1. Kurzbeschreibung
Das KOLIMO (Korpus der literarischen Moderne) versammelt deutschsprachige narrative, fiktionale Erzähltexte der literarischen Moderne aus den Textsammlungen → Deutsches Textarchiv (DTA), → TextGrid Repository und Gutenberg, vereinheitlicht die bestehenden Metadaten und fügt weitere hinzu, um epochenspezifische und aufgrund einheitlicher Daten verlässliche Abfrageergebnisse erhalten zu können.
Steckbrief
- https://kolimo.uni-goettingen.de/index.html
- großes Spektrum der literarischen Moderne: literarische und nicht-literarische Texte sowie Vergleichstexte früherer Epochen
- Teil des laufenden Projekts Q-LIMO (Quantitative Analyse der literarischen Moderne)
- seit Herbst 2016 ist die Beta-Version veröffentlicht
- Quellen: TextGrid Repository, Gutenberg-DE, Deutsches Textarchiv (DTA), Kafka-Referenzkorpus
- konsistente und manuell erweiterte Metadaten zu bspw. Autor, Publikationsdatum und Gattung und grundlegende linguistische Annotation
- Textsorten: verschiedenen Genres narrativer/fiktionaler Texte
- Ziel: Ermöglichung des synchronen und diachronen Vergleichs einer literarischen Epoche
- Downloadformate: XML/ TXT; das KOLIMO kann auch heruntergeladen und unabhängig von der grafischen Benutzeroberfläche verwendet werden: https://kolimo.uni-goettingen.de/public/ (die README.txt-Dateien erläutern Ihnen, welche Daten im jeweiligen Ordner zu finden sind)
2. Anwendungsbeispiel
Sie wollen untersuchen, wie sich der Stil narrativer Texte der literarischen Moderne gegenüber ihren Vorgängerepochen unterscheidet.
Für eine derartige Fragestellung bietet sich die Arbeit im KOLIMO an. Durch die Konzentration auf diese spezifische Epoche ist es dem KOLIMO möglich, relevante Texte aus diversen anderen Textsammlungen in sich zu vereinen und vergleichbare Metadaten zur Verfügung zu stellen. So ist es Ihnen möglich, vergleichende quantitative Abfragen durchzuführen, die sich auf eine repräsentative Textmenge beziehen. Zudem bietet Ihnen KOLIMO die Möglichkeit, literarische mit nicht-literarischen narrativen Texten der Epoche oder mit Texten aus der Zeit vor der literarischen Moderne zu vergleichen.
3. Diskussion
3.1 Kann ich das KOLIMO für wissenschaftliche Arbeiten nutzen?
Ja, aber mit etwas Vorsicht.
Die Texte im KOLIMO werden aus unterschiedlichen Quellen bezogen: TextGrid, Gutenberg-DE, DTA und dem Kafka-Referenzkorpus. Das Problem dabei ist, dass die importierten Ressourcen in qualitativer Hinsicht stark variieren – die Texte aus Gutenberg sind generell nicht wissenschaftlich zitierfähig. Das KOLIMO eignet sich daher besonders für quantitative Vergleichsanalysen in Form eines distant reading. Sollten Sie einen bestimmten digitalisierten Text für ein zitierfähiges close reading suchen, schauen Sie entweder genau in den Metadaten des jeweiligen Textes nach (im sog. TEI-Header), aus welcher Quelle das Digitalisat stammt, oder suchen Sie direkt in einer der enthaltenen zitierfähigen Textsammlungen.
Das KOLIMO erhebt jedoch mit großer Mühe einheitliche und vergleichbare Metadaten für alle enthaltenen Texte und hat dafür einige verbindliche Richtlinien festgelegt: Die Metadaten eines jeden Dokumentes werden aus der ursprünglichen Textquelle übernommen und unter Einhaltung des DTA-Basisformats TEI ergänzt. Dazu werden beispielsweise fehlende Erscheinungsdaten recherchiert oder unterschiedliche Gattungsangaben vereinheitlicht. Neben der öffentlichen Zugriffsmöglichkeit durch die Speicherung auf einem eigenen Server wird zur nachhaltigen Langzeitarchivierung ein Datenbankabbild gespeichert.
Die Texte selbst sollen vor allem dem stilistischen Vergleich dienen und wurden dafür automatisierten linguistischen Annotationen unterzogen. Um eine höhere Genauigkeit der Wortart-Annotationen zu gewährleisten, hat das KOLIMO mehrere POS-Tagger eingesetzt und pro Register nur den Tagger mit den jeweils besten Ergebnissen verwendet. So wurde eine epochensensitive POS-Annotation erzeugt. Als Epochen wurden unter Zuhilfenahme von Literaturgeschichten Moderne, Barock, Aufklärung, Romantik und Realismus festgelegt.
