Eckdaten der Lerneinheit
- Anwendungsbezug: 67 deutschsprachige Texte
- Methode: Stilometrische Analyse
- Angewendetes Tool: Stylo
- Lernziele: Installation von R, RStudio und des Stylo-Packages, Anwendung unterschiedlicher stilometrischer Analysemethoden, Interpretation der Visualisierungen
- Dauer der Lerneinheit: ca. 90 Minuten
- Schwierigkeitsgrad des Tools: mittel
Bausteine
- Anwendungsbeispiel
Welche Texte werden analysiert? Untersuchen Sie ein Korpus von 67 deutschsprachigen Texten aus dem 19. und beginnenden 20. Jahrhundert auf stilistische Verwandtschaft. - Vorarbeiten
Was muss vor der stilometrischen Analyse getan werden? Lernen Sie, wie Sie sich das Korpus herunterladen, die Software R und RStudio installieren, eine Session einrichten und das Stylo-Package hinzufügen. - Funktionen
Welche Funktionen bietet Stylo Ihnen für die stilometrische Analyse des Korpus? Lernen Sie ausgewählte Analysefunktionen von Stylo kennen und lösen Sie Beispielaufgaben. - Lösungen zu den Beispielaufgaben
Haben Sie die Beispielaufgaben richtig gelöst? Hier finden Sie Antworten.
1. Anwendungsbeispiel
In dieser Lerneinheit werden wir anhand einer Textsammlung von 67 deutschsprachigen Texten (Romane, Romanauszüge, Dramen etc.) aus dem 19. und beginnenden 20. Jahrhundert die grundsätzlichen Funktionen der stilometrischen Textanalyse kennenlernen. Die Texte stammen zum Großteil aus dem literarischen Kanon; einer ist jedoch der anonym erschienene Text Schwester Monika und wir werden versuchen, herauszufinden, welchem Autor/welcher Autorin dieser Text evtl. zugesprochen werden könnte. In der → Stilometrie werden hierzu die statistischen Verteilungen der häufigsten Wörter (most frequent words) in den Texten miteinander verglichen; diese Verteilungsmuster sind oft autor*innenspezifisch. Einer der zentralen Anwendungsfälle der Stilometrie ist daher die Autorschaftsattribution, ebenso kommt sie aber bei stilistischen Gattungs-, Genre- oder Epochenklassifizierungen zum Einsatz. Das Tool → Stylo wird am häufigsten für diese Methode verwendet. Es integriert die gängigen Algorithmen stilometrischer Verfahren in einer um Nutzerfreundlichkeit bemühten grafischen Benutzeroberfläche.
2. Vorarbeiten
Zunächst laden Sie sich die Sammlung der 67 Texte auf Ihren Rechner. Gehen Sie dazu hier auf die Github-Seite der Computational Stylistics Group, die das Stylo-Package für die Statistiksoftware R entwickelt hat. Dort klicken Sie auf „Clone or download” und dann auf „Download ZIP”.
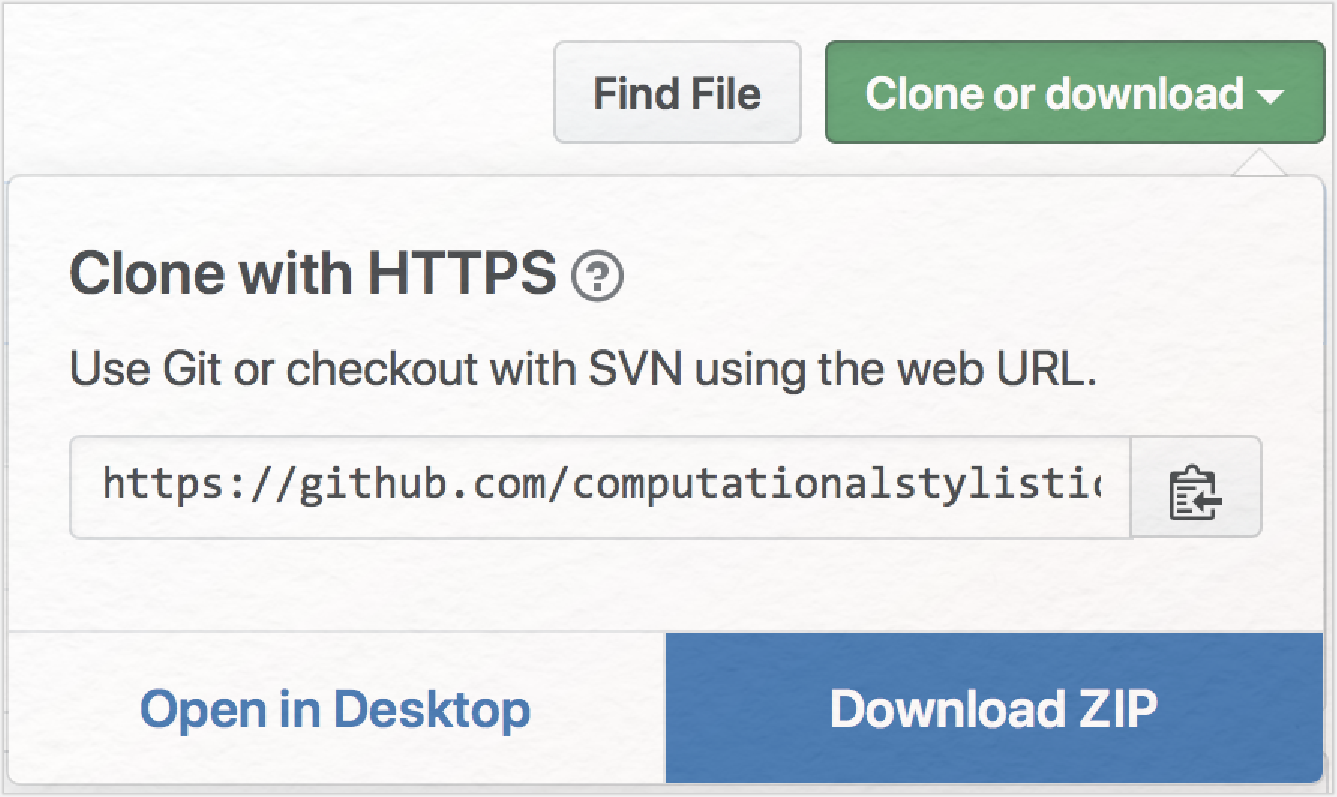
In Ihrem Downloadordner finden Sie nun einen Ordner namens „68_german_novels-master”. Speichern Sie diesen Ordner an einem Ort auf Ihrem PC, an dem Sie ihn leicht wiederfinden können. Sie sehen in diesem Ordner einen weiteren Ordner, der die 67 Texte im TXT-Format enthält, das für Stylo ideal ist. Die Dateinamen folgen dem Muster „Kategorie_Titel”. Die Kategorie sind hier die Autor*innennamen, genauso gut könnte man hier Genres, Genderbezeichnungen, Übersetzer*innennamen etc. angeben. Wichtig ist, dass alle Dateien in einer Textsammlung diesem Muster entsprechend benannt werden, damit sie von Stylo im Analyseergebnis korrekt visualisiert werden (jede Kategorie bekommt dort eine andere Farbe) und dass die Texte einer Sammlung alle das gleiche Dateiformat haben. Da Stylo nur die Worte in ihrer Häufigkeit und Verteilung analysiert, d. h. lediglich die Textoberfläche betrachtet, werden bei dieser Methode keine Metadaten benötigt. Eine Textsammlung im XML- oder auch HTML-Format kann im Tool zwar verarbeitet werden, die besten Ergebnisse werden jedoch mit Dateien im Plaintext-Format (TXT) erzielt. Eine weitere günstige Voraussetzung für die stilometrische Analyse von Textsammlungen mit Stylo ist die UTF-8-Codierung der Texte, die beim vorliegenden Korpus ebenfalls gegeben ist.
Nun müssen Sie sich noch die Software R installieren, in der Stylo ausgeführt werden soll. Dazu folgen Sie diesem Link, klicken unter der Überschrift „Getting Started” auf „Download R” und wählen einen sog. „CRAN Mirror”, der in der Nähe Ihres Standortes liegt (wie z. B. unter Germany die GWDG Göttingen). CRAN (d. h. Comprehensive R Archive Network) ist ein internationales Server-Netzwerk, aus dem Sie die Packages, die Sie in R gebrauchen werden, downloaden. Einen Mirror zu wählen, der topografisch in der Nähe liegt, minimiert daher den Rechenaufwand für das Netzwerk. Auf der sich öffnenden Seite klicken Sie auf denjenigen Downloadlink, der Ihrem Betriebssystem entspricht.
