1. Kurzbeschreibung
Das Deutsche Romankorpus (DROC) versammelt 90 annotierte Fragmente deutschsprachiger Romane (jeweils ca. 200 Sätze) vom 17. bis 20. Jahrhundert. Es enthält neben automatisch generiertem Markup zu Kapiteln, Segmenten, Dependenz- und Morphologieinformationen, Wortarten (POS), Sätzen und Absätzen auch über 50.000 manuell erstellte Annotationen zu benannten Entitäten (vgl. → Named Entity Recognition (NER)), Koreferenzen, direkter Rede, sowie Sprechern und Adressaten dieser direkten Rede. Die dichte Annotation macht das DROC zu einer guten Ressource für Machine-Learning-Routinen oder die Kombination mit anderen qualitativen Annotationen. Das DROC stellt keine grafische Benutzeroberfläche zur Verfügung, zur Exploration der Daten ist daher etwas technisches Know-How (z. B. über die Formate TEI-XML oder Apache-UIMA-XMI) vonnöten.
Steckbrief
- https://gitlab2.informatik.uni-wuerzburg.de/kallimachos/DROC-Release
- 90 zufällig ausgewählte Fragmente verschiedener deutschsprachiger Romane (auch Übersetzungen); jeweils ca. 200 Sätze; insgesamt ca. 393.000 Tokens
- im Projekt Kallimachos (gefördert vom BMBF) an der Universität Würzburg hergestellt
- die Sammlung soll insbesondere bereits vorhandene automatisierte Tools in den Literaturwissenschaften unterstützen und bereichern (Machine Learning)
- Schwerpunkt: Annotation von Figurenreferenzen; enthält manuell erstellte Annotationen für knapp über 50.000 annotierte Figurenreferenzen und ihre Koreferenzen, ca. 2000 Annotationen von direkter Rede und deren jeweiligen Sprechern und Adressaten
- in zwei unterschiedlichen Dokumentformaten erhältlich: TEI-XML und Apache-UIMA-XMI; in den Metadaten werden aufgeführt: Titel, Autor, Jahr, Geschlecht der Autor*innen, Gattung, Erzählerposition, Happyend, Epoche (Jahr und Fachwissenschaft), Strömung, Originalsprache
2. Anwendungsbeispiel
Sie wollen den Einsatz direkter Rede in deutschsprachigen Romanen vergleichend untersuchen. DROC bietet Ihnen für diesen Anwendungsfall ein gründlich annotiertes Korpus aus 90 Romanfragmenten mit Figuren-, Koreferenz-, direkter-Rede- inkl. Sprecher- und Adressatenannotationen.
3. Diskussion
3.1 Kann ich das DROC für wissenschaftliche Arbeiten nutzen?
Ja. Die Texte entstammen dem → TextGrid Repository, das Preprocessing sowie Annotation- und Auswertungsregeln für das DROC werden transparent gemacht. Die Textauswahl erfolgte zufällig aus 450 kanonisierten Texten als auch aus der Sammlung „Deutsche Literatur von Frauen“. Die Fragmente aus diesen beiden Textgruppen wurden ebenfalls zufällig ausgewählt. Dieses Preprocessing wird bei Krug et al. (2018, Abschnitt 4) dokumentiert und begründet.
Die annotierten Textfragmente entstammen Romanen aus der Zeit zwischen dem 17. und dem 20. Jahrhundert, die orthographisch – bis auf neun Texte aus der Zeit von 1650–1800 – zum Großteil nicht standardisiert sind. Die Texte können anhand ihrer Metadaten gefiltert werden. Vertreten sind zu 60% männliche und zu 40% weibliche Autor*innen sowie kanonisierte und unbekannte Texte. Die Annotationen wurden mithilfe eines vorab erstellten Annotator-Agreements in der vom Kallimachos-Projekt selbst programmierten Desktop-Applikation ATHEN manuell und semi-automatisch erstellt.
Da es beim DROC um die Qualität der Metadaten und nicht um die Primärtexte geht, besteht bei den ausgewählten Texten kein Anspruch auf Vollständigkeit. Die Volltexte der Romane können bei Bedarf im Textgrid Repository eingesehen und heruntergeladen werden. Die Texte unterliegen der Creative Commons License CC-BY und können mit entsprechender Zitation als Quellenangabe genutzt werden.
Die hochwertigen Metadaten können zukünftig durch weitere qualitative Annotationen ergänzt werden. So wurde beispielsweise bereits ein Subset von 30 Romanfragmenten des DROC für ein → kollaboratives Annotationsprojekt zur Klassifikation von Textsorten (deskriptiv, argumentativ oder narrativ) genutzt (vgl. Schlör et al. 2019). Die Kombination unterschiedlicher qualitativer Annotationen in einer Ressource eröffnet die Möglichkeit, neue Fragestellungen digital zu erforschen.