3.2 Wie benutzerfreundlich ist die Arbeit mit dem KOLIMO?
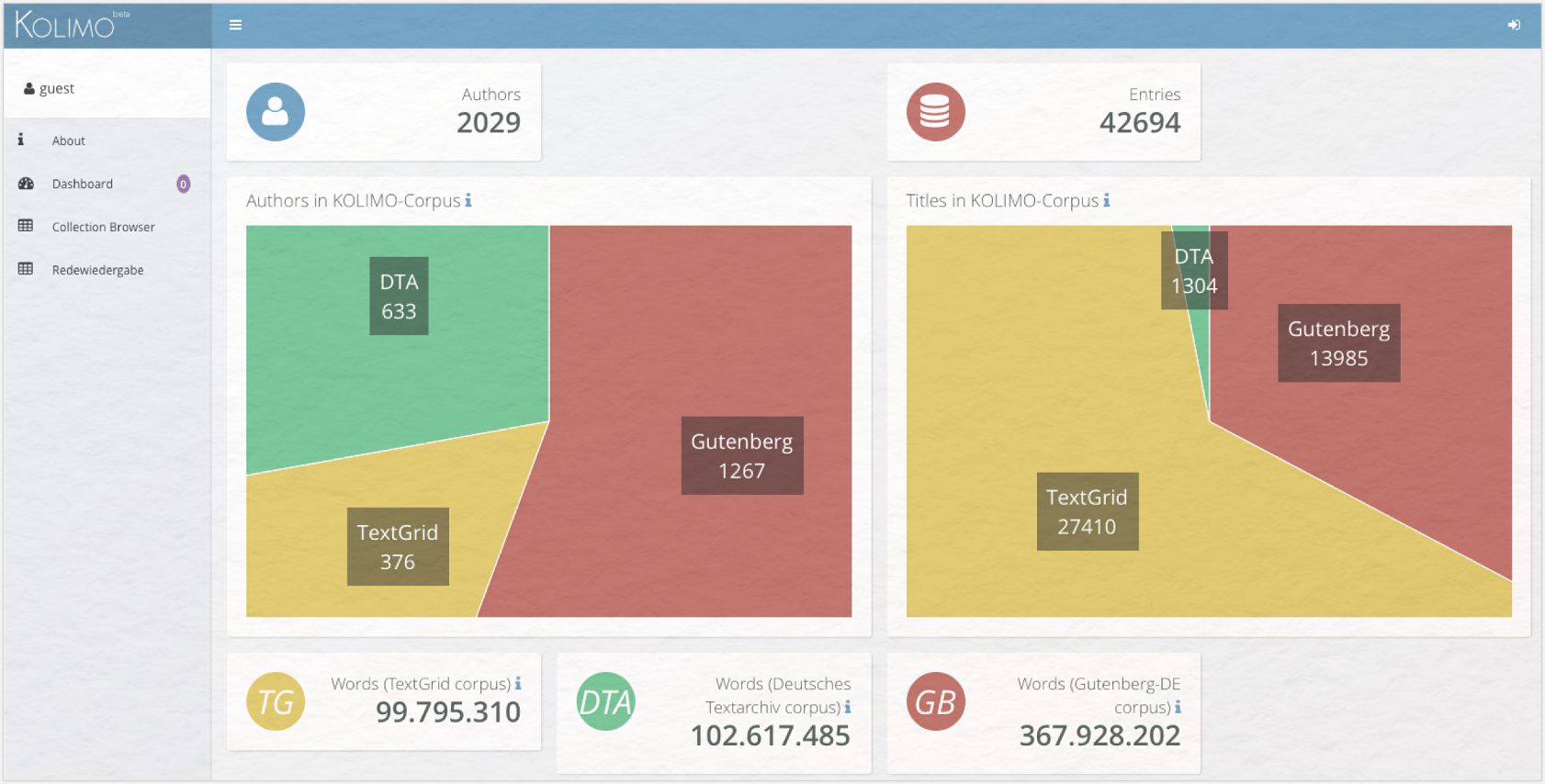
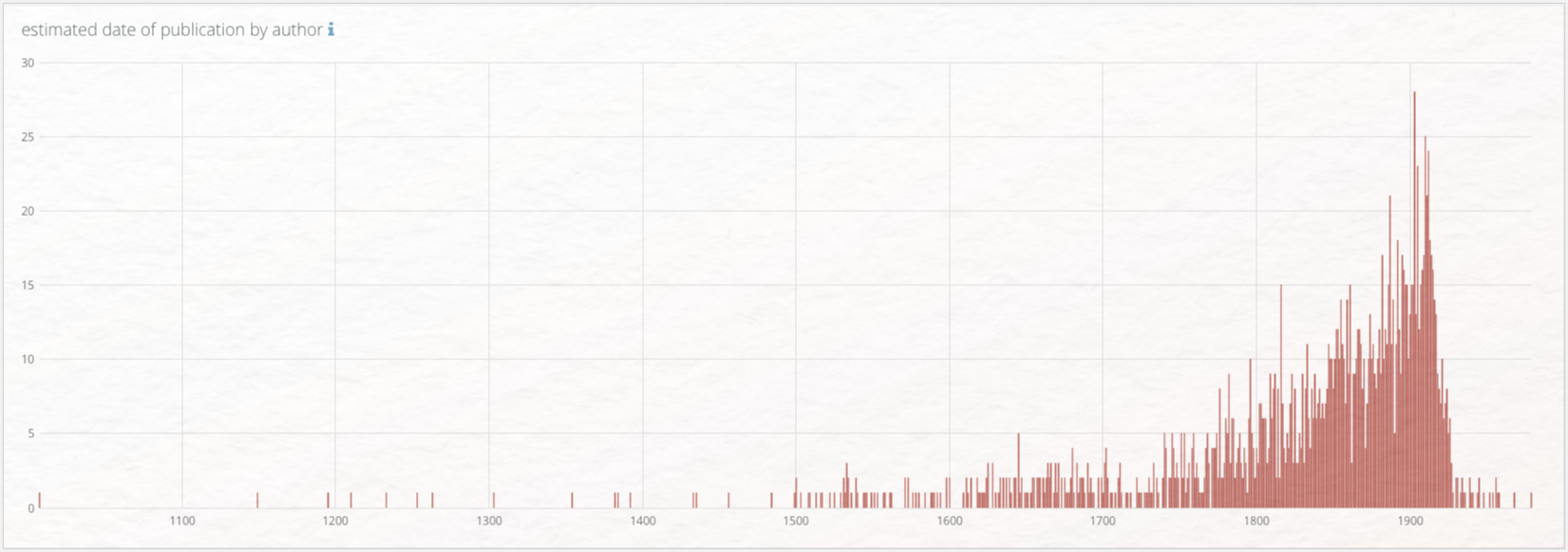
Die Startseite („Dashboard”) des KOLIMO zeigt eine Übersicht über die Anzahl der Autoren, Titel und Wörter pro Quelle und außerdem die zeitliche Verteilung der vertretenen Primärtexte, deren Schwerpunkt auf der Zeit um 1900 liegt.
Unter dem Navigationspunkt „About” werden das Projekt, seine Ziele und Konzeption, die Schritte der Textaufbereitung und die Lizenzbedingungen englischsprachig erklärt. Hinweise, wie die Textsammlung schrittweise verwendet werden kann, oder gar Tutorials fehlen jedoch bislang.
Die Webseite ist übersichtlich und klar strukturiert und man findet sich schnell zurecht. Es wird jedoch deutlich, dass es sich um eine Beta-Version handelt, die Textsammlung sich also noch in der Entwicklung befindet: Die Text- und Metadaten können zwar sämtlich und in unterschiedlichen Formaten heruntergeladen werden, es besteht in den Daten aber noch viel Rauschen („noise”), von dem sie weiterhin bereinigt werden sollen. Das KOLIMO-Team setzt zudem stark auf die Mitarbeit der Nutzer*innen: Es bittet bspw. um die Zusendung von Fehlermeldungen, Anregungen und digitalisierter Volltexte aus der Zeit vor 1800 (die den beschriebenen Qualitätskriterien entsprechen) an litre@gwdg.de.
4. Wie funktioniert die Textsuche im KOLIMO?