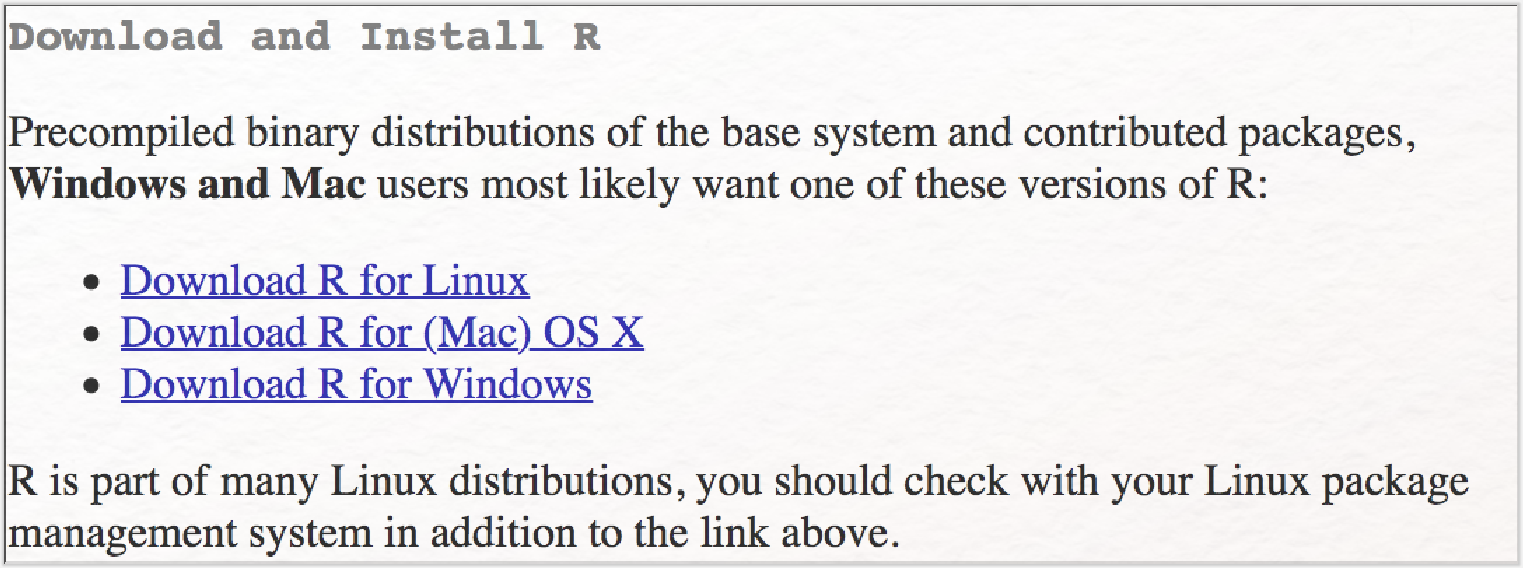
Auf der sich öffnenden Seite klicken Sie (als Mac-User*in) auf die PKG-Datei, die Ihrer Mac-OS-Version entspricht (z. B. R-3-6-0.pkg) bzw. (als Windows-User) auf „install R for the first time” und dann direkt oben auf „Download R 3.6.0 for Windows” (bzw. die jeweils aktuelle Version). Als Mac-User*in müssen Sie, damit Sie Stylo benutzen können, zusätzlich noch XQuartz installieren, klicken Sie dafür hier und laden sich die angezeigte DMG-Datei herunter. Sie müssen im Anschluss an die Installation von XQuartz Ihren Computer einmal neu starten, damit sich die Benutzeroberfläche von Stylo öffnen kann.
Öffnen Sie die heruntergeladenen Dateien (PKG für Mac, EXE für Windows) und folgen den Anweisungen des Installationsassistenten. Mac-User*innen machen dies ebenfalls mit der heruntergeladenen XQuartz-Installationsdatei (und starten anschließend ihren Mac neu). Sollten Sie beim Öffnen dieser Dateien eine Warnmeldung bekommen, kann es sein, dass Sie für das Programm eine Ausnahme in Ihren Sicherheitseinstellungen hinzufügen müssen. Wie das geht, erfahren Sie im folgenden Video (oben für Mac, unten für Windows):
Da es insbesondere für Einsteiger*innen sehr viel leichter ist, R innerhalb einer grafischen Benutzeroberfläche zu bedienen, die Ihnen neben der Console noch zahlreiche weitere Bedienoptionen bietet, installieren Sie sich nun noch RStudio, indem Sie hier klicken, dem Downloadlink unterhalb der Open-Source-Desktopversion folgen und anschließend unter der Überschrift „Installers for Supported Platforms” den Ihrem Betriebssystem entsprechenden Link klicken (z. B. „RStudio 1.2.1335 - Windows 7+”). Die heruntergeladene Installationsdatei führen Sie wie schon zuvor bei R per Klick aus.
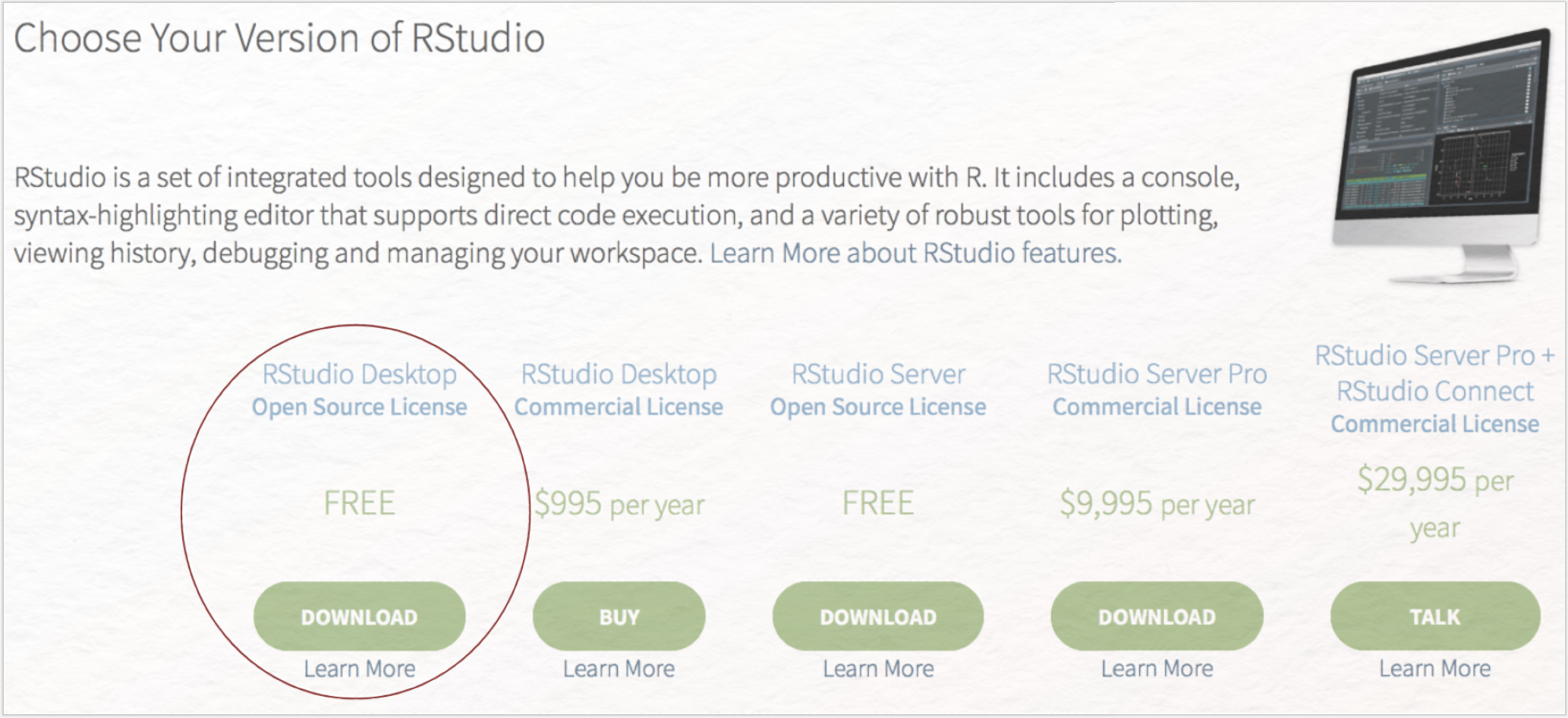
In Ihrem Programmeordner sollten sich nun die Programme R und RStudio befinden. Öffnen Sie nun RStudio.
