Systemanforderungen: Das Tool ist webbasiert und am besten über Google Chrome oder Firefox nutzbar
Stand der Entwicklung: Entwicklung der Testdemo 2019 und 2020; Überarbeitung und Verlagerung der Endversion auf die Server der Universität Regensburg 2020
Herausgeber: Universität Regensburg: Johanna Dangel (Entwicklung) und Thomas Schmidt
Lizenz: Kostenfrei (Open Source)
Weblink: http://thomasschmidtur.pythonanywhere.com/
Im- und Export: Import von Dateien im TXT- und XML-Format; Export aller Visualisierungen im CSV-, PNG- oder XML-Format
Sprachen: Deutsch
1. Für welche Fragestellungen kann SentText eingesetzt werden?
Mit SentText können Sie deutschsprachige literarische Texte aller Epochen hinsichtlich der hierin enthaltenen positiven oder negativen Haltungen analysieren lassen. Das Tool richtet sich ausdrücklich an Nutzer*innen mit literaturwissenschaftlichen Forschungsinteressen. Im Rahmen der Entwicklung wurden entsprechende Bedarfsanalysen durchgeführt und in die Fortentwicklung integriert. Das Tool besticht u. a. durch das intuitiv bedienbare Interface, das Nutzer*innen bar methodischer Vor- oder Programmierkenntnisse einen Einstieg in die lexikonbasierte → Sentimentanalyse ermöglicht. Es eignet sich, um die Polarität (positiv, negativ, neutral) literarischer Texte zu untersuchen und darauf aufbauend Aussagen über die in einem Text vorherrschende positive oder negative Stimmung treffen zu können. Daran anschließend ließe sich nach emotionstragenden Textstrukturen fragen.
Forschungsfragen, die sich bearbeiten lassen, sind z. B.: Welche Sentiment-tragenden Wörter finden sich in Robert Musils Roman Der Mann ohne Eigenschaften und herrscht eine überwiegend positive oder negative Stimmung? Verweisen Sentiment-tragende Wörter in Franz Kafkas Die Verwandlung auf bestimmte emotionale Zustände und in welcher textuellen Gestalt erscheinen Emotionen in Kafkas Erzählung? Im Rahmen einer Korpusanalyse könnten Sie bspw. untersuchen, mit welcher Terminologie Gefühle in unterschiedlichen Epochen oder literarischen Gattungen zum Ausdruck gebracht wurden.
2. Welche Funktionalitäten bietet SentText und wie zuverlässig ist das Tool?
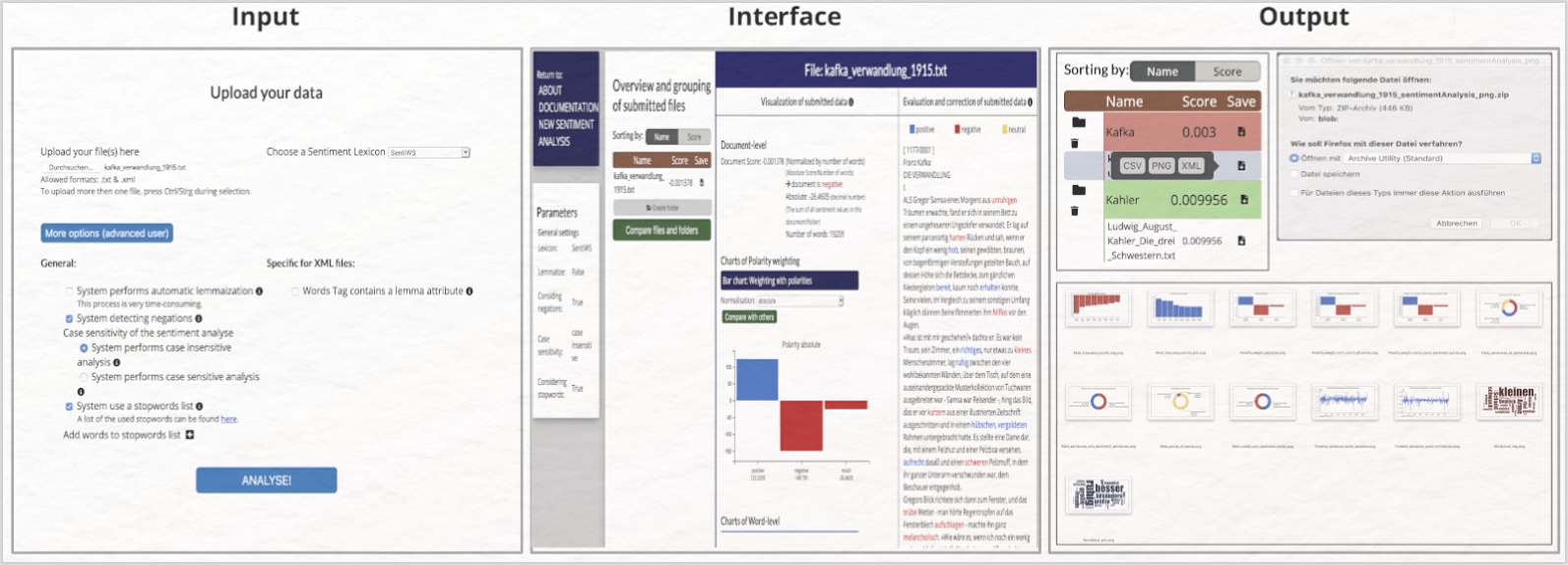
Funktionen:
- Import und lexikonbasierte Sentimentanalyse von Einzeltexten oder Textkorpora
- Auswahl aus zwei Sentimentwörterbüchern (SentiWS oder BAWL-R, darauf basiert die Berechnung der Sentimentwerte)
- Import eines zuvor selbst erstellten Sentimentwörterbuchs (im CSV-Format) als individuelle Analysegrundlage, die auf das (historische) Vokabular der Textgrundlage ausgerichtet ist
