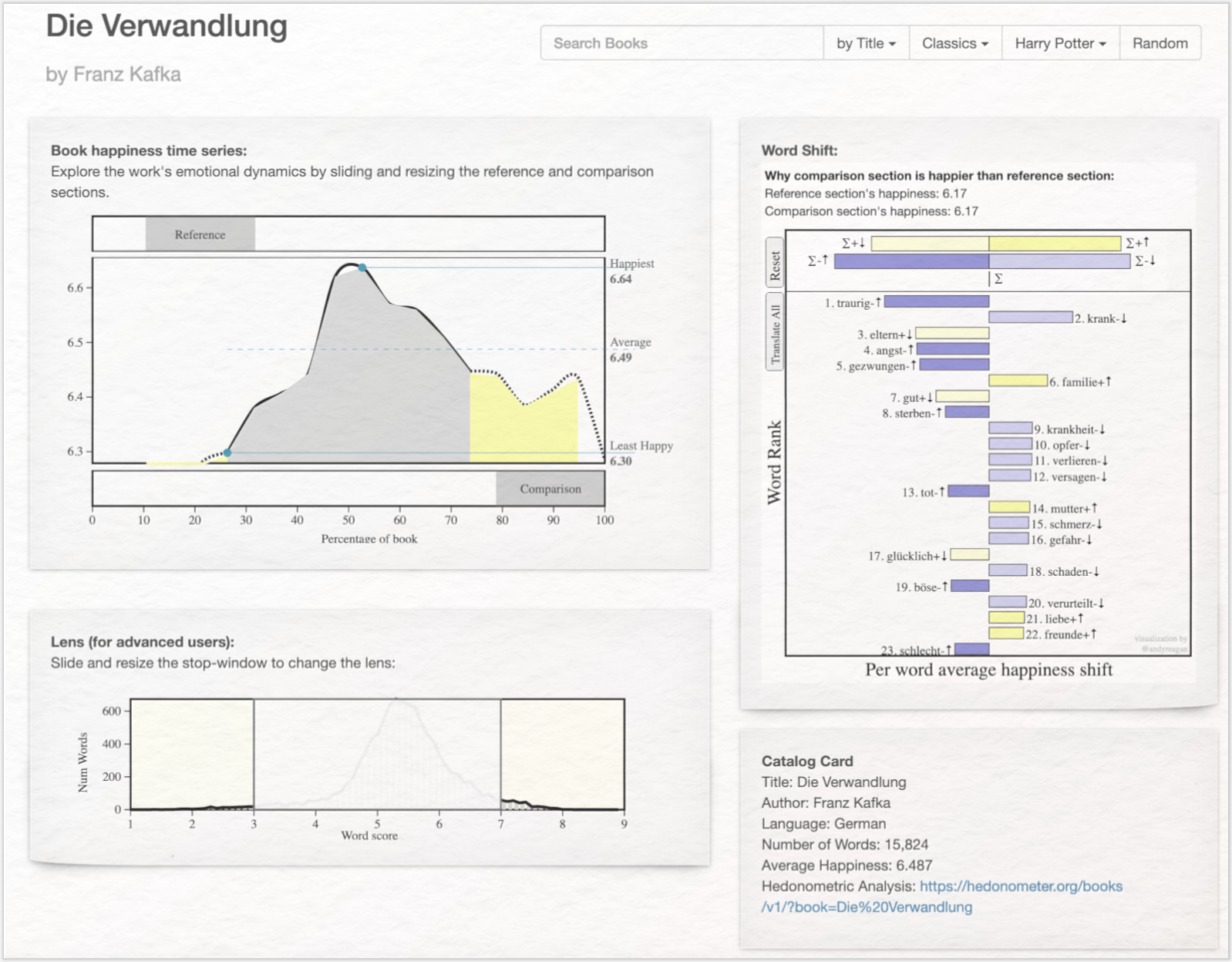
Mit der Bestimmung des Sentimentgehalts ausgewählter Märchen (vgl. Mohammad 2011), der Ermittlung prototypisch verlaufender Stimmungsbögen in fiktionalen Texten aus dem Project Gutenberg (vgl. Reagan et al. 2016) und Sentimentanalysen zu populären Romanen wie Harry Potter oder zu Erzählungen Franz Kafkas (siehe Abb. 3) liegen weitere Sentimentanalyse mit literaturwissenschaftlichem Schwerpunkt vor.