![]()
Die Benutzeroberfläche von RStudio öffnet sich und sieht folgendermaßen aus:
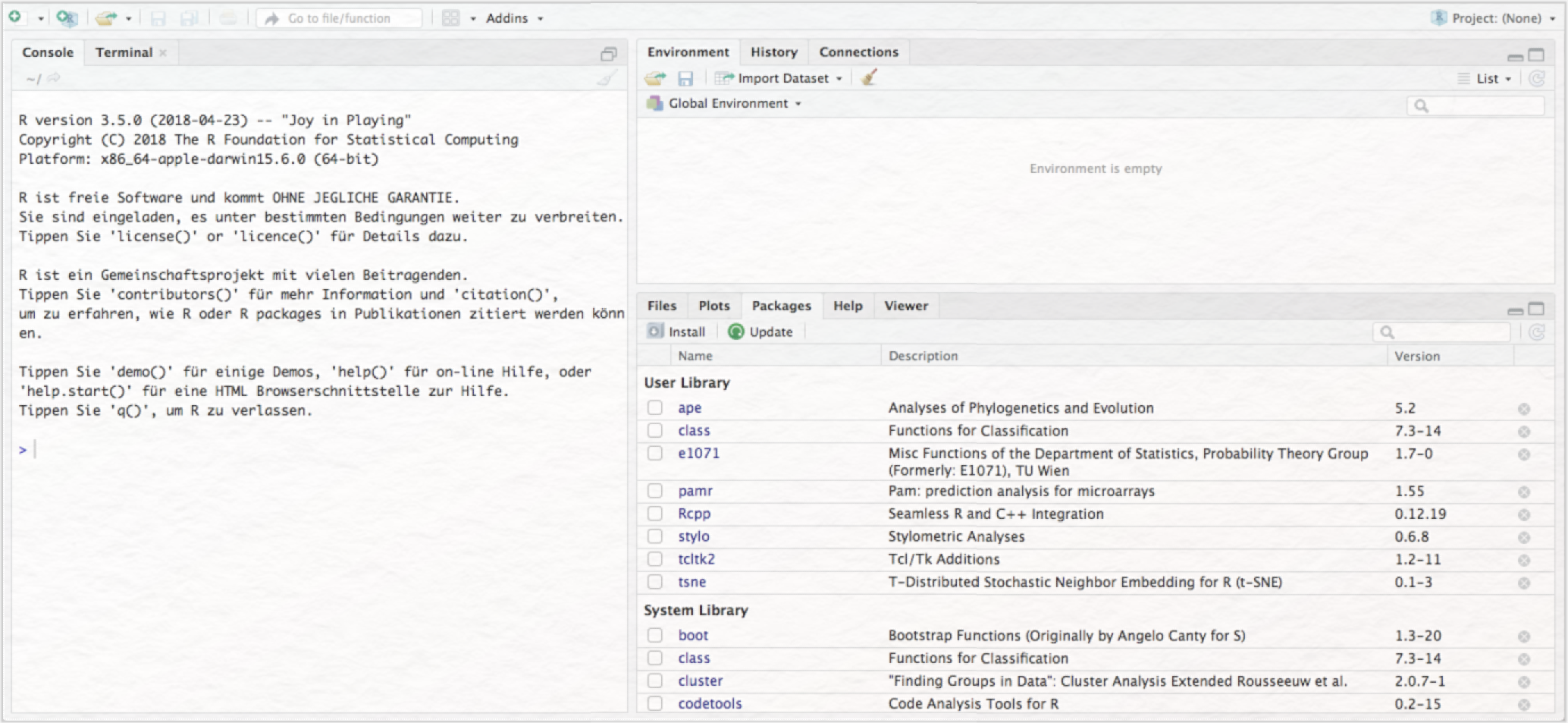
Als letzten Schritt zur Vorbereitung der stilometrischen Analyse müssen Sie nun noch das Stylo-Package in RStudio installieren. Klicken Sie dazu im rechten unteren Panel auf den Reiter „Packages” (vgl. Abb. 5) und dann auf den Button „Install”. Es öffnet sich folgendes Fenster:
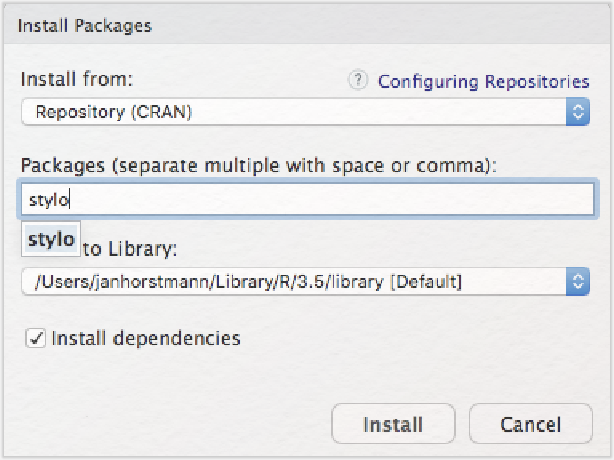
Sie begegnen hier erneut dem CRAN-Repositorium, das Ihnen aus der Installation von R bereits vertraut ist. Aus diesem Repositorium werden Packages jeweils aktuell installiert. Tippen Sie in die „Packages”-Zeile „stylo” ein, wird Ihnen auch schon das entsprechende Package vorgeschlagen. Anschließend bestätigen Sie die Installation mit einem Klick auf „Install”.
Nun erscheint im rechten unteren Panel von RStudio unter „User Library” das Package „stylo”, das Sie mit einem Häkchen versehen und dadurch aktivieren (vgl. Abb. 7). Durch diese Aktion öffnet sich (sind Sie Mac-User*in) automatisch ebenfalls XQuartz.
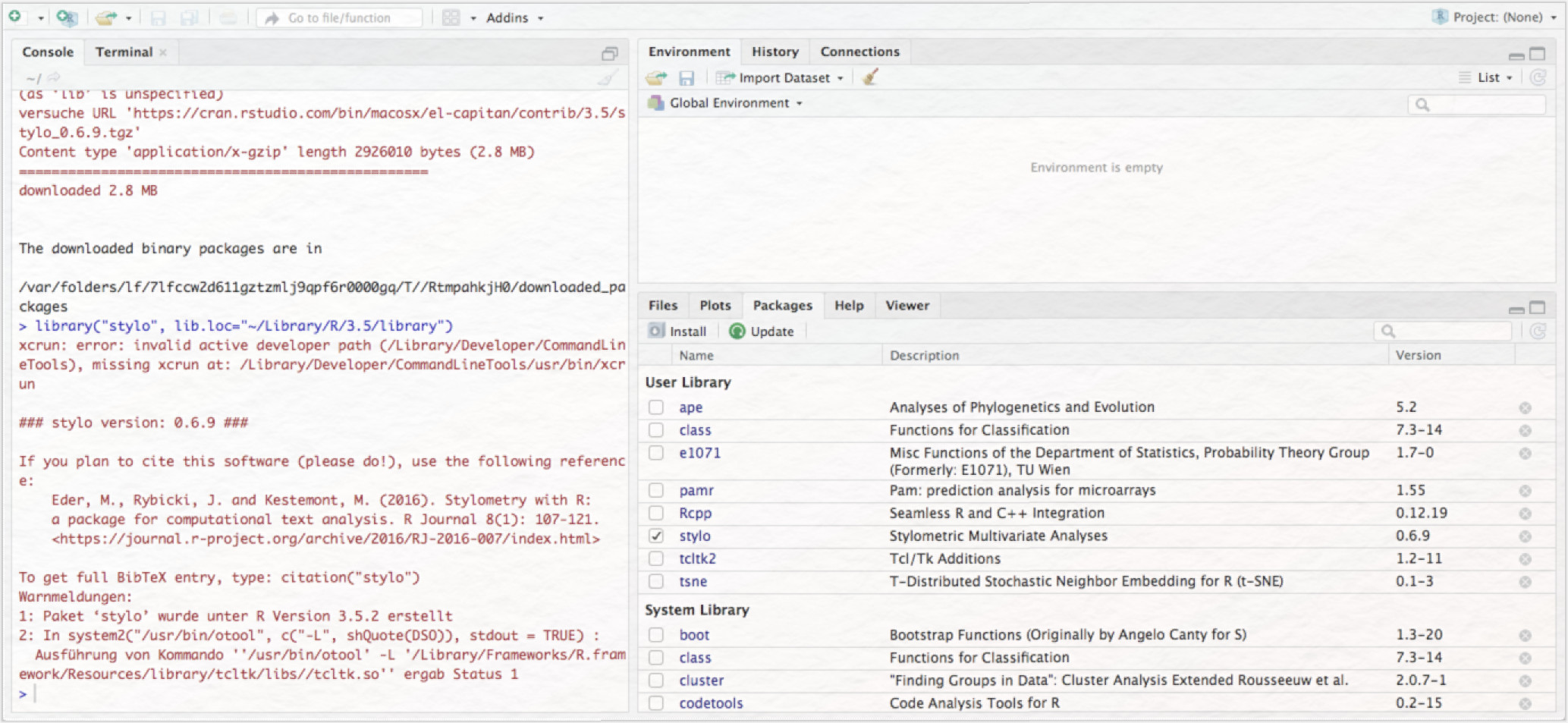
Sie haben nun alle Komponenten installiert, die Sie für eine erfolgreiche stilometrische Untersuchung benötigen: das Korpus, R, RStudio und das Stylo-Package. Sollte es im Folgenden zu Fehlern kommen, könnte es sein, dass Sie noch zusätzlich die Packages „tcltk2” und „ape” installieren müssen. Einige Systeme benötigen diese, um die Ergebnisvisualisierungen korrekt darstellen zu können. Diese Packages installieren Sie genau so wie das Stylo-Package zuvor.Um loslegen zu können, müssen Sie RStudio lediglich noch mitteilen, auf welchen Datensatz (d. h. unsere zuvor heruntergeladene Textsammlung) es zugreifen soll. Klicken Sie dazu in der oberen Menüleiste auf „Session”, hovern Sie über „Set Working Directory” und klicken dann auf „Choose Directory…” (vgl. Abb. 8).