Unter dem Menüpunkt „Collection Browser” gelangen Sie auf die intuitive Suchmaske für die Volltexte. Hier können Sie bspw. nach Autoren, Titeln, Veröffentlichungsdaten, Genres (externe Kategorien aus dem DTA, TextGrid und Gutenberg), Epochen (Realismus, Moderne) und Textlängen (von KOLIMO implementiert) suchen. Einige Suchanfragen bedürfen hier momentan noch weiterer Programmierung seitens des KOLIMO-Teams. Mit der Plustaste lassen sich auch kombinierte Abfragen zu diesen Kategorien starten. Das Seitensymbol jeweils rechts neben den einzelnen Einträgen der Ergebnisliste bringt Sie dann zu den Volltexten.
5. Nachweise und weiterführende Literatur
- Herrmann, J. Berenike und Gerhard Lauer (2016): „Aufbau und Annotation des Kafka/Referenzkorpus“. In: DHd 2016. Modellierung – Vernetzung – Visualisierung. Die Digital Humanities als fächerübergreifendes Forschungsparadigma. Konferenzabstracts, Universität Leipzig, 158–160. URL: http://www.dhd2016.de/boa.pdf [Zugriff: 20.12.2018].
- Herrmann, J. Berenike und Gerhard Lauer (2016): „KAREK. Building and Annotating a Kafka/Reference Corpus“. In: Digital Humanities 2016: Conference Abstracts, Kraków, 552–553. URL: http://dh2016.adho.org/abstracts/427 [Zugriff: 20.12.2018].
- Herrmann, J. Berenike und Gerhard Lauer (2017): „Das ,Was-bisher-geschah’ von KOLIMO. Ein Update zum Korpus der literarischen Moderne“. In: DHd 2017: Digitale Nachhaltigkeit. Konferenzabstracts, Universität Bern, 107–110. URL: http://www.dhd2017.ch/wp-content/uploads/2017/02/Abstractband_ergaenzt.pdf [Zugriff: 20.12.2018].