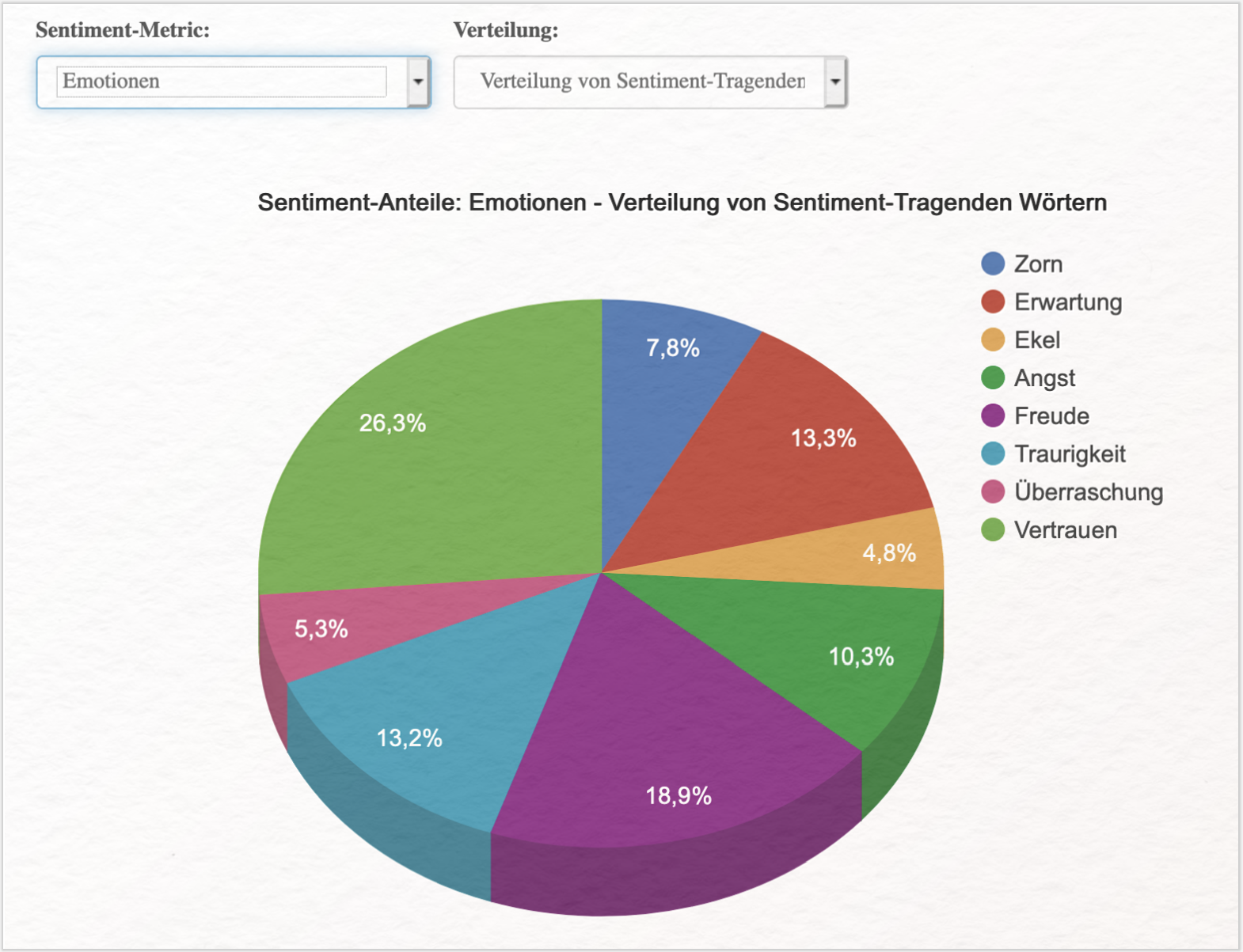
Ein weiteres anschauliches Beispiel für die quantitative Analyse ausgewählter Dramen Gotthold Ephraim Lessings – mit stärkerer Ausrichtung auf die technische Entwicklung – hinsichtlich der hier enthaltenen Emotionen (vgl. Schmidt 2017) ist in → Katharsis implementiert (siehe Abb. 4). Für einen Überblick über den Forschungsstand zur Sentiment- und Emotionsanalyse zur Analyse von Literatur: vgl. Kim und Klinger (2019).
Während es recht unterschiedliche Antworten – z. B. aus philosophischer, neurologischer, psychologischer oder eben aus literaturwissenschaftlicher Perspektive – auf die Frage gibt, wie Gefühle in den Text kommen (vgl. Winko 2003), sind die Antwortmöglichkeiten auf die Frage, auf welche Weise Gefühle computerbasiert wieder aus Texten herausgefiltert werden können, relativ überschaubar. Um Sentimentanalysen durchzuführen, stehen zwei unterschiedliche Ansätze zur Verfügung, die z. T. auch miteinander kombiniert werden: lexikon-basierte Sentimentanalysen und Sentimentanalysen, bei denen Methoden des maschinellen Lernens zum Einsatz kommen.
Die Lexika wurden i. d. R. manuell erstellt und knüpfen an unterschiedliche Konzepte zur Messung von Emotionen an (vgl. Lehmann, Mittelbach und Schmeier 2017). In den meisten Fällen werden die Lexika als Datensätze zur freien Verfügung gestellt. Eine laufende Bibliografie der für die Sentimentanalyse geeigneten Lexika fehlt leider. Eine hilfreiche Matrix der besonders umfangreichen bzw. etablierten Lexika bieten z. B. Lehmann, Mittelbach und Schmeier (2017) oder Schmidt (2017). Die Vielzahl an unterschiedlichen Sentimentwörterbüchern (siehe Ressourcen am Ende dieses Methodeneintrags) verweisen auf die Tatsache, dass sich Emotionen, Stimmungen und Wertungen je nach Textsorte, -sprache und -kontext unterscheiden. Sentimentwörterbücher sind domänenspezifische Konstrukte. Beispiele aus Goethes Faust I verdeutlichen die Nachteile der lexikonbasierten Sentimentanalyse. Orthographische Besonderheiten führen dazu, dass einige Wörter in einem automatisierten Abgleich mit einem Sentimentwörterbuch nicht erkannt werden. Das Wort „Bewundrung” würde bspw. aufgrund der von Goethe verwendeten Orthographie nicht als emotionsgeladenes Wort erkannt. Mit Schwierigkeiten verbunden ist außerdem ein spezifischer Wortschatz aus Wörtern, die im zeithistorischen Kontext des 18. und 19. Jahrhunderts verwendet wurden, in den Sentimentwörterbüchern – die zum größten Teil auf ein zeitgenössisches Vokabular abgestimmt sind – aber nicht vorkommen. Das führt bei Sentimentanalysen sozialer Medien zu Erkennungsraten zwischen 80 und 95 %. Da literarische Texte aber gerade ein historischer Sprachstil oder eine poetische Sprache auszeichnen, kann die Ausgrenzung dieser Eigenschaften zu Fehlkalkulationen führen (vgl. Schmidt, Burghardt und Wolff 2018, 4f.). „behaglich”, „Gönner”, „holden”, „Dirne”, „Lebensglück” oder „ergetzen” sind bspw. in zeitgenössischen Sentimentwörterbüchern wie SentiWS nicht enthalten.
