1. Kurzbeschreibung
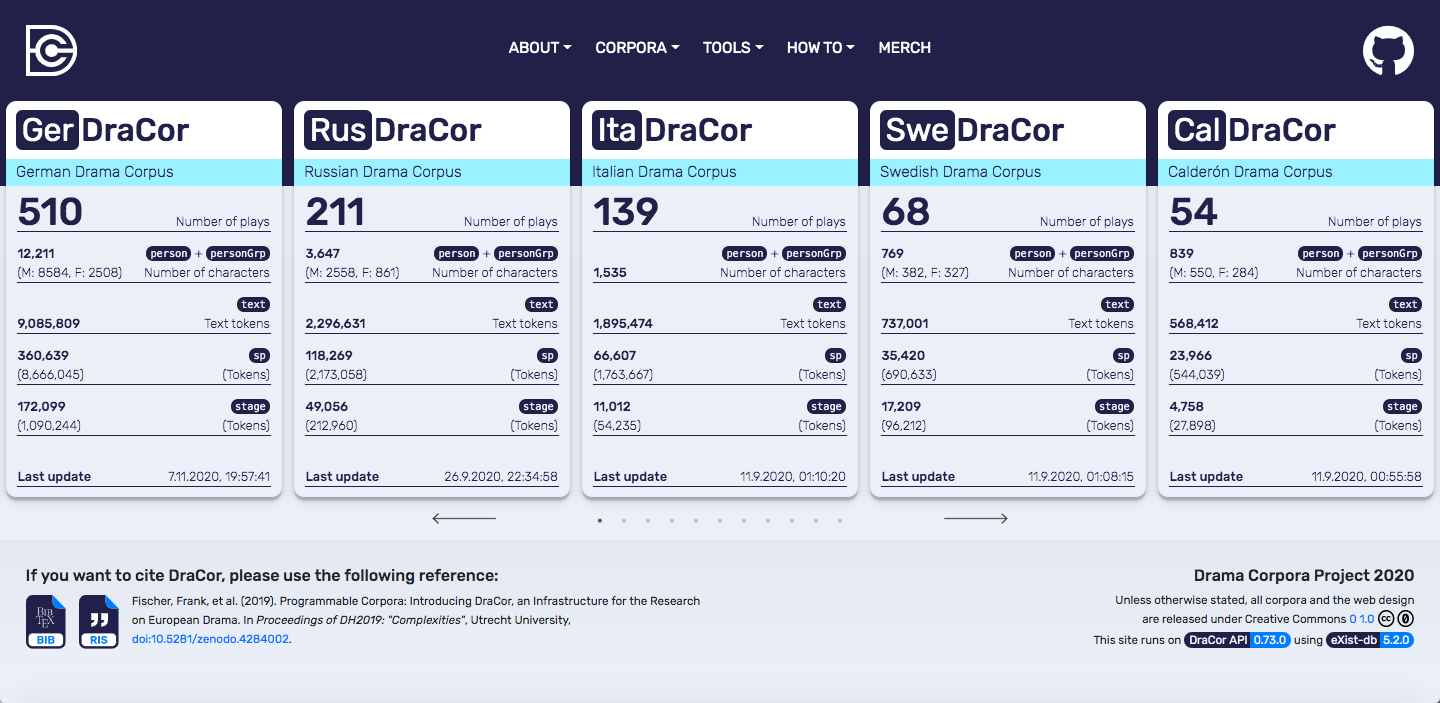
DraCor bietet für eine Vielzahl von deutschsprachigen, russischen, italienischen, schwedischen, altgriechischen, spanischen, tatarischen, elsässer, antik römischen oder auch für Shakespeare- und Caldéron-Dramen den zielgenauen Zugriff auf bestimmte Textuntermengen (wie etwa der gesprochene Text pro Figur; nur der Nebentext, nur Texte weiblicher Figuren etc.). DraCor generiert zudem automatisch Netzwerke (vgl. → Netzwerkanalyse), die figürliche Kopräsenzen anzeigen. Die Netzwerkdaten können Sie im CSV- oder → Gephi-kompatiblen GEXF-Format herunterladen und weiterverarbeiten. Eine API bietet zudem zahlreiche Möglichkeiten und zusätzliche Formate zur Weiterverarbeitung der vereinheitlichten Metadaten.
