Auf dieser Seite bieten wir Ihnen Informationen zu digitalen Methoden (in alphabetischer Reihenfolge), die verschiedene literaturwissenschafltiche Arbeitsschritte digital unterstützen. Von der Digitalisierung und Recherche von Literatur, über die Analyse und Interpretation von Texten (bspw. zum manuellen Annotieren, zu Topic Modeling, zur Netzwerkanalyse etc.) hin zu Möglichkeiten der digital unterstützten Präsentation und Publikation. In diesen Informationstexten finden Sie darüber hinaus Links zu digitalen Tools, mithilfe derer die jeweiligen Methoden ausgeführt werden können.
Digitale Editionen

Digitale Editionen machen historische Dokumente für ein breites (wissenschaftliches) Publikum verfügbar und bilden damit die Basis für weitere Untersuchungen. Grundsätzlich können neben Textdokumenten auch kulturelle Artefakte in anderen medialen Formen wie audiovisuelle Medien oder bildnerische Objekte zum Gegenstand von Editionen werden. In der Literaturwissenschaft liegt der Fokus allerdings auf der Edition historischer Drucke und Handschriften. Sie werden in digitalen Editionen als digitale Faksimiles sowie als maschinenlesbare Transkripte repräsentiert und mit weiteren Informationen zu Überlieferung, relevanten Entitäten, Inhalten und/oder materiellen Besonderheiten angereichert. Die Bereitstellung erfolgt heutzutage zumeist über ein Online-Portal, wo die Dokumente im Open Access direkt rezipiert sowie (annotierte) Transkriptionen und Metadaten heruntergeladen werden können. Digitale Editionen sind nicht mit digitalen Repositorien zu verwechseln, die in der Regel nur einen maschinenlesbaren Text ohne Anbindung an die Überlieferung zur Verfügung stellen und nur wenig bis keine weiteren Informationen zum Text geben.
Editionen sind immer gleichzeitig Ergebnis wissenschaftlicher Arbeit und Basis für weitere Forschung. Um beide Perspektiven geht es im Folgenden.
Digitale Manuskriptanalyse

Die digitale Manuskriptanalyse beschäftigt sich mit der Auszeichnung bzw. Annotation kultureller Artefakte in Form eingescannter Handschriften.
Digitales Bibliografieren

Die Ermittlung von Forschungsliteratur und deren Organisation in Literaturverzeichnissen stellen eine essentielle Grundlage des wissenschaftlichen Arbeitens in sämtlichen Fachdisziplinen dar. Der Nachweis von Literatur erfolgt u. a. mithilfe von elektronischen Datenbanken, die über das Internet erreichbar sind und hochperformante digitale Tools stellen eine elektronische Alternative zur analogen Literaturverwaltung dar.
Digitales Präsentieren und Publizieren
 und digitale Präsentation von visuell aufbereiteten Forschungsergebnissen (Graph-Visualisierung mit Sigmajs von Martin Grandjean 2014, Netzwerk der Korrespondenz von Mitgliedern des Internationalen Instituts für geistige Zusammenarbeit von 1926–1946)")
Wissenschaftliches Präsentieren, Publizieren und Kommunizieren sind einem fortlaufenden Entwicklungsprozess unterworfen und werden in unterschiedlichen Ausprägungen digital unterstützt. Digitale Formen der Präsentation und Publikation von Forschungsergebnissen haben nicht zu unterschätzende Auswirkungen auf diesen wichtigen Bestandteil des wissenschaftlichen Forschungsprozesses und bergen Chancen ebenso wie Herausforderungen. Die Kanäle, über die hierbei kommuniziert wird, werden immer vielfältiger. Gleichzeitig nimmt die adäquate Aufbereitung der Forschungsergebnisse einen hohen Stellenwert ein.
Entwicklung von Kategoriensystemen
Unter der Entwicklung von Kategoriensystemen ist die Erstellung einer terminologischen Ordnungssystematik zur Erfassung eines Gegenstandsbereichs zu verstehen. Ontologien, Taxonomien, Typologien und kontrollierte Vokabulare sind häufig verwendete Typen von Kategoriensystemen, die sich, abhängig vom Anwendungszweck und den beteiligten wissenschaftlichen Disziplinen, hinsichtlich ihrer Definitionen und Abgrenzungen voneinander unterscheiden. In textbasierten geisteswissenschaftlichen Disziplinen wie der Literaturwissenschaft können Kategoriensysteme z. B. der Klassifikation ganzer Werke oder der Kategorisierung einzelner Textphänomene dienen.
Kollaboratives literaturwissenschaftliches Annotieren