Darüber hinaus handelt es sich bei der Wortsemantik nicht um eine statische Größe, sondern um eine variable Einheit, die sich über die Zeit verändern kann. „Dirne”, das im Faust ein junges, anmutiges und schönes Mädchen bezeichnet, ist in diesem Kontext positiv konnotiert. Im modernen deutschen Sprachgebrauch kann „Dirne” allerdings auch eine Prostituierte bezeichnen und ist eher negativ konnotiert. In Anbetracht der Schwierigkeit, das historische Vokabular mittels lexikonbasierter Sentimentanalyse zu berücksichtigen, stellt sich die Frage, wie sehr das Auslassen dieser Wörter das Gesamtergebnis der Analyse verfälschen würde. Erste Beispielanalysen zeigen eine konsistente Verbesserung durch Lexikonerweiterung mit historisch-linguistischen Varianten. Auf diese Weise wird versucht, die Zuverlässigkeit bei der lexikonbasierten Erkennung des historischen Vokabulars zu erhöhen. Eine verbesserte Lemmatisierung wirkt sich positiv auf die Leistung aus (vgl. Schmidt, Burghardt und Dennerlein 2018).
Ein weiteres Problem der lexikonbasierten Sentimentanalyse stellen Negationen dar, deren Auftreten das Analyseergebnis verfälschen kann. Die Implementierung von Tools, die Negationen erkennen können, würde zu besseren Ergebnissen führen, verlangt aber weitere technische Vorkenntnisse. Darüber hinaus wird deutlich, dass es spezifischer Sentimentwörterbücher bedarf, welche historische und orthographische Besonderheiten genauso einbeziehen wie individuelle Schreibstile. Für die literaturwissenschaftlich orientierte Sentimentanalyse gibt es bisher nur vereinzelte Ansätze, die auf die Erstellung eigener textsortenspezifischer Lexika abzielen. Lexikonbasierte Ansätze erfassen lediglich emotionsausdrückende Lexeme und deren Sentimentwert. Die Kluft zwischen Alltag und Kunstwerk bzw. einer außerkünstlerischen und alltäglichen Sprache auf der einen und einer innerkünstlerischen auf der anderen Seite (vgl. Herding 2008, 10) verweist auf ein Problemfeld der Methode, das sich dann ergibt, wenn versucht wird, zwei sehr unterschiedliche Untersuchungsgegenstände mit identischen Untersuchungsverfahren zu explorieren. Eine kontextuelle Emotionsthematisierung oder die Erkennung von emotionsausdrückenden Metaphern und expressiven Sprechakten lassen sich auf diese Weise nicht erkennen. Auch andere sprachliche Besonderheiten wie Ironie, Sarkasmus oder mehrdeutige Wörter werden in den lexikonbasierten Ansätzen nicht berücksichtigt.
Um Meinungen, Gefühle und Emotionen von Menschen zu analysieren oder vorauszusagen, können außerdem Verfahren des überwachten maschinellen Lernens eingesetzt werden. Diese Methode basiert auf einem mit Sentiment-Informationen angereicherten Trainigskorpus. Für Texteinheiten werden die Sentimente – i. d. R. per Hand – annotiert (vgl. Schmidt, Burghardt und Wolff 2018; Ignatow und Mihalcea 2017, 150). Anders als im Fall der lexikonbasierten Analyseverfahren wird durch die → manuelle Annotation also ein Modell trainiert, welches die Besonderheiten der Darstellung von Emotionen in literarischen Texten berücksichtigen kann. Zum jetzigen Stand der Forschung stellen sich Ansätze aus dem Bereich des maschinellen Lernens als leistungsstärker heraus (vgl. Schmidt, Burghardt und Wolff 2018; Pang et al. 2002). Dennoch sind Beiträge der zweiten „Großform” der Sentimentanalyse in der Minderheit, da es bis jetzt an der wichtigsten Grundlage hierfür mangelt: mit Sentiment-Informationen angereicherte Trainingskorpora. Bei einem Großteil der literaturwissenschaftlichen Sentimentanalysen wird deshalb auf lexikonbasierte Ansätze zurückgegriffen, obwohl sich neben den genannten Problemen – zumindest für den deutschen Sprachraum – ein weiterer Mangel abzeichnet: Es existieren deutlich weniger evaluierte Ressourcen für die lexikonbasierte Sentimentanalyse als etwa im angelsächsischen Sprachraum.