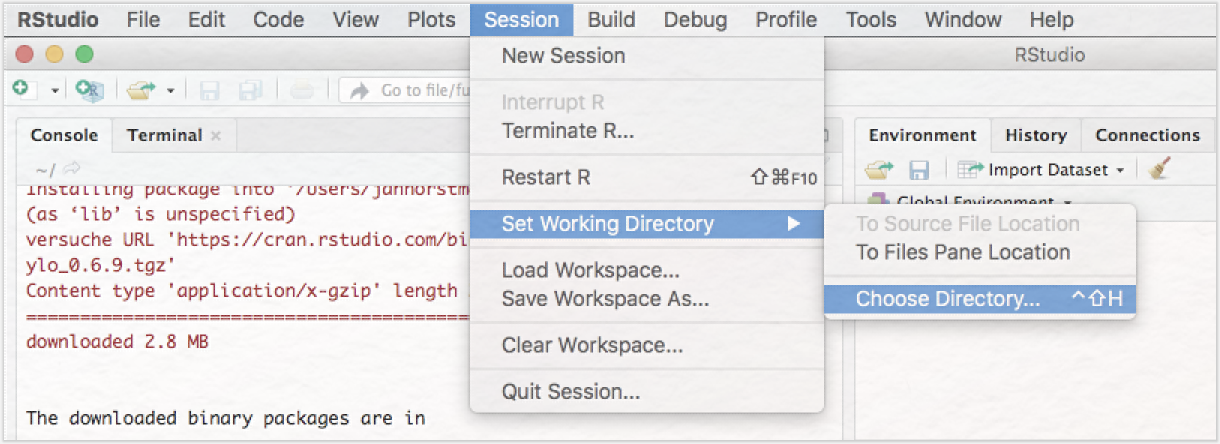
Navigieren Sie im sich öffnenden Fenster zum Ordner „68_german_novels-master” und bestätigen Ihre Auswahl mit einem Klick auf den Button „Open”. Achtung: Wählen Sie hier nicht den Unterordner „corpus” aus! In der Console (linkes Panel von RStudio) erscheint anschließend eine Meldung, die den Ort angeben wird, an dem Sie das Korpus gespeichert haben: „>setwd("~/Documents/Stylo/68_german_novels-master")”. Nun haben Sie alle nötigen Vorarbeiten erfolgreich hinter sich gebracht und sind bereit für die digitale stilometrische Analyse der Texte.
3. Funktionen
Um die grafische Benutzeroberfläche von Stylo zu öffnen, klicken Sie in der Console hinter das blaue „>”-Zeichen, tippen „stylo()” (ohne die Anführungszeichen) und drücken anschließend die Enter-Taste. Das „>”-Zeichen in der Console zeigt immer an, dass R bereit für eine Eingabe Ihrerseits ist. Solange das „>”-Zeichen nicht angezeigt wird, hat R die aktuell durchgeführte Aufgabe noch nicht abgeschlossen. Es öffnet sich folgendes Fenster:
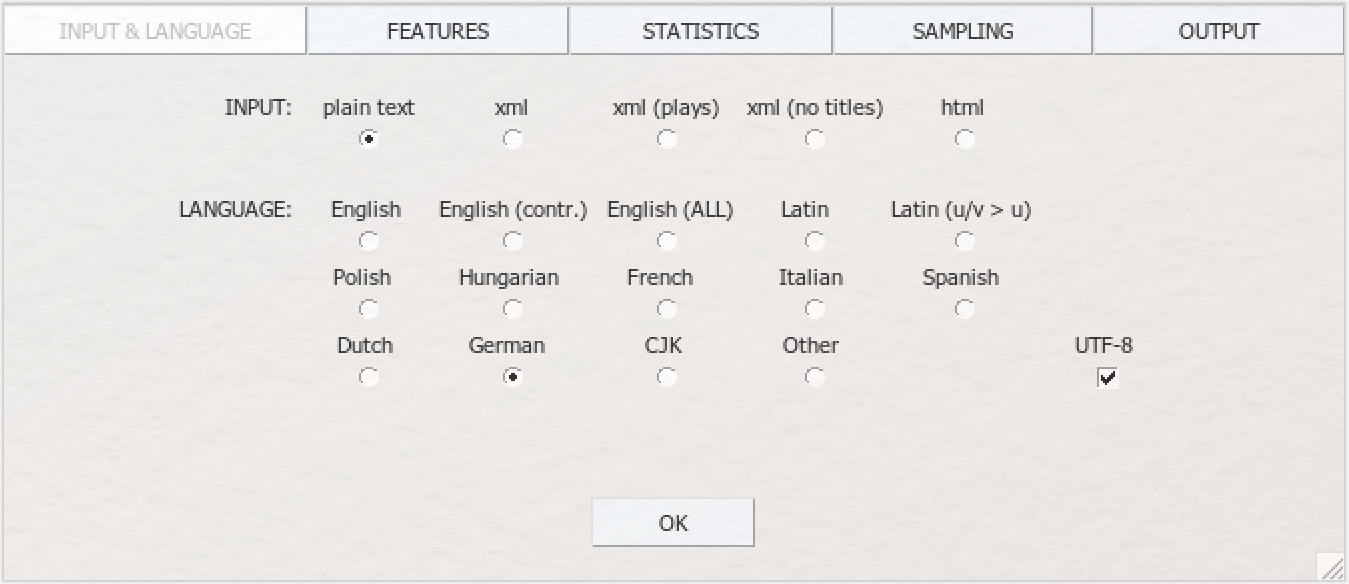
Die Benutzeroberfläche von Stylo gliedert sich in fünf Module: „INPUT & LANGUAGE”, „FEATURES”, „STATISTICS”, „SAMPLING” und „OUTPUT”. Wir werden im Folgenden die meisten Einstellungsmöglichkeiten der einzelnen Module kennenlernen. Tipp: Wenn Sie über die einzelnen Optionen hovern, die unter den jeweiligen Modulen aufgelistet werden, erscheinen kurze Erläuterungen der jeweiligen Funktion, sog. Tooltips. (Achtung: Ein Klick auf den „OK”-Button unten startet die stilometrische Analyse Ihrer Textsammlung. Dieser Button sollte erst betätigt werden, wenn die Einstellungen in sämtlichen fünf Modulen angepasst worden sind. Sämtliche Einstellungen eines Durchgangs werden in einer Datei namens „stylo_config.txt” im ausgewählten Ordner (der Working Directory) gespeichert, sodass eine Analyse bei Bedarf exakt wiederholt werden kann. Diese Datei sorgt außerdem dafür, dass die Einstellungen im Stylo-GUI bei jedem neuen Durchgang zu Beginn noch so sind wie beim jeweils vorherigen.)
Im Modul INPUT & LANGUAGE legen Sie fest, mit welcher Datengrundlage Stylo operieren soll. Die Dokumente in unserem Korpus sind im TXT-Format, deutschsprachig und UTF-8 codiert, Sie stellen folglich „plain text” und „German” ein (und aktivieren als Windows-Nutzer*in außerdem das Kästchen bei UTF-8).
Aufgabe 1
Was ist in den Spracheinstellungen der Unterschied zwischen „English” und „English (ALL)” und was bedeutet „Latin (u/v > u)”?
Im Modul FEATURES (vgl. Abb. 10) legen Sie die grundsätzlichen Einstellungen Ihres jeweiligen Analysedurchgangs fest.