Unter kollaborativem literaturwissenschaftlichem Annotieren ist eine Praxis kooperativen Arbeitens zu verstehen, bei der sich mehrere Forschende gemeinsam der Annotation literarischer Texte annehmen. Während hierbei unterschiedliche Modi der Kooperation möglich sind, widmet sich der vorliegende Beitrag ausschließlich einer spezifischen Unterform des kollaborativen Annotierens: der gemeinsamen Arbeit an derselben Textgrundlage vor dem Hintergrund derselben Fragestellung.
Korpusbildung

Ein digitales Korpus ist eine maschinenlesbare Sammlung von Texten, die die empirische Grundlage Ihrer Untersuchungen im Feld digitaler Literaturwissenschaft bildet. Folglich konzipieren Sie es meist bereits mit einem Ziel oder einer Fragestellung. Je nach Methode oder Disziplin variieren die Textanzahl und nötigen Vorbereitungen.
Manuelle Annotation

Unter (digitalem) manuellem Annotieren versteht man die Praxis, in Texten digital Hervorhebungen oder Anmerkungen anzubringen. Diese können ganz unterschiedlichen Zwecken dienen – beispielsweise der Strukturierung von Texten, ihrer sprachlichen oder inhaltlichen Beschreibung, ihrer Kontextualisierung oder Interpretation.
Möglichkeiten der Textdigitalisierung

Textdigitalisierung bezeichnet den Prozess der Umwandlung eines gedruckten oder handschriftlichen Textes in einen maschinell lesbaren elektronischen Text. Je nach Beschaffenheit des Ausgangstextes kommen in diesem Prozess der Texterfassung bzw. Transkription mehrere potentielle Bearbeitungsschritte in Frage – automatisierte (optical character recognition (OCR): optische Zeichenerkennung) wie manuelle (keying).
Named Entity Recognition (NER)
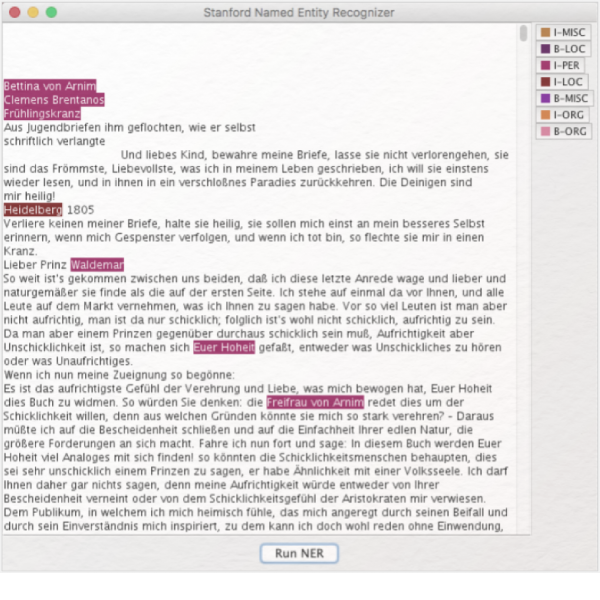
Named Entity Recognition (NER) ist ein Verfahren, mit dem klar benennbare Elemente (z.B. Namen von Personen oder Orten) in einem Text automatisch markiert werden können. Named Entity Recognition wurde im Rahmen der computerlinguistischen Methode des Natural Language Processing (NLP) entwickelt, bei der es darum geht, natürlichsprachliche Gesetzmäßigkeiten maschinenlesbar aufzubereiten.
Netzwerkanalyse
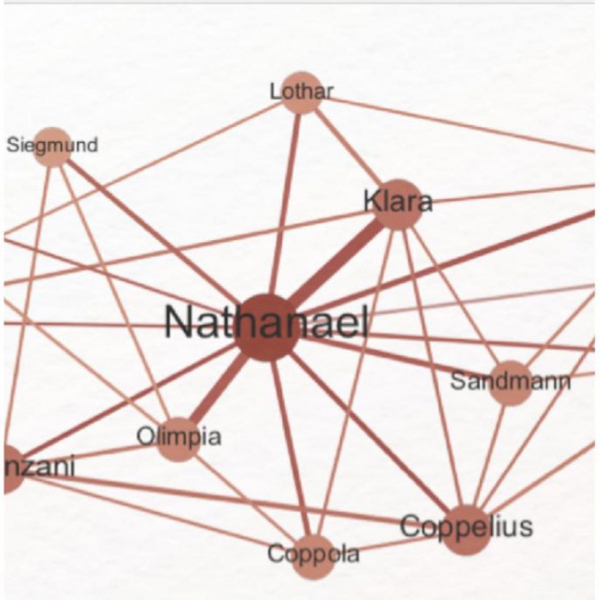
Netzwerkanalyse ist eine Methode, bei der eine Fragestellung im Zentrum steht, in der es um die Relationen zwischen definierten Elementen geht (wie z. B. um die Figurenkonstellation in einem literarischen Werk). Solche Relationen stellt man sich in Form eines Netzwerks vor, das aus zuvor definierten Eckpunkten (Knoten) und deren Verbindungen untereinander (Kanten) aufgebaut wird. Im Mittelpunkt der Betrachtung stehen damit ein Beziehungsgeflecht und dessen quantitative und qualitative Merkmale.
Projektkonzeption
.")
Unter die Konzeption wissenschaftlicher Projekte, seien es Artikel, Abschlussarbeiten oder Vorträge, fallen das Ausmachen eines Forschungsgegenstandes, die Wahl einer angemessenen Fragestellung und Methodik sowie die Koordination von Untersuchungsmaterial und zur Verfügung stehender Zeit. In jedem dieser Schritte können Sie digitale Tools und Methoden gewinnbringend einsetzen.
Sentimentanalyse
: Sentimentanalyse analysiert die schriftspracheliche Manifestation von Emotionen.")
Die Realisierung von Emotionen erfolgt nonverbal (z. B. über die Mimik Gustaf Gründgens und Will Quadfliegs), über körperliche Zustände (wie z. B. die Schweißperlen auf Quadfliegs Stirn, Lachen oder Weinen) oder verbal (in Goethes Faust auf Wort-, Satz- und Textebene mittels Interjektionen, Gefühlswörtern oder Exklamativsätzen). Sentimentanalysen zielen auf die Analyse schriftlich kodierter Gefühle ab. Im Kern geht es um die Prädiktion schriftlich explizit oder implizit kodierter Meinungen, Gefühle, Einstellungen, Bewertungen oder Emotionen. Im Rahmen dessen werden z. B. Valenz oder Polarität eines Textes ermittelt und untersucht, ob im Text ein überwiegend positives oder negatives Gefühl zum Ausdruck gebracht wird.
Stilometrie