Für beide angeführten Formen der Sentimentanalyse gilt: Der Phänomenbezeichnung und der Frage danach, was genau mit der Sentimentanalyse überhaupt „gemessen” wird, fehlt es oft an terminologischer Genauigkeit. Während Jockers (2015) von „emotional content”, „sentiment” oder „emotional valence” spricht, ist an anderer Stelle von „subjectivity attitude” (vgl. Zehe et al. 2016), „emotion words” und deren Dichte (vgl. Mohammad 2011) oder negativen und positiven „emotionalen Bewertungen” (vgl. Schmidt, Burghardt und Wolff 2018) die Rede. Oft bleibt es zunächst relativ undeutlich, welches Phänomen – Gefühl, Affekt, Empfindung, Emotion, Leidenschaft, Eindruck oder Stimmung – mit der Sentimentanalyse literarischer Texte untersucht werden soll. Es fehlt eine geeignete Metasprache, deren konsistente Verwendung terminologische und sachliche Verwirrungen vermeiden würde und die den metatheoretischen Rahmen nutzen – wie ihn etwa Simone Winko für die literaturwissenschaftliche Emotionsforschung oder Monika Schwarz-Friesel für die linguistische Emotionsforschung – bereits eingeführt haben.
Eine in die Tiefe gehende Forschung müsste außerdem Ansätze zur Erklärung emotionaler Phänomene als theoretisches Fundament einbeziehen und eine Kontextualisierung vornehmen, um die Ergebnisse der Sentimentanalyse nicht im „luftleeren” Raum stehen zu lassen. Dieser Rückbezug fordert Forschende außerdem heraus, die literaturwissenschaftliche, inhaltliche Relevanz von Sentimentanalysen in den Diskurs zu holen.
Allerdings wird der Blick auf die inhaltliche Relevanz und die Entwicklung einer Metasprache durch die Fokussierung auf eine technische Weiterentwicklung und Evaluation bestehender Methoden beider Großformen der Sentimentanalyse zum Teil verstellt. Gleichzeitig ist die Grundlagenforschung ein notwendiger Schritt in Richtung einer literaturwissenschaftlichen Domänenadaption der Sentimentanalyse.
Angesichts des interdisziplinär verwurzelten Untersuchungsgegenstands – Emotionen und Gefühle – liegt es nahe bzw. ist es gerade in den interdisziplinär ausgerichteten digitalen Geisteswissenschaften gängige Praxis, methodisches Vorgehen aus verwandten Fachdisziplinen auf die Auseinandersetzung mit „unserem Material” zu übertragen. Die literaturwissenschaftlich ausgerichtete Sentimentanalyse stößt hierbei allerdings an deutliche Grenzen, da Untersuchungsgegenstand und Untersuchungsverfahren (noch) nicht kompatibel erscheinen.
5. Technische Grundlagen
Tools zur Sentimentanalyse, die über eine grafische Benutzeroberfläche verfügen, ohne ausgeprägtes technisches Vorwissen bedienbar sind, eine individuelle Textauswahl zulassen und der Spezifik literarischer Texte gerecht werden, sind noch nicht entwickelt worden. Gleichzeitig müssten verstärkt Anforderungsanalysen durchgeführt werden, die den Einbezug literaturwissenschaftlicher Expertise in die technische Entwicklung ermöglichen. Ohne die Entwicklung einer grafischen Benutzeroberfläche wird die literaturwissenschaftliche Sentimentanalyse eine Form der Textanalyse bleiben, die erhebliches technisches Vorwissen verlangt. Das gilt sowohl für die Anwendung lexikonbasierter Verfahren als auch für Verfahren, die maschinelles Lernen beinhalten. Mit Tools wie Weka oder RapidMiner stehen zwar Machine-Learning-Tools mit einem GUI zur Verfügung. Da es sich hier allerdings um Werkzeuge zum Machine-Learning handelt, kann von einem niedrigschwelligen Zugang nicht die Rede sein.