- Feinjustierung der Analyseparameter durch An- oder Ausschalten der folgenden Kenngrößen: Lemmatisierung, Negationen, Case Sensitivity, Stoppwortliste
- Manuelle Erweiterung der Stoppwortliste
- Analyseergebnisse: Berechnung des durchschnittlichen Sentimentwerts des Textes, Anzeige aller positiven (rot), negativen (blau) oder neutralen (gelb) Sentiment-tragenden Wörter und deren Sentimentwerten im gesamten Dokument
- Spezifische Informationen zum Sentimentwert eines markierten Textabschnitts
- Manuelle Korrektur: Markieren eines Wortes im Textpanel und Vergabe eines Sentimentwerts ermöglichen die manuelle Korrektur falsch erkannter bzw. die Ergänzung nicht erkannter Sentimentwörter
- Visualisierungen der Ergebnisse: Diagramme zur Gewichtung der Polarität des gesamten Textes oder Textkorpus (Barchart: absolute Polarität, normalisierte Polarität und Polaritäten der sentiment bearing words), Diagramme auf Wortebene (Kreisdiagramm: Verteilung der negativen und positiven Wörter, Wordcloud der vermehrt vorkommenden positiven und negativen Sentiment-tragenden Wörter und Barchart der acht am häufigsten auftretenden positiven bzw. negativen Wörter), Diagramme auf Satzebene (Kreisdiagramm: Verteilung der Sätze mit negativer bzw. positiver Valenz; interaktiver Zeitstrahl mit Textrückbezug: Entwicklung der Sentimente im Text oder Korpus; Verzeichnis der zehn Sätze mit den höchsten Sentimentwerten
- Organisation des Textkorpus: Überblick über gesamte Textgrundlage, Organisation aller zu Beginn hochgeladenen Texte per drag and drop zu bspw. autor*innenspezifischen Textkorpora in unterschiedlichen Ordnern, Ausführung einer vergleichenden Sentimentanalyse mehrerer Ordner (= Textkorpora) oder von Einzeltexten
- Export aller Visualisierungen der Analyseergebnisse
Zuverlässigkeit: Das Tool funktioniert zuverlässig. Bei steigender Anzahl und Größe der Textdateien nimmt der Analyseprozess mehr Zeit in Anspruch. Gleiches gilt für die Auswahl weiterer Analyseparameter wie bspw. die Lemmatisierung. Die manuelle Korrekturmöglichkeit stellt ein wichtiges Feature dar. Wird bspw. in dem Satz „Nun, die Hoffnung ist noch nicht gänzlich aufgegeben; habe ich einmal das Geld beisammen, um die Schuld der Eltern an ihn abzuzahlen – es dürfte noch fünf bis sechs Jahre dauern –, mache ich die Sache unbedingt.” „Hoffnung” aufgrund der Negation „nicht” ein negativer Sentimentwert zugewiesen, können Sie dies korrigieren – Schließlich lässt sich Hoffnung in diesem Fall durchaus als positive Empfindung interpretieren. Gleichzeitig entsteht ein didaktischer Mehrwert, da die Arbeitsweise lexikonbasierter Sentimentanalysen deutlich wird.