In der digitalen Stilometrie werden Texte oder Textpassagen auf Grundlage statistischer Verteilungen (i. d. R. der häufigsten Wörter) stilistisch miteinander verglichen. So lässt sich beispielsweise die stilistische Entwicklung oder Differenzierung eines literarischen Textes, eines Œuvres, oder gar einer ganzen Epoche quantitativ nachvollziehen. Insbesondere werden stilometrische Methoden bei Autorschaftsattributionen, Genreklassifikationen, Epochendifferenzierungen oder auch in der forensischen Linguistik eingesetzt.
Textvisualisierung
")
Die Textvisualisierung als Teilbereich der Informationsvisualisierung befasst sich mit der visuellen Repräsentation komplexer Textdaten und der Manipulierbarkeit dieser Repräsentation durch interaktive Softwareinterfaces (vgl. Card et al. 1999). Visuelle Darstellungen können neue Einsichten in Textdaten und deren innere Zusammenhänge liefern.
Textvisualisierungen unterstützen sowohl die Kommunikation von Forschungsergebnissen als auch die explorative Analysetätigkeit.
Topic Modeling

Topic Modeling ist ein auf Wahrscheinlichkeitsrechnung basierendes Verfahren zur Exploration größerer Textsammlungen. Das Verfahren erzeugt statistische Modelle (Topics) zur Abbildung häufiger gemeinsamer Vorkommnisse von Wörtern.
word2vec

word2vec ist eine computergestützte Methode, um Ähnlichkeiten zwischen Wörtern aufgrund ihrer kontextuellen Merkmale numerisch zu erfassen. Am häufigsten wird sie zur Analyse der semantischen Verbindungen zwischen Wörtern in einem Textkorpus eingesetzt. Dem Verfahren liegt eine Beobachtung über den Gebrauch von Wörtern in unserer Alltagssprache zugrunde: Semantisch ähnliche Wörter treten in ähnlichen Kontexten auf. Das Vorkommen eines Wortes kann demnach anhand seiner Kontexte (d.h. anhand seiner unmittelbaren Nachbarschaften in einem Satz) vorhergesagt werden, und umgekehrt.