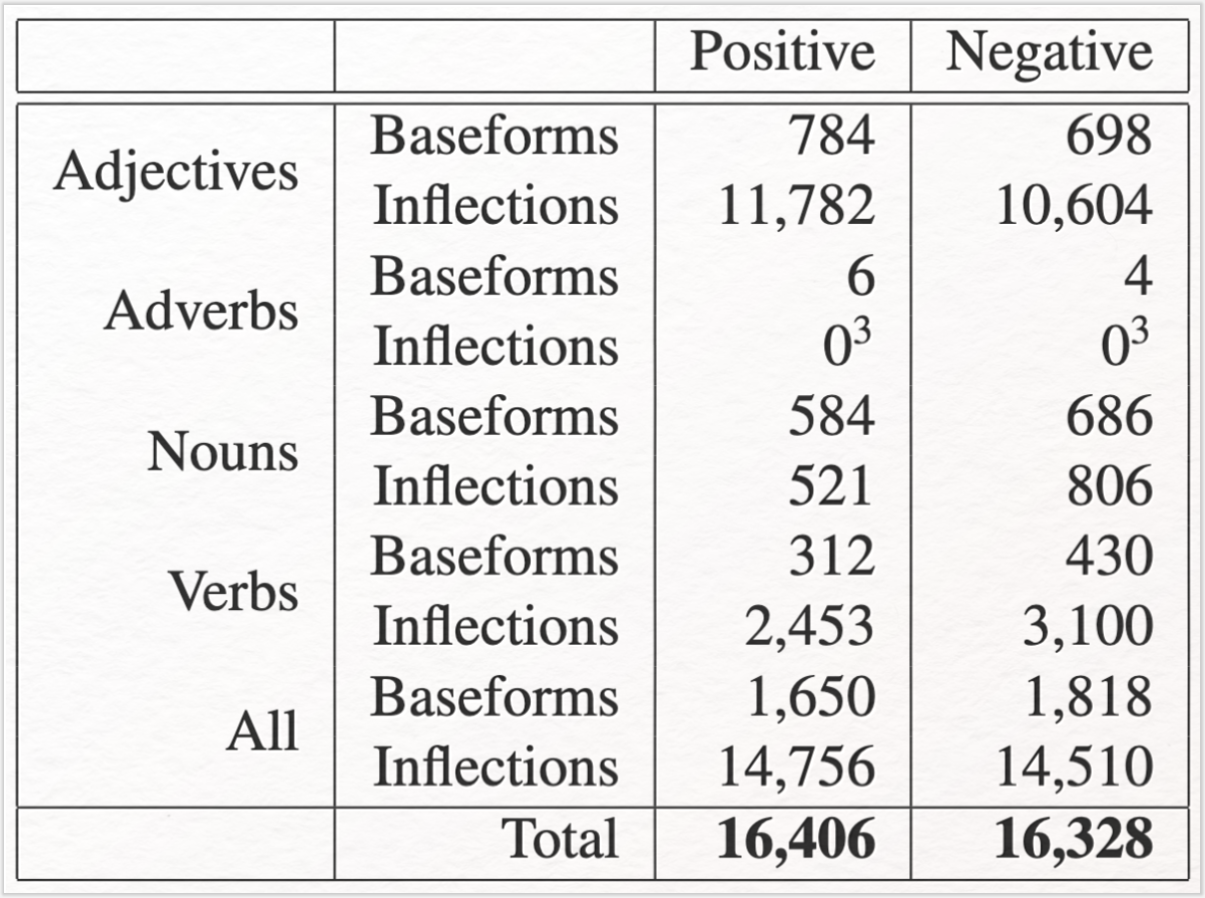
Elementarer Bestandteile der lexikon-basierten Sentimentanalyse sind annotierte Satz- und/oder Wortlisten (sog. Sentimentwörterbücher) und eine Aggregationsmethode (z. B. hierfür entworfenen Python- oder R-Programme). Die Sentimentwörterbücher oder Wortlisten enthalten Wörter, die mit Informationen über deren Emotionsgehalt angereichert wurden (emotion label). Gängig ist z. B. die Angabe der Polarität eines Wortes, also deren Auszeichnung als negativ, neutral oder positiv, in einem bestimmten Intervall. Die lexikonbasierte Sentimentanalyse wird in der Literaturwissenschaft häufiger eingesetzt. Hierbei werden sämtliche in einem Text vorkommende Wörter mit der jeweiligen Wortliste oder einer Kombination aus mehreren Sentimentwörterbüchern abgeglichen. Sentimentwörter (Sentiment Bearing Word, SBW) werden als solche erkannt und bekommen durch den Abgleich mit dem Lexikon einen Sentimentwert zugewiesen. Eine frei verfügbare und im deutschsprachigen Raum besonders häufig verwendete bzw. etablierte Ressource für die lexikonbasierte Sentimentanalyse ist der SentimentWortschatz (kurz: SentiWS) der Universität Leipzig. Für die hier enthaltenen Wörter – die Sentiment Bearing Words – werden jeweils eine positive oder negative Polarität im Intervall [−1; 1], die Wortart und mögliche Flexionsarten angegeben. Die im Jahr 2018 zuletzt aktualisierte Version enthält insgesamt circa 18.000 negative und 16.000 positive Wortformen; circa 1.800 negative und 1.650 positive Grundformen und unterschiedliche Flexionsformen. Neben Adverbien und Adjektiven sind auch Nomen und Verben, die die Träger von Sentiment sind, verzeichnet (vgl. Remus et al. 2010). Laden Sie SentiWS herunter, so erhalten sie zwei UTF-8 kodierte TXT-Dateien, in denen jeweils die positiven und negativen SBWs in alphabetischer Reihenfolge aufgelistet sind (siehe Abb. 5).