Steckbrief
- https://dracor.org
- herausgegeben durch das Centre for Digital Humanities an der HSE Moskau und die Universität Potsdam; entstanden aus dem mittlerweile eingestellten DLINA-Projekt und → Ezlinavis
- derzeit 510 deutschsprachige, 211 russische, 139 italienische, 68 schwedische, 39 griechische, 36 antik römische , 25 spanische, 7 elsässer und 3 tartarische sowie 54 Caldéron- und 37 Shakespeare-Dramen
- strukturelle (Akte, Szenen, Auftritte, Szenenbeschreibungen etc.), semantische (z. B. Gender der jeweiligen Figuren) und weitere Metadaten: Autor, Entstehungsdatum, Veröffentlichung und Premiere des Stücks, Figurennamen, Link zur Textquelle
- zwischen 1730–1930 erschienene vollständige Dramentexte (keine Fragmente), insb. übernommen vom → TextGrid Repository
2. Anwendungsbeispiel
Sie untersuchen in einem Forschungsprojekt Figurenkonstellationen in Dramen des Sturm und Drang und interessieren sich für das Verhältnis von weiblichen und männlichen Figuren. Mit DraCor erhalten Sie mit wenigen Klicks automatisch Figurennetzwerke zu den Dramen und können diese miteinander vergleichen. Sie sehen, welche Figuren in einzelnen Akten gemeinsam auftreten und wie groß der Anteil einer jeden Figur am gesprochenen Text ist. Die Texte können Sie per API in vielerlei Formen (bspw. Text pro Figur inkl. Genderangabe, nur Nebentexte/Regieanweisungen, nur gesprochene Texte etc.) als TXT-, RDF-, CSV-, GEXF- oder JSON-Datei herunterladen und weiterverwenden.
3. Diskussion
3.1 Kann ich DraCor für wissenschaftliche Arbeiten nutzen?
Ja. Den deutschen Texten liegt insbesondere das → TextGrid Repository mit dem dort erarbeiteten TEI-XML zugrunde, das korrigiert und angereichert wurde. Zudem werden Texte von Gutenberg-DE und Wikisource integriert und formal angeglichen. Außerdem werden zukünftig weitere Dramen aus dem → Deutschen Textarchiv (DTA) integriert. Für die zusätzlichen Dramen aus Gutenberg-DE und Wikisource ist das Aufnahmekriterium, dass es eine bekannte Druckvorlage gibt, die als Vergleichsgrundlage herangezogen wird. Die russischen Dramen stammen aus der Wikisource, der Russian Virtual Library, der Online Library of Alexei Komarov und der Maxim Moshkov’s Library, die Shakespeare-Dramen aus der Folger Shakespeare Library, die spanischen Dramen aus der Biblioteca Electrónica Textual del Teatro en Español (BETTE), die altgriechischen aus der Perseus Digital Library. Eigene wissenschaftliche Anwendungen von DraCor sind hier dokumentiert. Es werden nur Texte in DraCor aufgenommen, die erstens keine Fragmente und zweitens in den Jahren 1730–1930 erschienen sind. Dabei möchte man eher ein repräsentatives als ein riesiges Korpus aufbauen, das Ziel sind etwa 1000 deutschsprachige und mehr als 500 russische Stücke. Zusätzlich zu Caldéron- und Shakespearekorpus sind derzeit zwei weitere autorspezifische Korpora zu Henrik Ibsen und Ludvig Holberg geplant.