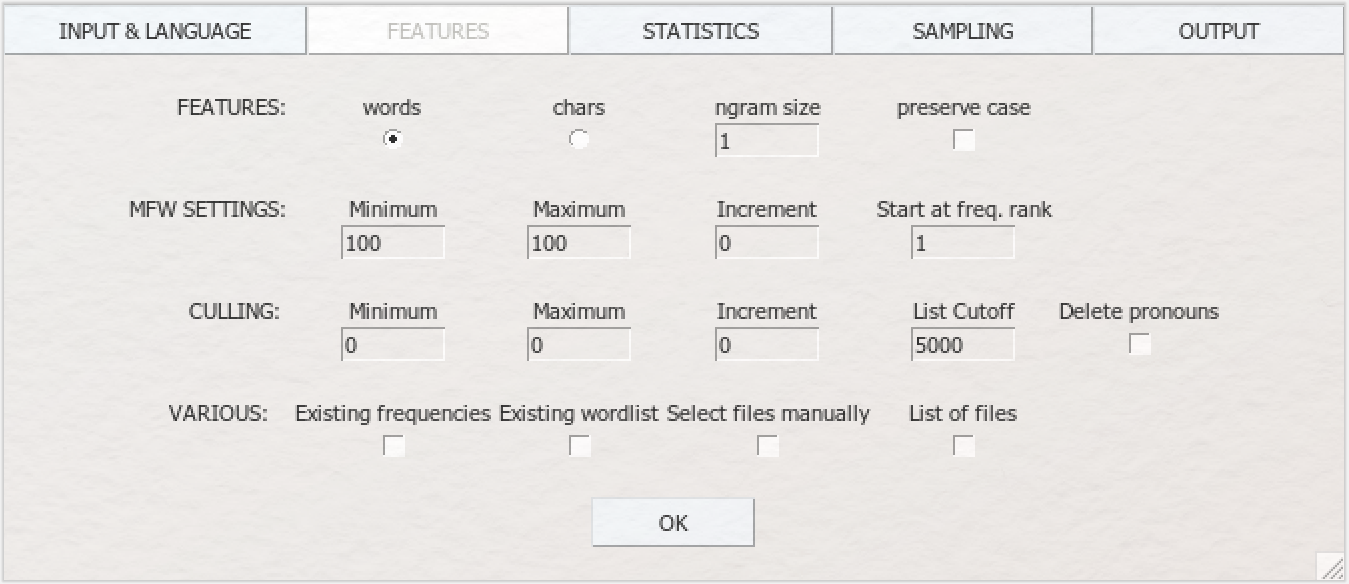
Unter dem Unterpunkt „FEATURES” können Sie entscheiden, ob Sie die stilometrische Untersuchung auf Wort- oder Buchstabenebene („words” oder „chars”) ausführen wollen. Entscheidet man sich für die Buchstabenebene, sollte man auf jeden Fall Buchstabenfolgen untersuchen lassen; dies erreicht man mit der Festlegung einer N-Gramm-Größe. N-Gramms funktionieren sowohl auf Buchstaben- wie auch auf Wortebene. Bei der Analyse auf Wortebene bietet sich jedoch eine sehr kleine N-Gramm-Größe an, da nur die Verteilung gleicher Wortkombinationen (und nicht gleicher Wörter) untersucht werden und man somit nur eine sehr limitierte Datengrundlage hätte. Die Untersuchung auf Buchstabenebene bietet sich vor allem an, wenn man ein „schmutziges” Korpus hat, d. h. Texte mit orthografischen Fehlern, die z. B. im Digitalisierungsprozess durch die OCR entstehen können. Ist im Stylo-GUI die Option „preserve case” aktiviert, werden Groß- und Kleinbuchstaben weiterhin voneinander getrennt; ist sie nicht aktiviert, werden für die Analyse alle Buchstaben in Kleinbuchstaben umgewandelt. Es ist nicht nur sprachen- sondern auch korpusabhängig, welche Einstellung hier die besten Ergebnisse bringt.
Der Unterpunkt „MFW SETTINGS” regelt die Einstellungen für die most frequent words (MFW). Auf Grundlage der Analyseergebnisse werden Sie vor allem in dieser Kategorier nach jedem Analysedurchgang neue Einstellungen vornehmen. Für den Anfang bietet es sich an, sowohl bei „Minimum” als auch bei „Maximum” die Voreinstellung beizubehalten und die Zahl 100 nach jedem Durchgang jeweils zu erhöhen. 100 bedeutet in diesem Fall, dass im Analysedurchgang die 100 häufigsten Wörter aus allen Texten miteinander verglichen werden. Die „Increment”-Einstellung (deutsch: Zuwachs) ist solange irrelevant, wie bei „Minimum” und „Maximum” die gleiche Zahl eingetragen wird. Wir kommen im Modul „STATISTICS” im Zusammenhang mit dem sog. Bootstrap-Verfahren noch einmal auf diesen Parameter zurück. Im Feld „Start at freq. rank” können Sie festlegen, ob und wenn ja wie viele der häufigsten der MFW aus der Analyse ausgeschlossen werden sollen. Lassen Sie die voreingestellte 1 in diesem Fall einfach stehen; sie bedeutet, dass alle 100 häufigsten Wörter berücksichtigt werden.
Im Unterpunkt „CULLING” (deutsch: auslesen, aussondern) können Sie festlegen, ob textspezifisch besondere Wörter aus der Analyse ausgeschlossen werden sollen. Stylo berechnet Wortfrequenzlisten und auf Basis dieser Listen die für die jeweiligen Texte typischsten Wörter, d. h. alle Wörter, die nur in dem jeweiligen Text vorkommen. Von diesen Wörtern können Sie mittels Culling einen bestimmbaren Prozentsatz aus der Analyse ausschließen. Ein Culling-Wert von bspw. 20 bedeutet somit, dass nur Wörter, die in wenigstens 20 % der Texte vorkommen, analysiert werden, ein Wert von 100, dass nur Wörter berücksichtigt werden, die in sämtlichen Texten der Sammlung vorkommen. Auch hier ist die „Increment”-Einstellung insbesondere im Zusammenhang mit dem Bootstrap-Verfahren, auf das wir zurückkommen, relevant. Für den Anfang müssen Sie in dieser Lerneinheit beim Culling keine Einstellungen vornehmen.
Die Einstellungen bei „List Cutoff” und „Delete pronouns” stehen in keiner Verbindung zum Culling, auch wenn das Interface diesen Eindruck erweckt. Der Wert bei „List Cutoff” bestimmt, ab welchem Punkt der Worthäufigkeitstabelle die jeweils seltenen Wörter der Texte nicht weiter berücksichtigt werden. Die voreingestellte 5000 können Sie in dieser Lerneinheit einfach stehen lassen. Die Option „Delete pronouns” ist eher für erfahrene Nutzer*innen gedacht. Mit ihr werden Pronomen ausgeschlossen (wichtig ist dabei, dass die Sprache im „INPUT & LANGUAGE”-Modul korrekt eingestellt wurde).
Die Optionen unter „VARIOUS” bleiben für diese Lerneinheit inaktiv und werden aus diesem Grund hier nicht en detail besprochen. Die Einstellungen erlauben Ihnen, Ergebnisse aus einer Analyse mit der Folgeanalyse zu verknüpfen, oder nur ausgewählte Texte aus Ihrem Korpus in der Analyse zu berücksichtigen. Ein umfangreiches, englischsprachiges Manual zu allen Funktionen in Stylo findet sich bereitgestellt durch die Computational Stylistics Group hier.
Aufgabe 2
Welche Vor- und Nachteile hat es, die sog. case sensitivity zu berücksichtigen, d. h. „preserve case” bei einer Analyse zu aktivieren? Welche Wörter sind vermutlich in den meisten Texten die MFW?
Das Modul „STATISTICS” (vgl. Abb. 11) bietet Ihnen die Möglichkeit, aus einer Vielzahl von Algorithmen (statistischen Verfahren und Distanzmaßen) auszuwählen.
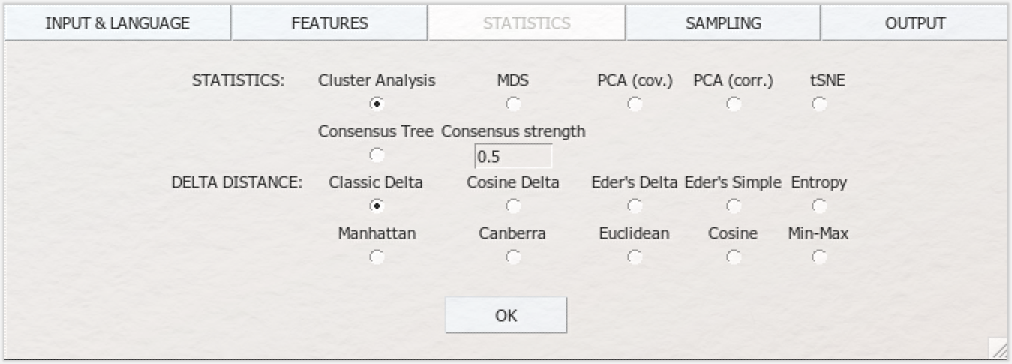
Das grundlegendste statistische Verfahren ist die Cluster Analysis, die das Korpus nach Ähnlichkeiten durchsucht und ähnliche Texte zusammen „clustert”, d. h. eine Gruppe bilden lässt. Die Visualisierungsform dieser Analyse ist ein Dendrogramm. Die multidimensionale Skalierung (MDS), die Principal Component Analysis (PCA) und die t-distributive stochastische Nachbareinbettung (t-distributive stochastic neighbour embedding; tSNE) sind Verfahren der Dimensionsreduktion und lassen ähnliche Texte innerhalb eines zweidimensionalen Koordinatensystems beieinander clustern. Der Consensus Tree (oder auch „Bootstrap Consensus Tree”) ist eine runde Visualisierungsform, die mehrere Clusteranalysedurchgänge mit unterschiedlich vielen MFW bzw. Culling-Parametern in einer Ergebnisvisualisierung vereinigt. Dieses Verfahren wird daher auch „Bootstrap” genannt (was wörtlich mit „Stiefelriemen” übersetzt werden kann – wie die Schnürsenkel eines Schuhs werden die einzelnen Analysedurchläufe ineinander gewebt und am Ende festgezogen). Ähnliche Texte werden hier an einem Ast clusternd dargestellt. Wenn Sie „Consensus Tree” auswählen, müssen Sie im Modul FEATURES beim MFW-Setting zusätzlich angeben, mit wie vielen MFW die Analyse beginnen („Minimum”), mit wie vielen sie aufhören soll („Maximum”) und wie viele Wörter bei jeder einzelnen Analyse hinzukommen sollen („Increment”). Ebenso erfordert dieses Verfahren unterschiedliche Minimum- und Maximumangaben beim Culling, insofern Sie die Cullingfunktion nutzen wollen (ansonsten lassen Sie dort einfach überall die „0” stehen). Für den Consensus Tree (und nur für ihn) muss zusätzliche eine „Consensus strength” angegeben werden. Hier können Sie eine Zahl zwischen 0,4 und 1 eingeben. 0,4 bedeutet, dass Verbindungen in mindestens 40 % der Analysedurchgänge gegeben sein müssen, um auch in der Consensus-Tree-Visualisierung als Verbindung angezeigt zu werden. 1 bedeutet entsprechend, dass dies in 100 % der Durchläufe gegeben sein muss. Die voreingestellte 0,5 können Sie hier zunächst ebenfalls stehen lassen; diese Zahl spielt solange keine Rolle, wie eine der anderen Statistiken ausgewählt ist. Wir konzentrieren uns hier auf die Clusteranalyse.