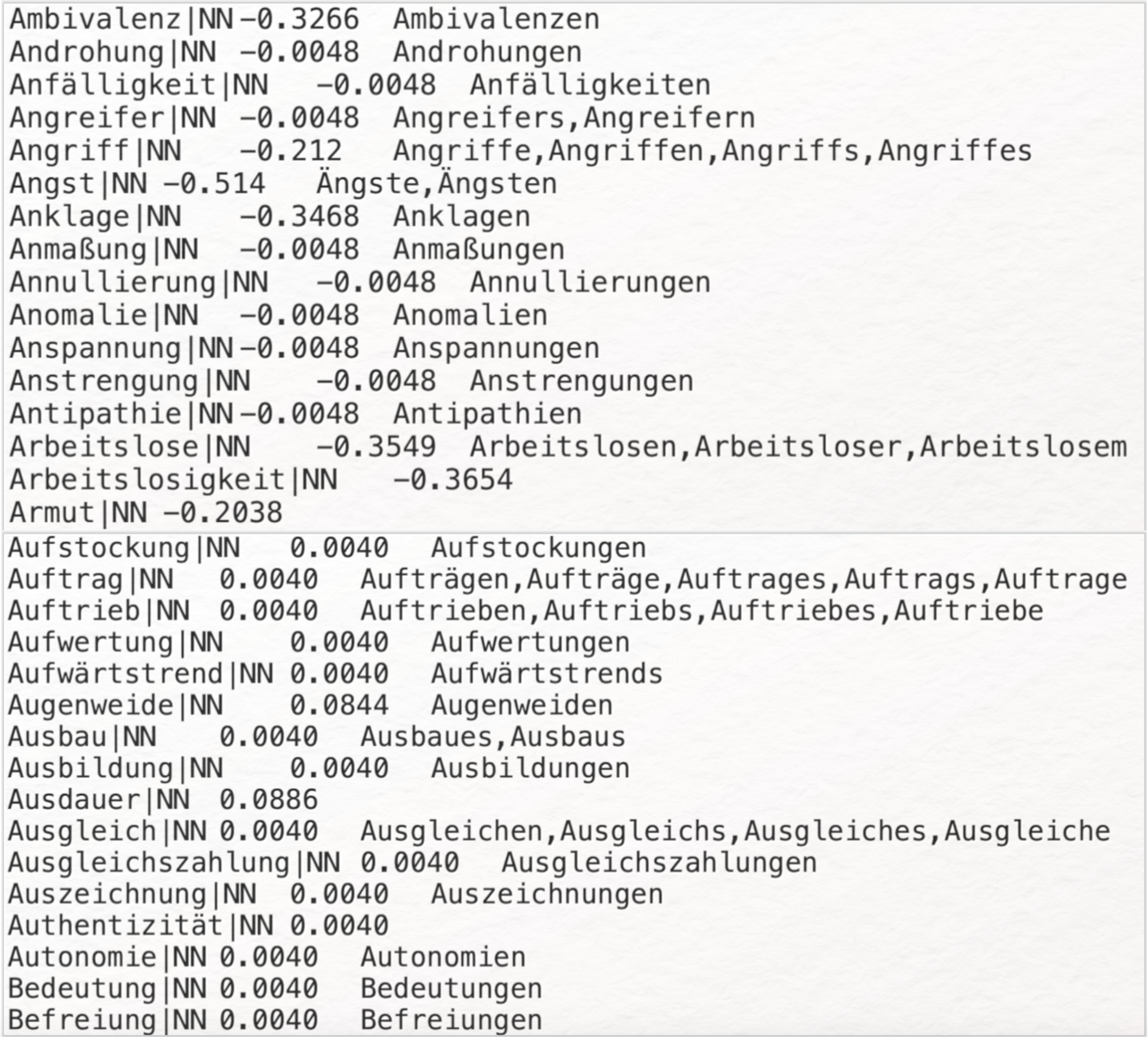
Ein POS-Tagging wurde auf Basis des Stuttgart-Tübingen-Tagsets (STTS) durchgeführt. Ausgezeichnet wurden Nomen (NN), attributive und deskriptive Adjektive (ADJX), infinite Verben (VVINF) und Adverbien (ADV). Die Flexionsformen wurden aus einer projektinternen Datenbank bezogen.
Dem Wörterbuch liegen die Auswertung und Zusammenführung dreier Quellen zugrunde. Die Ausprägung der einzelnen Wörter wurden mittels der „Pointwise Mutual Information”-Methode (PMI) berechnet. Bei diesem Ansatz wird die semantische Ausprägung eines Wortes (SO: semantic orientation) aus semantischen Assoziationen des Wortes (SA: semantic association) zu ausgewählten Wörtern (sog. seed words: ausgewählte Wörter, die bei der Berechnung quasi als exemplarische Schlüsselwörter verwendet werden), die stark positiv oder negativ konnotiert sind, abgeleitet. Die semantische Ausprägung eines Wortes bezeichnet folglich den Grad der Verbindung eben dieses Wortes zu einem manuell erstellten Set an Wörtern, die positiv oder negativ konnotiert sind. Für jedes Wort wird berechnet, ob und wie stark es mit positiven und negativen Wörtern assoziiert wird. (Die für die Berechnung der SO eines Wortes herangezogenen positiven seed words sind „gut”, „schön”, „richtig”, „glücklich”, „erstklassig”, „positiv”, „großartig”, „ausgezeichnet”, „lieb”, „exzellent” und „phantastisch”. Die für die Berechnung der SO eines Wortes herangezogenen negativen seed words sind „schlecht”, „unschön”, „falsch”, „unglücklich”, „zweitklassig”, „negativ”, „scheiße”, „minderwertig”, „böse”, „armselig” und „mies”). Die in Abbildung 5 und 6 angegebenen Kommazahlen stellen das Ergebnis dieses Berechnungsverfahrens dar und geben für jedes Wort einen Sentimentwert an. Hierbei ist +1 der positivste Sentimentwert und –1 der negativste Sentimentwert, der einem Wort zugeordnet werden kann. Sehr positive Wörter sind beispielsweise „Freude”, mit einem Sentimentwert von 0,6502 oder „zuvorkommend” mit einem Sentimentwert von 0,6669. Mit Sentimentwerten von –0,9269 und –0,4889 („schädlich” bzw. „Aggression”) handelt es sich um besonders negative Sentimentwörter.