3. Ist SentText für DH-Einsteiger*innen geeignet?
| Checkliste | √ / teilweise / – |
|---|---|
| Methodische Nähe zur traditionellen Literaturwissenschaft | √ |
| Grafische Benutzeroberfläche | √ |
| Intuitive Bedienbarkeit | √ |
| Leichter Einstieg | √ |
| Handbuch vorhanden | teilweise |
| Handbuch aktuell | √ |
| Tutorials vorhanden | – |
| Erklärung von Fachbegriffen | √ |
| Gibt es eine gute Nutzerbetreuung? | teilweise |
Ein separates Handbuch ist nicht erhältlich, stellt aber auch keine Notwendigkeit dar. Hilfreiche Informationen für Erstnutzer*innen über Sentimentanalysen finden Sie unter „About”. Fortgeschrittene Nutzer*innen können durch die Auswahl supplementärer Analyseparameter die Standardeinstellungen verfeinern („More options (advanced user)”-Button), die Funktionen werden jeweils anhand kurzer Beispiele veranschaulicht. Beschreibungen und Anwendungshinweise zu einzelnen Elementen der grafischen Benutzeroberflächer erscheinen beim Hovern über das Info-Symbol. Sämtliche Analyseparamter können Sie unter „Documentation” einsehen. Möglichkeiten zur Kontaktaufnahme und einer persönlichen Nutzerbetreuung finden Sie unter der Rubrik „Contact”.
4. Wie etabliert ist SentText in den (Literatur-)Wissenschaften?
Da es sich bei SentText um eine Neuerscheinung handelt, konnte der literaturwissenschaftliche Mehrwert des Tools bisher noch nicht nachgewiesen werden. Obwohl derzeit keine wissenschaftlichen Artikel aus interpretativen literaturwissenschaftlichen Forschungseinrichtungen existieren, die das Tool nennen, finden literaturwissenschaftlich ausgerichtete lexikonbasierte Sentimentanalysen durchaus Anwendung (vgl. Schmidt und Burghardt 2018, Nalisnick und Baird 2013; Mohammad 2013). Für Unterstützung beim Einsatz von SentText in Forschung oder Lehre stehen die Herausgeber zur Verfügung.
5. Unterstützt SentText kollaboratives Arbeiten?
Nein, es kann nicht kollaborativ gearbeitet werden.
6. Sind meine Daten bei SentText sicher?
Ja, das Tool läuft momentan über den Server-Anbieter pythonanywhere. Im Verlauf des Jahres ist eine Übertragung auf die Informatik-Server der Universität Regensburg geplant. Für die Verwendung müssen Sie keine personenbezogenen Daten angegeben. Sobald Sie eine Sitzung schließen oder per Klick auf „NEW SENTIMENT ANALYSIS” eine weitere Analyse vornehmen, gehen Ihre Analysedaten verloren.
7. Nachweise und weiterführende Literatur
- Mohammad, Saif (2013): „From once upon a time to happily ever after: Tracking emotions in novels and fairy tales“. Text abrufbar unter: https://arxiv.org/pdf/1309.5909.pdf.
- Nalisnick, Eric T. und Henry S. Baird (2013): „Character-to-Character Sentiment Analysis in Shakespeare’s Plays“. In: Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics, Sofia, Bulgaria: Association for Computational Linguistics, 479–483.
- Schmidt, Thomas, Manuel Burghardt und Christian Wolff (2018): „Herausforderungen für Sentiment Analysis bei literarischen Texten“. In: Burghardt, Manuel; und Claudia Müller-Birn (Hrsg.). INF-DH 2018, Bonn: Gesellschaft für Informatik e.V.
- Schmidt, Thomas und Manuel Burghardt (2018): „An Evaluation of Lexicon-based Sentiment Analysis Techniques for the Plays of Gotthold Ephraim Lessing“. In: Proceedings of the Second Joint SIGHUM Workshop on Computational Linguistics for Cultural Heritage, Social Sciences, Humanities and Literature, Santa Fe, New Mexico: Association for Computational Linguistics, 139–149.
- Schmidt, Thomas, Manuel Burghardt und Katrin Dennerlein (2018): „‚Kann man denn auch nicht lachend sehr ernsthaft sein?‘ - Zum Einsatz von Sentiment Analyse-Verfahren für die quantitative Untersuchung von Lessings Dramen“. In: Book of Abstracts, DHd 2018. URL: https://epub.uni-regensburg.de/37579/1/Self-Archiving-Version_DHd-2018.pdf [Zugriff: 9.9.2019].