Das Projekt ist nicht primär als Repositorium für Volltexte gedacht, auch wenn Sie die gesamte Textsammlung mit einer Zeile in der Commandline downloaden können; eine Anleitung dazu finden Sie hier am Ende von „Corpus Description”. Ein Gesamtdownload der jeweiligen XML-Datei ist mit Rechtsklick auf „TEI version” zwar möglich, in Textsammlungen wie → TextGrid Repository (das in DraCor zu jedem Drama verlinkt ist) oder dem → Deutschen Textarchiv (DTA) jedoch etwas benutzerfreundlicher gestaltet. Das Ziel ist vielmehr, einen Ausgangspunkt für verschiedene digitale Projekte bereitzustellen, für die man sich die Daten in der jeweils präferierten Form über die API-Abfrage herunterladen und weiterverarbeiten kann. Gemäß dieses Grundsatzes sind alle Daten auf DraCor für jeden zugänglich. Bei Bedarf ist es zudem möglich, die gesamte Plattform lokal zu installieren (s. hier). Mit dem von DraCor bereitgestelltenTool Shiny DraCor haben Sie weitere Möglichkeiten, die Korpora zu explorieren bzw. die Visualisierungen zu beeinflussen (zu finden im Menü unter „Tools").
Strukturelle Metadaten wie auch in das TEI übernommene Seitenumbrüche ermöglichen die Orientierung in den Texten. Die Metadaten sind auf vereinheitlichtem Niveau, im Shakespeare-Korpus fehlen bislang lediglich die Genderannotationen für Figuren. Geplant ist hierbei die Möglichkeit, dass Benutzer*innen weitere Annotationen über GitHub beisteuern können.
3.2 Wie benutzerfreundlich ist die Arbeit mit DraCor?
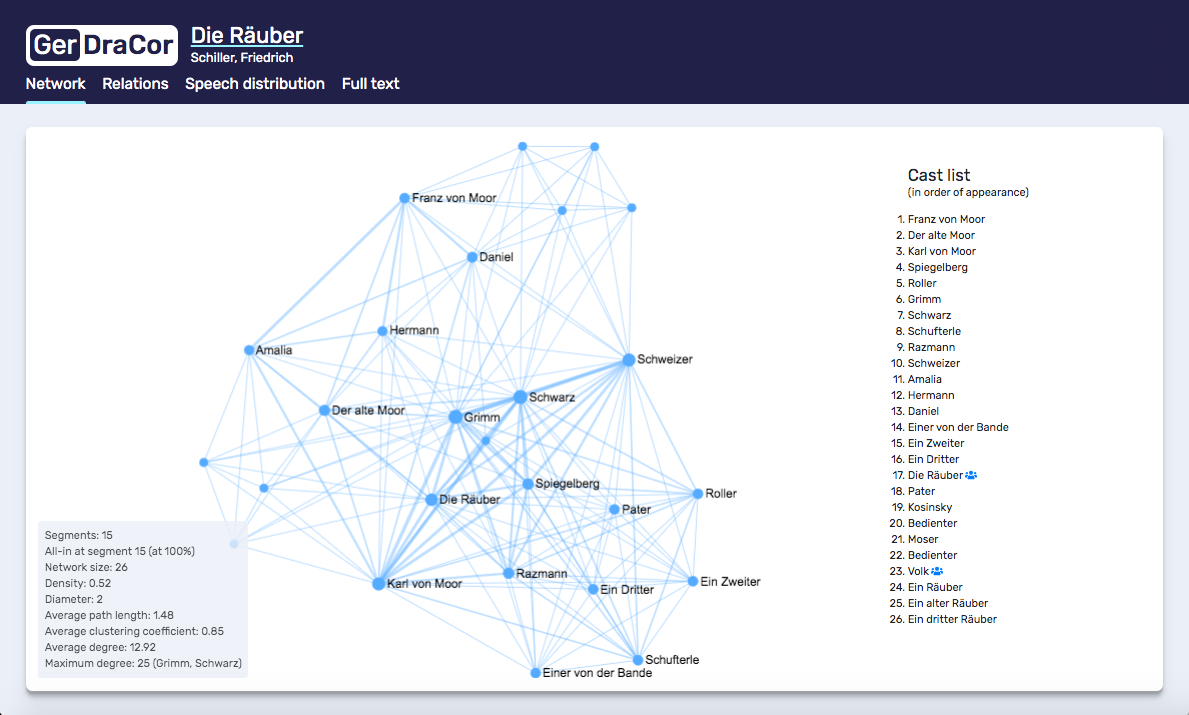
Die gesuchten Texte finden Sie in DraCor sehr schnell (s. Abschnitt 4 dieses Beitrags). Ein Klick auf den Titel des jeweiligen Dramas öffnet das entsprechende Netzwerk (vgl. Abb. 2), in das Sie beliebig hineinzoomen können. Um zu verdeutlichen, dass eine Netzwerkvisualisierung immer eine Interpretation von Daten ist und z. B. die Position der Figurennamen auf der Fläche keine Rolle spielt (im Gegensatz zu ihren Verbindungen), sieht das jeweilige Netzwerk zu einem Stück bei jedem Aufruf etwas anders aus (vgl. → Textvisualisierung).