Hinter den unterschiedlichen Distanzmaßen, die neben dem Menüpunkt „DELTA DISTANCE” aufgelistet werden, verstecken sich die Algorithmen, mit denen die Distanzen, d. h. im Grunde die Ähnlichkeiten zwischen den Texten, berechnet werden. Diese Sektion bildet das mathematische Herzstück von Stylo, soll in dieser einführenden Lerneinheit jedoch nicht en detail besprochen werden. Je nach Sprache und Einstellung (Wörter oder N-Gramms) bieten sich unterschiedliche Distanzmaße an. Für unsere deutschsprachige Textsammlung sind insbesondere die Maße „Classic Delta” (auf John Burrows zurückgehend) und „Cosine Delta” (an der Universität Würzburg entwickelt) geeignet. Euclidean und Manhattan Distance sollten im Zusammenhang mit der Analyse von Worthäufigkeiten eher vermieden werden; Canberra Distance bietet sich insbesondere für lateinische Texte an, etc. Eine genauere Beschreibung der einzelnen Distanzmaße finden Sie im Stylo-Handbuch (S. 15–17).
Das Modul „SAMPLING” (vgl. Abb. 12) bietet Ihnen die Möglichkeit, die Texte in Ihrer Sammlung in gleich große Segmente zu zerschneiden.
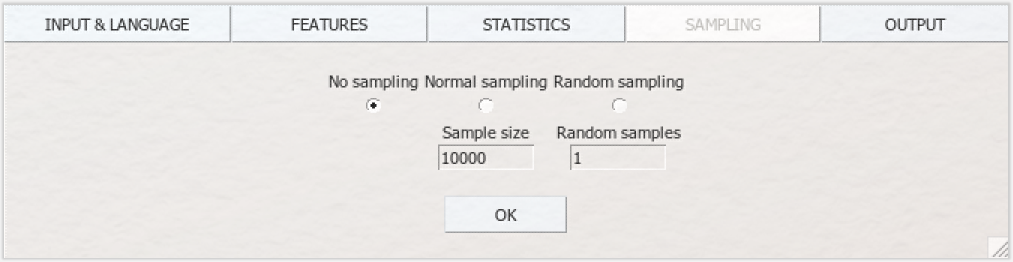
Diese Segmentierung, die aus literaturwissenschaftlicher Sicht erst einmal blasphemisch anmutet, kann die Ergebnisse der stilometrischen Analyse durchaus verbessern, insbesondere wenn man eine Sammlung untersucht, die Texte mit unterschiedlicher Länge enthält. Um statistische Verteilungen von häufigen Wörtern in Texten zu analysieren, ist es immer sinnvoll, ähnlich lange Texte (bzw. Textsegmente) miteinander zu vergleichen. Im Feld „Sample size” wird bei aktivierter Funktion „Normal sampling” angegeben, wie groß die Segmente sein sollen – angegeben in Wortmenge. Noch experimenteller wird es mit der Option „Random sampling”: ein Verfahren, bei dem die Texte nicht nur in gleich große Segmente zerschnitten, sondern die Wörter aus den Texten auch noch zufällig ausgewählt und zu einem Segment zusammengesetzt werden (dieses Verfahren ist unter dem Namen „bag of words” bekannt). Auf diese Weise können gelegentlich noch bessere Zuschreibungen erreicht werden. Bei dieser Option geben Sie im Feld „Random samples” die Menge der Segmente an, in die ein jeder Text in Ihrer Sammlung zerschnitten werden soll. Keine Sorge: Ihre Texte werden nicht wirklich zerstört und die Dateien in Ihrem Ordner verbleiben in ihrem ursprünglichen Zustand, Sampling ist eine rein rechnerische Aktion. Für unsere Beispielanalyse lassen Sie die voreingestellte Option „No sampling” aktiviert.
Nun haben Sie die wichtigsten Einstellungen von Stylo (INPUT & LANGUAGE, FEATURES, STATISTICS und SAMPLING) kennengelernt, die Sie für Ihre erste stilometrische Analyse brauchen. Sie müssen nur noch bestimmen, wie Ihnen die Ergebnisse angezeigt und wie sie gespeichert werden sollen. Das geschieht im fünften Modul „OUTPUT” (vgl. Abb. 13.).
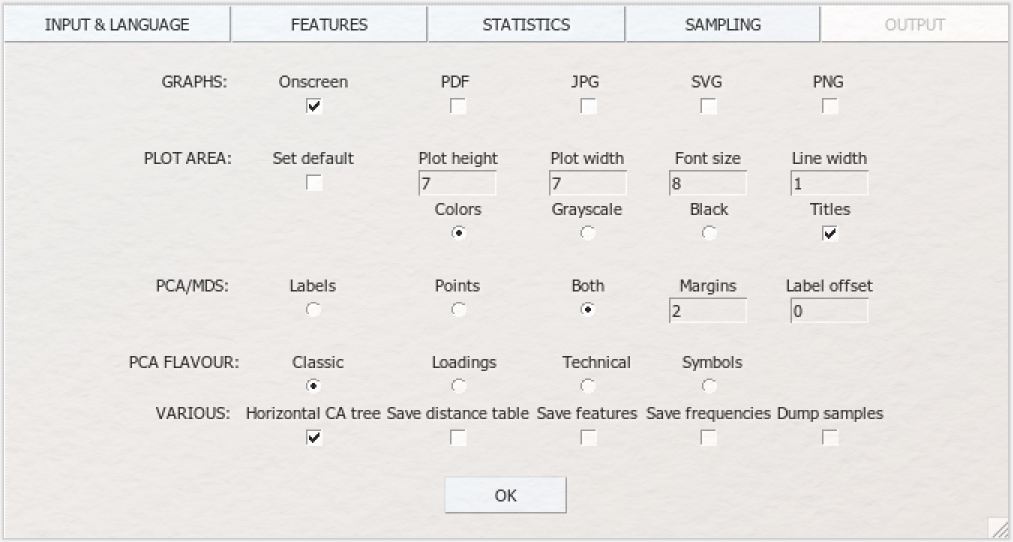
Unter „GRAPHS” können Sie auswählen, in welchen Formaten die Ergebnisvisualisierung gespeichert werden soll. „Onscreen” zeigt Ihnen den Graphen lediglich programmintern im RStudio-Modul rechts unten unter „Plots” an. Sämtliche anderen Formate werden als Dateien in Ihrem „Working Directory”-Ordner auf Ihrem Computer gespeichert, in unserem Fall also unter „68_german_novels-master”. Insbesondere bei iterativen Analysen mit unterschiedlichen MFW- oder Culling-Einstellungen kann es dabei schnell zu einer großen Menge an gespeicherten Dateien kommen; wählen Sie die Einstellungen daher mit Bedacht. Tipp: Wählen Sie zunächst „Onscreen”, inspizieren Sie die Visualisierung nach der Analyse und wiederholen Sie den Durchgang mit den gleichen Einstellungen dann noch einmal, um die gleiche Visualisierung als Datei im gewünschten Format zu speichern.
Sie finden im Modul OUTPUT noch etliche weitere Einstellungsmöglichkeiten, um die zu erstellenden Visualisierungen nach Ihren Vorstellungen zu modifizieren, die wir hier nicht detailliert vorstellen werden. Die Tooltips und das Stylo-Handbuch geben Ihnen hier bei Bedarf weitere Hinweise. Viele der OUTPUT-Einstellungen beziehen sich auf spezifische statistische Verfahren. Die Einstellungen in den entsprechenden Zeilen bei OUTPUT sind daher so lange irrelevant, wie nicht das entsprechende statistische Verfahren unter STATISTICS ausgewählt wurde.