6. Nachweise und weiterführende Literatur
- Alfes, Henrike F. (1995): Literatur und Gefühl: Emotionale Aspekte literarischen Schreibens und Lesens. Opladen: Westdeutscher Verlag.
- Barthes, Roland (1973): Le plaisir du texte. Paris: Éd. du Seuil.
- Böschenstein, Hermann (1954): Deutsche Gefühlskultur: Studien zu ihrer dichterischen Gestaltung. Bern: Haupt.
- Clausen, Rosemarie (1960): Gustaf Gründgens Faust in Bildern. Nach einer Verfilmung der Goetheschen Tragödie. Braunschweig: Westermann.
- Fick, Monika (1993): Sinnenwelt und Weltseele: Der psychophysische Monismus in der Literatur der Jahrhundertwende. Tübingen: Niemeyer.
- Herding, Klaus (2008): „Wie sich Gefühle Ausdruck verschaffen. Emotionen in Nahsicht“. In: Krause Herding und Antje Krause-Wahl (Hrsg.): Wie sich Gefühle Ausdruck verschaffen. Emotionen in Nahsicht. Berlin: Driesen, 7–16.
- Hindinger, Barbara (2013): „,da bohr’ ich mich in Leid und Qual hinein’. Männlichkeit und schmerzliche Emotionen in der Literatur des 18. und 19. Jahrhunderts“. In: Toni Tholen und Jennifer Clare (Hrsg.): Literarische Männlichkeit und Emotionen. Heidelberg: Universitätsverlag Winter, 109–141.
- Hufnagel, Nadine (2013): „Die Darstellung der Trauer König Etzels. Geschlecht und Emotion in der mittelhochdeutschen Nibelungenklage“. In: Toni Tholen und Jennifer Clare (Hrsg.): Literarische Männlichkeit und Emotionen. Heidelberg: Universitätsverlag Winter, 75–89.
- Ignatow, Gabriel und Rada Mihalcea (2017): Text Mining. A guidebook for the Social Sciences. Los Angeles (u.a.): SAGE.
- Ignatow, Gabriel und Rada Mihalcea (2018): An Introduction to Text Mining. Research Design, Data Collection, and Analysis. Los Angeles (u.a.): SAGE.
- Jockers, Matthew (2014): „A Novel Method for Detecting plot“. In: Matthew L. Jockers, URL: http://www.matthewjockers.net/2014/06/05/a-novel-method-for-detecting-plot/ [Zugriff: 16.7.2019].
- Jockers, Matthew (2015): „Revealing Sentiment and Plot Arcs with the Syuzhet Package“. In: Matthew L. Jockers, URL: http://www.matthewjockers.net/2015/02/02/syuzhet/ [Zugriff: 16.7.2019].
- Kiritchenko, Svetlana, Xiaodan Zhu und Saif M. Mohammad (2014): „Sentiment Analysis in Short Informal Texts“. In: Journal of Artificial Intelligence Research. 50, 723–762.
- Keitel, Evelyn (1996): Von den Gefühlen beim Lesen: Zur Lektüre amerikanischer Gegenwartsliteratur. München: Fink.
- Kim, Evgeny und Roman Klinger (2019): „A Survey on Sentiment and Emotion Analysis for Computational Literary Studies“. In: Zeitschrift für digitale Geisteswissenschaften. DOI: 10.17175/2019_008.
- Kim, Evgeny, Sebastian Padó und Roman Klinger (2017): „Prototypical Emotion Development in Literary genres“. In: Proceedings of the Joint SIGHUM Workshop on Computational Linguistic for Cultural Heritage, Social Sciences, Humanities and Literature. 17–26.
- Landweer, Hilge und Ursula Renz (2008): „Zur Geschichte philosophischer Emotionstheorien“. In: Hilge Landweer und Ursula Renz (Hrsg.): Handbuch klassische Emotionstheorien. Berlin, New York: de Gruyter, 1–18.
- Lehmann, Jörg, Moritz Mittelbach und Sven Schmeier (2017): „Quantifizierung von Emotionswörtern in Texten“. In: DARIAH-DE Working Papers. 24.
- Liu, Bing (2015): Sentiment Analysis: Mining Opinions, Sentiments and Emotions. Cambridge: University Press.
- Meier, Albert (1993): Die Dramaturgie der Bewunderung : Untersuchungen zur politisch-klassizistischen Tragödie des 18. Jahrhunderts. Frankfurt am Main: Klostermann.
- Mellmann, Katja (2016): „Empirische Emotionsforschung“. In: Martin von Koppenfels und Cornelia Zumbusch (Hrsg.): Handbuch Literatur & Emotionen. Berlin, Boston: de Gruyter, 158–175.
- Mohammad, Saif M. (2011): „NRC Word-Emotion Association Lexicon (aka EmoLex)“. URL: https://saifmohammad.com/WebPages/NRC-Emotion-Lexicon.htm [Zugriff: 1. September 2019].
- Ortner, Heike (2014): Text und Emotionen: Theorie, Methode und Anwendungsbeispiele emotionslinguistischer Textanalyse. Tübingen: Narr.
- Reagan, Andrew J., Lewis Mitchell, Dilan Kiley, Christopher M. Danforth und Peter Sheridan Dodds (2016): „The emotional arcs of stories are dominated by six basic shapes“. In: EPJ Data Science. 5 (31), 1–12. DOI: 10.1140/epjds/s13688-016-0093-1.