Klicken Sie im Menü unter „Tools" auf „API”, gelangen Sie zu den zahlreichen Möglichkeiten, mehrere oder einzelne Texte (bzw. auch Textteile) in unterschiedlichen Formen und Formaten zu exportieren (verschiedene Metadaten, TEI, Figuren, verschiedene Listen). Diese Funktionen können eine erhebliche Zeitersparnis bedeuten, wenn Sie an bestimmten Aspekten der Dramentexte interessiert sind.
In den Grundfunktionen (Textsuche, Netzwerkgenerierung, Download von Netzwerkdaten als CSV-Datei oder im → Gephi-kompatiblen GEXF) funktioniert DraCor sehr intuitiv. Die Arbeit mit der API-Seite (vgl. Abb. 3) kann zu Beginn eine Herausforderung darstellen, wird mit der Zeit aber handhabbar.

Auf der GitHub-Seite von DraCor gibt es für das deutschsprachige Dramenkorpus ein Wiki, das Notizen zu einzelnen Dramen enthält (z. B.: „Zwischen Franz und Karl wird wegen IV/2 eine Relation hergestellt. Aber eigentlich begegnen sie sich gar nicht” für Die Räuber) sowie eine Dokumentation der Veränderungen im Zuge des Imports von TextGrid bereitstellt. Über GitHub bzw. die API-Seite („contact the developer”) können Sie die Herausgeber von DraCor zudem per Email kontaktieren.
Für Texte, die Sie nicht in DraCor finden, können Sie sehr leicht selbst ein entsprechendes Netzwerk aufbauen. Das Tool → Ezlinavis (bzw. Easy Linavis) existierte bereits vor DraCor und ist auf der DraCor-Seite im Menü unter „Tools" verlinkt. Es bietet die Möglichkeit, Netzwerke zügig und gänzlich ohne technische Vorkenntnisse zu erstellen.
4. Wie funktioniert die Textsuche in DraCor?
Auf der Startseite entscheiden Sie sich für eine der angebotenen Textsammlungen, die Sie mit einem Klick öffnen können. Dort haben Sie die Möglichkeit, die aufgeführten Dramen per Eingabe im Suchfeld oben zu suchen oder nach Autor*in, Titel, Netzwerkgröße, Erscheinungsjahr (generiert aus Entstehungsjahr, Premierenjahr und Druckjahr) oder Textquelle neu zu sortieren, indem Sie auf den entsprechenden Reiter klicken (siehe Abbildung 4). Die Suche einzelner Texte über die Suchleiste funktioniert sehr schnell. Ein Klick auf den Titel des jeweiligen Dramas öffnet das entsprechende Netzwerk.