Aufgabe 3
Es ist soweit. Klicken Sie nun auf den „OK”-Button und starten damit Ihre erste stilometrische Analyse. Wenn Sie anschließend die Konsole in RStudio beobachten, können Sie verfolgen, wie der Algorithmus arbeitet. Wenn ein „>”-Symbol erscheint, ist die Analyse abgeschlossen. Dies kann abhängig von der Rechenleistung Ihres PCs durchaus eine Weile dauern. Unter „Plots” rechts von der Konsole wird Ihnen anschließend ein Dendrogramm angezeigt, das Sie mit einem Klick auf „Zoom” vergrößern und inspizieren können (Hinweis: Sollte es passieren, dass Ihnen ein leeres Dendrogramm angezeigt wird (d. h. nur Äste und keine Schrift), liegt das höchstwahrscheinlich daran, dass Sie die Schriftart „Arial” nicht installiert und aktiviert haben. Diese Schriftart gehört i. d. R. zum Standardset der aktivierten Schriftarten, im neuen Betriebssystem von MAC OS (Mojave) ist dies aber bspw. nicht der Fall. Schriftarten können Sie leicht im Internet finden und im Format TTF downloaden). Wie interpretieren Sie das Ergebnis?
Aufgabe 4
Experimentieren Sie mit den besprochenen Einstellungsmöglichkeiten. Wie können Sie beim Testen unterschiedlicher MFW-Zahlen Zeit sparen? Welche Einstellungen scheinen Ihnen für die gegebene Textsammlung gut geeignet?
Aufgabe 5
Ihnen wird bei der Bearbeitung der vorigen Aufgabe immer wieder der anonyme Text Schwester Monika ins Auge gefallen sein. Können Sie diesen Text einem der anderen Autoren zuordnen? Wenn nicht, wo könnten die Schwierigkeiten liegen?
4. Lösungen zu den Beispielaufgaben
Aufgabe 1: Was ist in den Spracheinstellungen der Unterschied zwischen „English” und „English (ALL)” und was bedeutet „Latin (u/v > u)”?
Die Tooltips (die Sie durch Hovern erhalten) geben Ihnen die Antworten: Bei der Einstellung „English (ALL)” werden im Gegensatz zur Einstellung „English” Verkürzungen wie „don’t” und zusammengesetzte Wörter wie „light-headed” nicht aufgesplittet. Im Modus „Latin (u/v > u)” werden alle Us und alle Vs als U gewertet.
Aufgabe 2: Welche Vor- und Nachteile hat es, die sog. case sensitivity zu berücksichtigen, d. h. „preserve case” bei einer Analyse zu aktivieren? Welche Wörter sind vermutlich in den meisten Texten die MFW?
Eine aktivierte „preserve case”-Option ist besonders für deutschsprachige Texte relevant. Sie verhindert, dass alle Buchstaben in Kleinbuchstaben umgewandelt werden. Der Vorteil davon ist beispielsweise, dass Wörter wie „spinne” bzw. „Spinne” nicht als gleiches Wort gewertet werden, was je nach Textsammlung einen wichtigen Vorteil darstellen kann. Ein entscheidender Nachteil ist jedoch, dass Worte am Satzanfang mit einem großen Buchstaben beginnen und daher in diesen Fällen als anderes Wort klassifiziert werden, als wenn sie innerhalb des Satzes auftauchen. Welche Einstellung für Ihre jeweilige Textsammlung sinnvoller ist, können Sie durch Ausprobieren herausfinden. Die MFW in Texten sind eigentlich immer Funktionswörter wie „und”, „aber”, „denn”, „ich”, „er”, „sie”, „es” etc. In unserem Beispielkorpus sind das in absteigender Häufigkeit „und”, „die”, „der”, „zu”, „in”, „er”, etc.
Aufgabe 3: Es ist soweit. Klicken Sie nun auf den „OK”-Button und starten damit Ihre erste stilometrische Analyse. Wenn Sie anschließend die Konsole in RStudio beobachten, können Sie verfolgen, wie der Algorithmus arbeitet. Wenn ein „>”-Symbol erscheint, ist die Analyse abgeschlossen. Dies kann abhängig von der Rechenleistung Ihres PCs durchaus eine Weile dauern. Unter „Plots” rechts von der Konsole wird Ihnen anschließend ein Dendrogramm angezeigt, das Sie mit einem Klick auf „Zoom” vergrößern und inspizieren können (Hinweis: Sollte es passieren, dass Ihnen ein leeres Dendrogramm angezeigt wird (d. h. nur Äste und keine Schrift), liegt das höchstwahrscheinlich daran, dass Sie die Schriftart „Arial” nicht installiert und aktiviert haben. Diese Schriftart gehört i. d. R. zum Standardset der aktivierten Schriftarten, im neuen Betriebssystem von MAC OS (Mojave) ist dies aber bspw. nicht der Fall. Schriftarten können Sie leicht im Internet finden und downloaden (im Format TTF). Wie interpretieren Sie das Ergebnis?
Die erste Analyse erstellt Ihnen folgendes Dendrogramm:
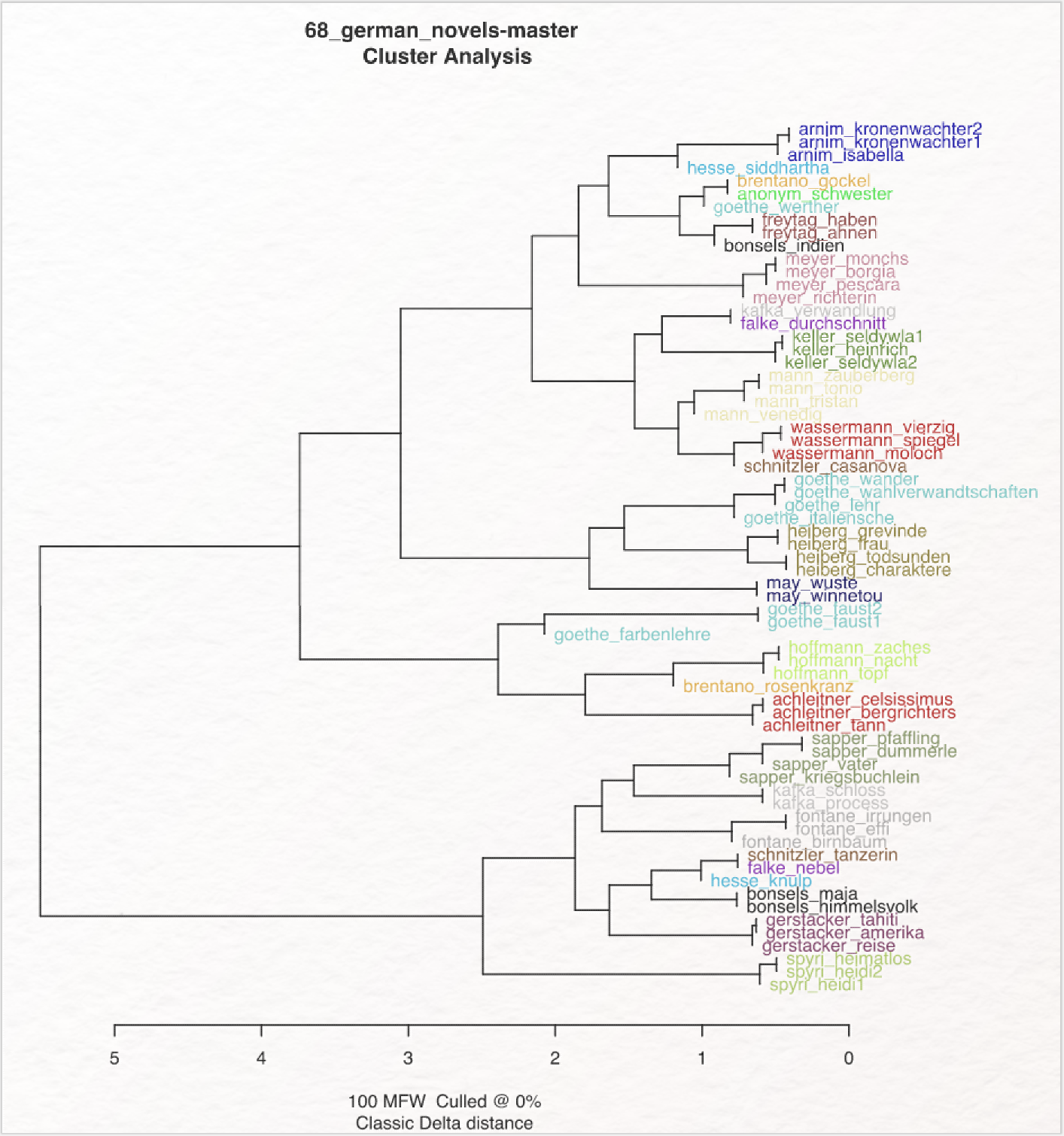
Texte am gleichen Ast sind sich (im Sinne der Stilometrie) stilistisch ähnlich, je mehr Gabelungen zwischen zwei Texten liegen, desto unähnlicher sind sie sich. Die vertikale Anordnung spielt dabei keine Rolle (es wäre eine Fehlinterpretation, die Texte von Spyri und Arnim für maximal unterschiedlich zu halten, weil sie am weitesten auseinander liegen – wenngleich sie sich auch alles andere als ähnlich sind). Die Zahlen in der horizontalen Leiste unten geben die Werte des jeweils ausgewählten Distanzmaßes an (hier Classic Delta Distance). Im Zuge einer Autorschaftsattribution ist es sinnvoll, wenn Texte des gleichen Autors am gleichen Ast clustern. Wir sehen in diesem ersten Beispiel, dass das bei vielen Autor*innen schon gut funktioniert. Das Vorkommen von Goethe, Kafka, Brentano, Hesse, Bonsels und Schnitzler an unterschiedlichen nicht zusammengehörenden Ästen zeigt, dass sich die Texte dieser Autoren noch nicht einheitlich klassifizieren lassen. Es kann einem zudem aufstoßen, dass Goethes Farbenlehre mit den Faust-Dramen und nicht mit den Prosatexten Goethes zusammen clustert, ist doch eine stilometrische Analyse auch zur Gattungsidentifikation geeignet. Daraus kann geschlossen werden, dass die Einstellungen für das Beispielkorpus noch nicht ideal sind.