- Remus, Robert, Uwe Quasthoff und Gerhard Heyer (2010): „SentiWS - A Publicly Available German-language Resource for Sentiment Analysis“. In: Proceedings of the Seventh International Conference on Language Resources and Evaluation (LREC’10), Valetta, Malta: European Language Resources Association, 1168–1171. URL: http://www.lrec-conf.org/proceedings/lrec2010/pdf/490_Paper.pdf.
- Schmidt, Thomas (2017): Gefühl ist alles; Name ist Schall und Rauch - Der Einsatz von Sentiment Analysis in der quantitativen Dramenanalyse. Masterarbeit im Fach Medieninformatik am Institut für Information und Medien, Sprache und Kultur. Regensburg: Universität Regensburg. Masterarbeit im Fach Medieninformatik am Institut für Information und Medien, Sprache und Kultur.
- Schmidt, Thomas, Manuel Burghardt und Christian Wolff (2018): „Herausforderungen für Sentiment Analysis bei literarischen Texten“. In: Burghardt, Manuel; und Claudia Müller-Birn (Hrsg.)INF-DH 2018, Bonn: Gesellschaft für Informatik e.V.. DOI: 10.18420/infdh2018-16.
- Schmidt, Thomas, Manuel Burghardt und Katrin Dennerlein (2018): „‚Kann man denn auch nicht lachend sehr ernsthaft sein?‘ - Zum Einsatz von Sentiment Analyse-Verfahren für die quantitative Untersuchung von Lessings Dramen“. In: Book of Abstracts, DHd 2018. URL: https://epub.uni-regensburg.de/37579/1/Self-Archiving-Version_DHd-2018.pdf [Zugriff: 9.9.2019].
- Tomaševskij, Boris (1985): Theorie der Literatur. Wiesbaden: Harrassowitz.
- Von Koppenfels, Martin und Cornelia Zumbusch (2016): „Einleitung. Literatur und Emotionen“. In: Hilge Landweer und Ursula Renz (Hrsg.): Handbuch Literatur & Emotionen. Berlin, Boston: de Gruyter, 1–36.
- Wieland, Klaus (2013): „Alternde Männer, wechselnde Gefühle. Emotionale Konversionen in Max Frischs Homo Faber und Montauk“. In: Toni Tholen und Jennifer Clare (Hrsg.): Literarische Männlichkeit und Emotionen. Heidelberg: Universitätsverlag Winter, 177–201.
- Winko, Simone (2003): Kodierte Gefühle. Zu einer Poetik der Emotionen in lyrischen und poetologischen Texten um 1900. Berlin: Erich Schmidt Verlag.
- Zehe, Albin, Martin Becker, Lena Hettinger, Andreas Hotho, Isabella Reger und Fotis Jannidis (2016): „Prediction of Happy Endings in German Novels based on Sentiment Information“. In: Cellier, Peggy; Thierry Charnois; Andreas Hotho; Stan Matwin; Marie-Francine Moens und Yannick Toussaint (Hrsg.)Proceedings of DMNLP, Riva del Garda, Italy, 9–17. URL: http://ceur-ws.org/Vol-1646/paper2.pdf.
- Zhang, Lei und Bing Liu (2014): „Aspect and Entity Extraction for Opinion Mining“. In: Wesley W. Chu (Hrsg.): Data Mining and Knowledge Discovery for Big Data. Heidelberg: Springer, 1–40.
- Zhao, Yanchang, Huaifeng Zhang, Longbing Cao, Hans Bohlscheid, Yuming Ou und Chengqi Zhang (2014): „Data Mining Applications in Social Security“. In: Wesley W. Chu (Hrsg.): Data Mining and Knowledge Discovery for Big Data. Heidelberg: Springer, 83–96.
Sentimentwörterbücher (Auswahl):
- SentimentWortschatz (SentiWS), Universität Leipzig: http://wortschatz.uni-leipzig.de/de/download
- NRC-Word-Emotion Association Lexicon (EmoLex) und diverse domänenspezifische Erweiterungen, National Research Council Canada: https://saifmohammad.com/WebPages/NRC-Emotion-Lexicon.htm
- German Polarity Clues (GPC), Universität Bielefeld: http://www.ulliwaltinger.de/sentiment/
- Berlin Affective Word List – Reloaded ( BAWL-R), Freie Universität Berlin: https://www.ewi-psy.fu-berlin.de/einrichtungen/arbeitsbereiche/allgpsy/Download/index.html
- Multi-layer Reference Corpus for German Sentiment (MLSA), Universität Mannheim: http://linkeddatacatalog.dws.informatik.uni-mannheim.de/dataset/mlsa
- Norms of valence, arousal, and dominance for 13,915 English Lemmas: https://pubmed.ncbi.nlm.nih.gov/23404613/
Weitere Tools:
- LIWC: https://www.liwc.app (vgl. → LIWC)
- SentiStrength: http://sentistrength.wlv.ac.uk/
- SentText: https://thomasschmidtur.pythonanywhere.com (vgl. → SentText)
Abgeschlossene Sentimentanalysen zu ausgewählten literarischen Texten:
- Sentimentanalyse mit Katharsis: http://lauchblatt.github.io/QuantitativeDramenanalyseDH2015/sa_selection.html
- Hedonometer, University of Vermont Complex Systems Center, and the technology of Brian Tivnan, Matt McMahon, and their team from The MITRE Corporation: https://hedonometer.org/books/v1/
