Systemanforderungen: Nutzbar mit Linux (empfohlen), Windows und MacOS
Stand der Entwicklung: OCR4all läuft in der ersten Produktivversion, die kontinuierlich verbessert wird
Herausgeber: Universität Würzburg
Lizenz: Kostenfrei zugänglich
Weblink: https://www.ocr4all.org/
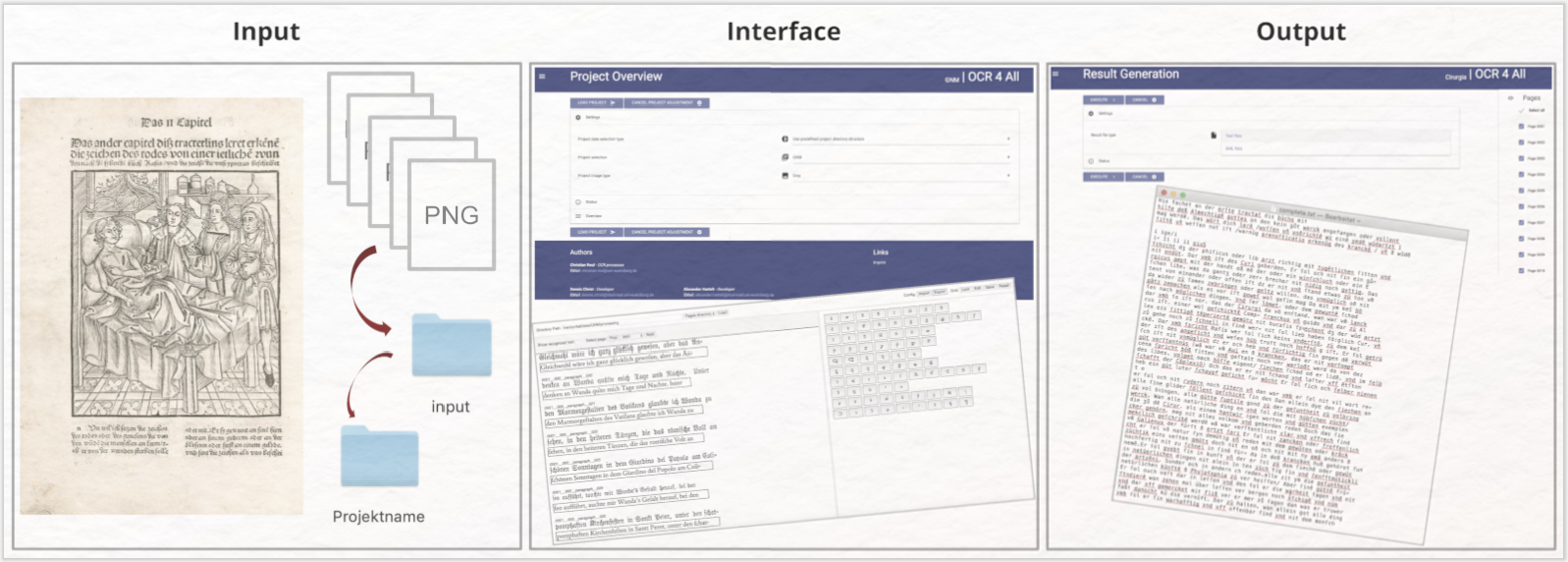
Im- und Export: Als Importformate eignen sich sowohl Bildformate (z. B. PNG, JPG) als auch das PDF-Format, Texte können im TXT- oder XML-Format gespeichert werden
Sprachen: Erkennung von über 200 Sprachen (u.a. Latein, Deutsch, Französisch, Niederländisch)
1. Für welche Fragestellungen kann OCR4all eingesetzt werden?
OCR4all erleichtert die → Digitalisierung historischer Drucke und ermöglicht die Texterkennung unterschiedlicher Schrifttypen. Das OCR4all-Texterkennungstool könnte besonders gut für ein Forschungsprojekt eingesetzt werden, in dem historische Faksimiles die Untersuchungsgegenstände darstellen. Mit Hilfe des Tools können beispielsweise Texte auf Handzetteln von Theatervorführungen aus dem 19. Jahrhundert erkannt werden, um diese dann miteinander abzugleichen. Mit Hilfe eigener Verbesserungen, durch die das Tool lernt, können auch weitaus ältere Texte computerlesbar gemacht werden. Eine weitere mögliche Fragestellung wäre z. B.: Welche Persönlichkeiten wurden besonders häufig in Schriften des frühen Protestantismus erwähnt?