Aufgabe 4: Experimentieren Sie mit den besprochenen Einstellungsmöglichkeiten. Wie können Sie beim Testen unterschiedlicher MFW-Zahlen Zeit sparen? Welche Einstellungen scheinen Ihnen für die gegebene Textsammlung gut geeignet?
Mit den „Minimum”-, „Maximum”- und „Increment”-Einstellungen lassen sich mehrere Analysen in einem Durchgang durchführen. Sie können somit z. B. bei „Minimum” 100, bei „Maximum” 3000 und bei „Increment” 100 einstellen und die erstellten Visualisierungen anschließend vergleichend analysieren. Im „Plots”-Panel von RStudio machen Sie das über die Pfeiltasten. Wenn Sie unterschiedliche MFW-Einstellungen in einer einzigen Visualisierung zusammenfassen möchten, wählen Sie im STATISTICS-Modul „Consensus Tree” aus und stellen ebenfalls in den FEATURES unterschiedliche Zahlen bei „Maximum” und „Minimum” und ein bestimmtes „Increment” ein.
Was „gute” Einstellungen sind, ist sicherlich subjektiv. Wir interpretieren Einstellungen als „gut”, wenn möglichst alle Texte einer Autorin/eines Autors am gleichen Ast clustern. Für die Clusteranalyse erreicht man mit 1500 Wörtern ein recht überzeugendes Ergebnis (vgl. Abb. 15). Ab etwa 2500 MFW lässt sich beobachten, dass Thomas Manns Zauberberg nicht mehr mit den anderen Mann-Texten clustert, die Einstellung eignet sich für die vorliegende Textsammlung daher nicht mehr so gut.
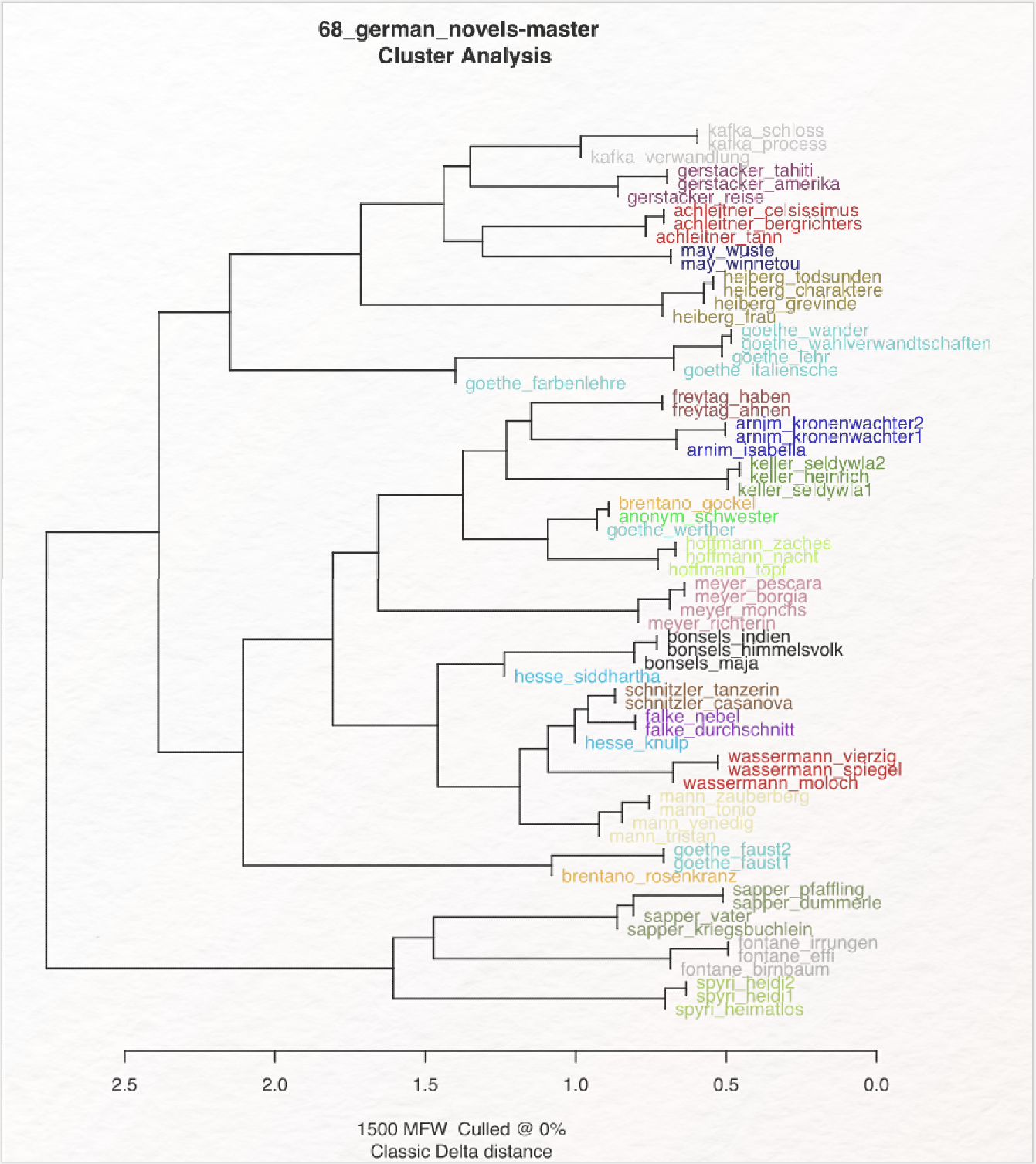
Der Bootstrap Consensus Tree sieht bei 1000–2500 MFW ebenfalls überzeugend aus (vgl. Abb. 16). Bei dieser Visualisierung gilt ebenfalls, dass die Lokalisierung auf der Fläche (oben/unten bzw. rechts/links) keine semantische Aussagekraft hat; es kommt lediglich darauf an, ob Texte eines Autors bzw. einer Gattung gemeinsam an einem Ast clustern. Wir sehen, dass mit einer Einstellung von 1000–2500 MFW beinahe sämtliche Texte Autor*innencluster bilden. Goethes Faust-Dramen clustern zudem nicht mehr zusammen mit der in Prosa geschriebenen Farbenlehre. Die zwei Texte Brentanos clustern bei fast sämtlichen Einstellungen nicht zusammen. Der Grund dafür ist die Gattungsdifferenz, die hier stärker zu Buche schlägt als etwaige Autorenstilmerkmale: Die Gedichtsammlung Romanzen vom Rosenkranz clustert nachvollziehbar zusammen mit den einzigen (ebenfalls in Versen geschriebenen) dramatischen Texten des Korpus (Goethes Faust I & II) und nicht zusammen mit anderen Prosatexten.

Aufgabe 5: Ihnen wird bei der Bearbeitung der vorigen Aufgabe immer wieder der anonyme Text Schwester Monika ins Auge gefallen sein. Können Sie diesen Text einem der anderen Autoren zuordnen? Wenn nicht, wo könnten die Schwierigkeiten liegen?
Der Text Schwester Monika (1815) clustert in den meisten Einstellungen sowohl zusammen mit Brentanos Märchen Gockel, Hinkel und Gackeleia (1838) als auch mit Goethes Die Leiden des jungen Werthers (1774), nicht jedoch zusammen mit den Texten E. T. A. Hoffmanns, dem der Text gelegentlich zugeschrieben wird. Vermutlich wurde Schwester Monika aber weder von Goethe noch von Brentano geschrieben, sondern von einer Autorin/einem Autor, der nicht in der Sammlung enthalten ist. Die häufige Zuordnung zu Brentano und Goethe in der vorliegenden Textsammlung liegt daran, dass in Schwester Monika etliche literarische Zitate enthalten sind, die der Idee eines „Autorenstils” selbstverständlich entgegenlaufen. Auch mit automatisierter Unterstützung konnte daher das Rätsel um diesen anonym erschienenen Text bislang nicht gelüftet werden. Sie sind nach dieser Lerneinheit fähig, sich mit unterschiedlichen Textsammlungen und verschiedenen Einstellungen in Stylo an dieser Debatte zu beteiligen.