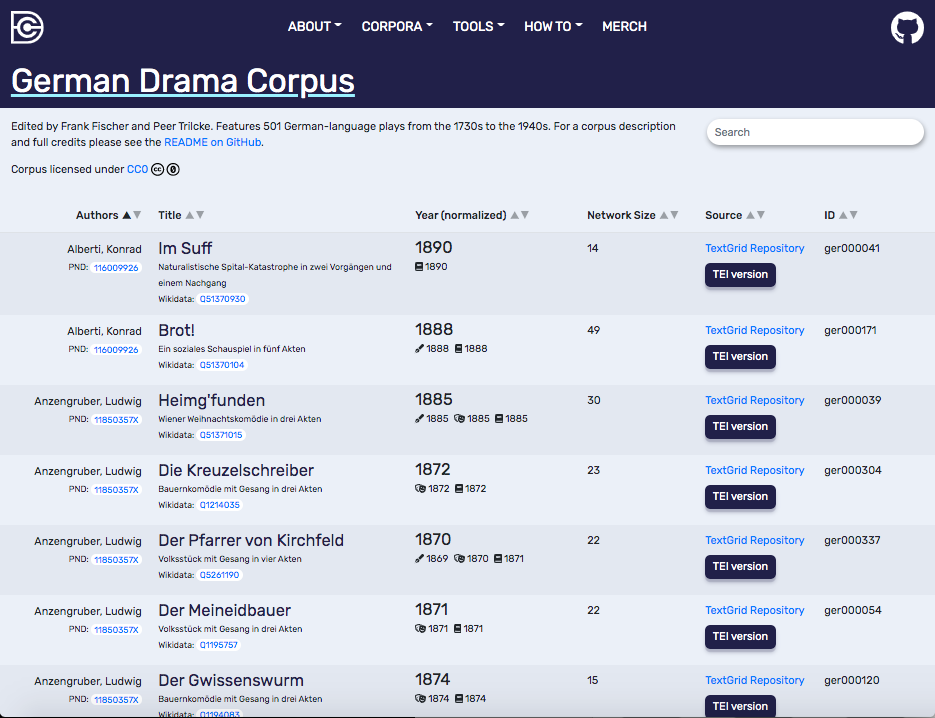
Um sich die von Ihnen präferierte Form des Textes (bspw. die weibliche Figurenrede) downloaden zu können, gehen Sie auf die API-Seite, klicken (in diesem Fall bei „Get spoken text of a play (excluding stage directions)”) auf „GET” und dann auf „Try it out” und füllen die entsprechende Suchmaske aus. Die für eine erfolgreiche API-Abfrage benötigte Form des „corpusname” sowie des „playname” folgt einem Schema, das Sie in jeder URL der Dramennetzwerke wiederfinden können. Das German Drama Corpus hat bspw. das Kürzel „ger”, Schillers Räuber das Kürzel „schiller-die-raeuber”, woraus sich die URL dracor.org/ger/schiller-die-raeuber ergibt. Nach einem Klick auf „Execute” erhalten Sie die angeforderten Daten zum Download.
5. Nachweise und weiterführende Literatur
- DraCor: https://dracor.org/.
- GitHub-Seite von GerDraCor: https://github.com/dracor-org/gerdracor.
- Fischer, Frank, Tatyana Orlova, German Palchikov, Irina Pavlova, Daniil Skorinkin und Natasha Tyshkevich (2017): Introducing RusDraCor. A TEI-encoded Russian Drama Corpus for the Digital Literary Studies. 2017. URL: https://dlina.github.io/presentations/2017-spb/#/ [Zugriff: 15.5.2019].
- Fischer, Frank, Ingo Börner, Mathias Göbel, Angelika Hechtl, Christopher Kittel, Carsten Milling und Peer Trilcke (2019): „Programmable Corpora - Die digitale Literaturwissenschaft zwischen Forschung und Infrastruktur am Beispiel von DraCor“. In: DHd 2019. Digital Humanities: multimedial & multimodal.Konferenzabstracts, Frankfurt am Main, 194–197. DOI: 10.5281/zenodo.2596095.
- Skorinkin, Daniil, Frank Fischer und German Palchikov (2018): „Building a Corpus for the Quantitative Research of Russian Drama: Composition, Structure, Case Studies“. In: Computational Linguistics and Intellectual Technologies: Proceedings of the International Conference “Dialogue 2018", Moscow. URL: http://www.dialog-21.ru/media/4332/skorinkind.pdf [Zugriff: 15.5.2019].
- Trilcke, Peer, Frank Fischer, Mathias Göbel und Dario Kampkaspar (2016): „Theatre Plays as ‘Small Worlds’? Network Data on the History and Typology of German Drama, 1730–1930“. In: Digital Humanities 2016. Conference Abstracts, Kraków, 385–387. URL: https://dh2016.adho.org/abstracts/360 [Zugriff: 15.5.2019].
Dieser Artikel wurde am 3.12.2020 mit Rücksprache des Autors redaktionell überarbeitet. Die vorherige Version finden Sie hier.
| Dateianhang | Größe |
|---|---|
| 2.7 MB |