3.2 Wie benutzerfreundlich ist die Arbeit mit dem DROC?
Die Arbeit mit den Texten und Annotationen des DROC setzt technische Kenntnisse voraus. Die Strukturen der beiden Datenformate TEI-XML und Apache-UIMA-XMI machen eine Einarbeitung erforderlich, die für die Arbeit mit dem DROC derzeit unumgänglich ist. Das Korpus können Sie in seinen beiden Formaten von der Plattform GitHub herunterladen, deren Nutzung ebenfalls einer gewissen Einarbeitung bedarf.
4. Wie funktioniert die Textsuche im DROC?
Um das Korpus beispielsweise im TEI-XML-Format herunterzuladen, klicken Sie hier und wählen auf der GitHub-Seite dann – wie in Abbildung 2 gezeigt – den Zip-Download oben rechts unter „Download this directory” aus.
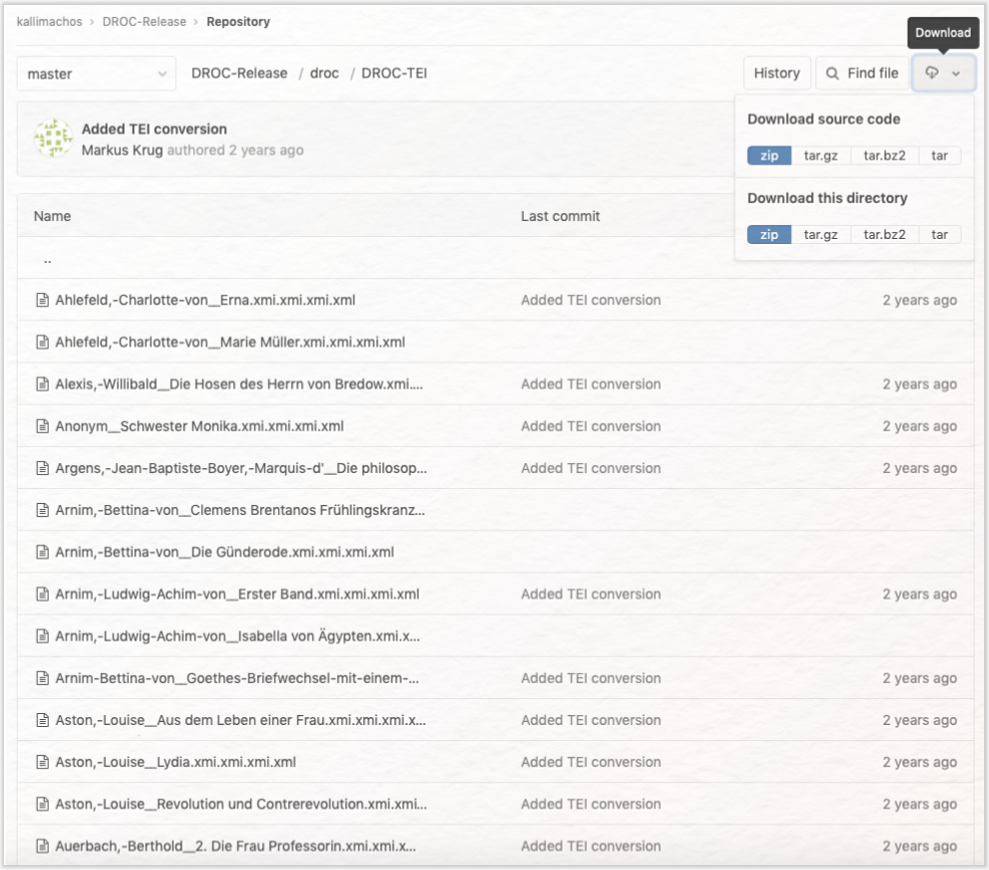
In der oberen Zeile können Sie zudem durch die einzelnen Seiten des GitHub-Repositorys navigieren. Unter DROC-Release finden Sie beispielsweise eine README-Datei, die (auf englisch) grundlegende Informationen über das DROC versammelt. Wenn Sie an einem bestimmten Romanfragment interessiert sind, können Sie auch einfach den „Find file”-Button oben rechts bedienen und die Freitextsuchzeile ausfüllen.
5. Nachweise und weiterführende Literatur
- Krug, Markus, Frank Puppe, Isabella Reger, Lukas Weimer, Luisa Macharowsky, Stephan Feldhaus und Fotis Jannidis (2018): „Description of a Corpus of Character References in German Novels - DROC [Deutsches ROman Corpus]“. In: Text abrufbar unter: http://nbn-resolving.de/urn:nbn:de:gbv:7-dariah-2018-2-9 (Zugriff am 5.8.2019).
- Schlör, Daniel, Christof Schöch und Andreas Hotho (2019): „Classification of Text-Types in German Novels“. In: Digital Humanities 2019 Conference Papers. DOI: 10.34894/OMLKRN.