2. Welche Funktionalitäten bietet OCR4all und wie zuverlässig ist das Tool?
Funktionen (Auswahl):
- Integration gängiger und sehr mächtiger Texterkennungsprogramme in eine einheitliche Benutzeroberfläche
- Automatische Texterkennung in Scans von Fraktur- und Antiquaschriften aus dem 19. Jahrhundert
- Semi-automatische Erkennung frühneuzeitlicher gedruckter Texte
- Preprocessing der Scans (z. B. Erkennung der Schriftbereiche in binären und graustufigen Bildern, Umrechnen schief eingescannter Textbereiche in gerade Textblöcke)
- Segmentierung
- Erkennung von Layout und Textregionen sowie Textzeilen, dazu eine Korrekturoberfläche zur Verbesserung der Ergebnisse
- Zeichenerkennung auf Grundlage von Zeilenbildern, die im Layout erkannt bzw. festgelegt wurden
- Abschließende Textkorrektur
- Training eigener, projektspezifischer OCR-Modelle
- Evaluation der eigenen Korrektur- und Trainingsarbeit
Zuverlässigkeit: OCR4all ist ein schnell und zuverlässig laufendes Texterkennungstool. Die Qualität der gespeicherten Textdokumente hängt stark von der Bildqualität der eingescannten Faksimiles ab. Mit einem iterativen Ansatz, bei dem die Ergebnisse in mehreren Durchläufen verbessert werden und das Tool dabei für die projektspezifischen Materialien optimiert wird, erreicht OCR4all Erkennungsquoten von bis zu 99,5%.
3. Ist OCR4all für DH-Einsteiger*innen geeignet?
| Checkliste | √ / teilweise / – |
|---|---|
| Methodische Nähe zur traditionellen Literaturwissenschaft | √ |
| Grafische Benutzeroberfläche | √ |
| Intuitive Bedienbarkeit | teilweise |
| Leichter Einstieg | teilweise |
| Handbuch vorhanden | √ |
| Handbuch aktuell | √ |
| Tutorials vorhanden | teilweise |
| Erklärung von Fachbegriffen | √ |
| Gibt es eine gute Nutzerbetreuung? | √ |
Die Entwickler von OCR4all haben es sich zur Aufgabe gemacht, einen Einstieg in die Texterkennung zu bieten, der besonders für Nutzer*innen ohne Vorkenntnisse geeignet ist. Dieses Ziel erreichen sie mit einer gut strukturierten grafischen Benutzeroberfläche, Handbüchern in Deutsch und Englisch und einer sehr zugewandten Nutzerbetreuung. Allerdings läuft OCR4all in einer Docker-Umgebung, die vor der Nutzung auf dem eigenen PC eingerichtet werden muss. Für diese Einrichtung werden Commandline-Programme benötigt, deren Verwendung für wenig technikaffine Nutzer*innen ungewohnt sein kann. Gleiches gilt für die Vorgänge des Daten-Up- und -Downloads, die über die computerinterne Ordnerstruktur geregelt werden. Die von OCR4all bereitgestellten Tutorials zur Einrichtung des Programmes decken derzeit Linux- und Windows-, nicht aber Mac-Umgebungen ab.
4. Wie etabliert ist OCR4all in den (Literatur-)Wissenschaften?
OCR4all wurde im Jahr 2019 herausgebracht. Es handelt sich folglich um eine Neuerscheinung, bei der sich zeigen wird, wie kompatibel das Werkzeug mit den Ansprüchen der Fachgemeinschaft ist. Es arbeiten bereits zahlreiche, auch eher traditionell arbeitende Geisteswissenschaftler*innen, mit OCR4all. In wissenschaftlichen Veröffentlichungen wird das Tool bisher allerdings noch nicht erwähnt. Eine Publikation zur Entwicklung von OCR4all wird derzeit vorbereitet.
5. Unterstützt OCR4all kollaboratives Arbeiten?
OCR4all wurde für die Benutzung durch einzelne Nutzer*innen entwickelt, kann allerdings auch gemeinsam genutzt werden, wenn das Tool auf einem durch ein Passwort geschützten Server installiert wird.
6. Sind meine Daten bei OCR4all sicher?
Ja, wenn Sie die von OCR4all genutzte Container-Software Docker lokal auf Ihrem Computer installieren und keinen Web-Zugang wählen. Während der Installation von OCR4all installieren Sie einen Docker-Container auf Ihrem PC. Dabei handelt es sich um einen Teil ihres Arbeitsspeichers, der eingekapselt wird und über den die Installationsdaten über ein mit Hilfe von Docker geteiltes Laufwerk ausgetauscht werden. Um die Installation durchführen zu können, ist ein Admin-Zugriff auf Ihren Computer notwendig. Theoretisch birgt dieses Verfahren die Gefahr, dass auch schadhafte Dateien auf Ihrem System eingerichtet werden könnten. Da OCR4all an der Universität Würzburg entwickelt wurde und somit nur Daten (bzw. Updates) von regionalen Servern zu ihnen gelangen, die hohen Sicherheitsanforderungen genügen, ist diese Gefahr allerdings sehr gering.
Ihre Bild-und Textdaten bleiben auf Ihrem eigenen System. Ausschließlich Nutzer*innen Ihres Computers können darauf zugreifen. Selbst wenn Sie OCR4all auf einem Server installieren und kollaborativ nutzen, haben nur diejenigen Zugang zu den hier abgelegten Daten, die auf den Server zugreifen können. Aus urheberrechtlicher Sicht ist die Nutzung von OCR4all also vollkommen unbedenklich.
