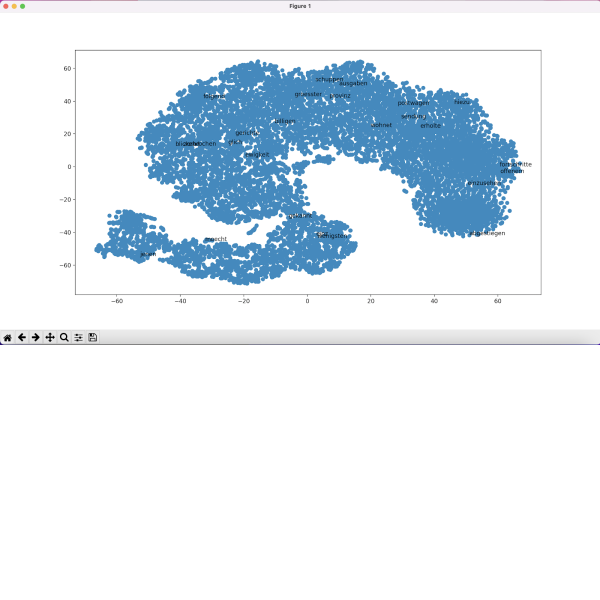
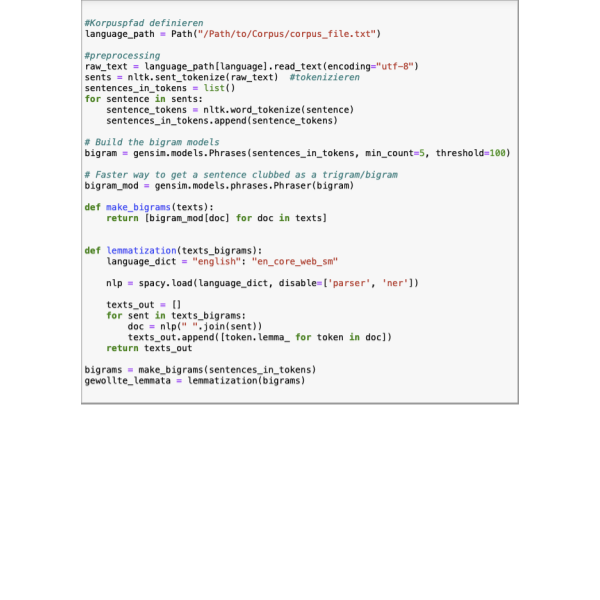
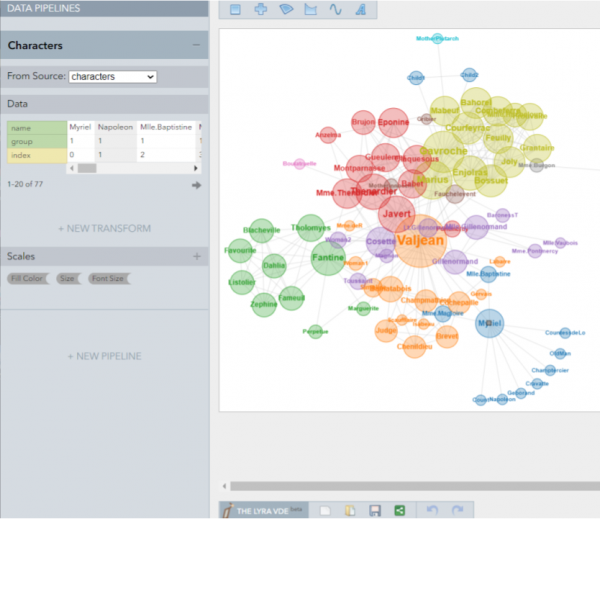
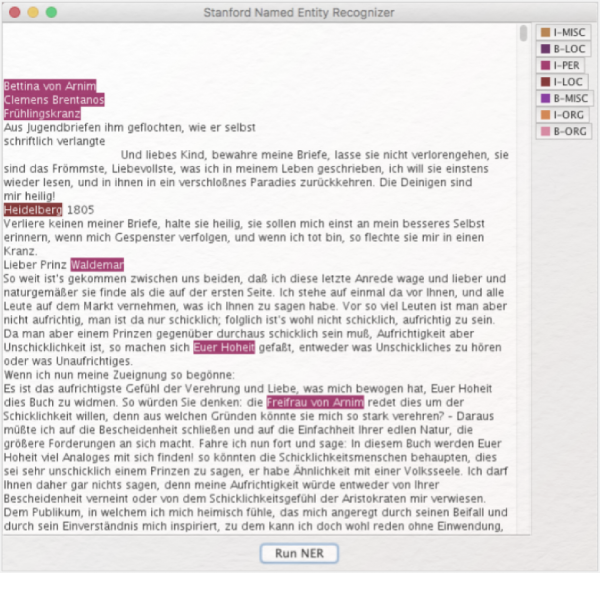
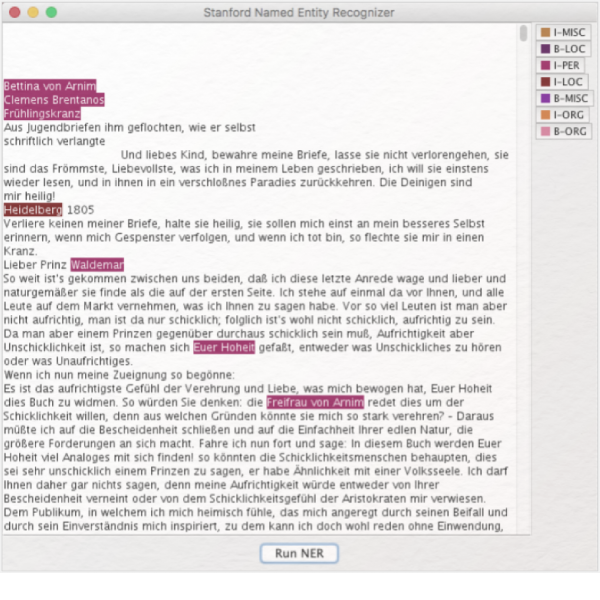
Analyse und Visualisierung mit CATMA

● Anwendungsbezug: Franz Kafkas Erstes Leid (1924)
● Methoden: Analyse, Visualisierung, halb-automatische Annotation
● Angewendetes Tool: CATMA
● Lernziele: quantitative Analyse von Text- und Annotationsdaten; Erstellen von Queries und interaktiven Visualisierungen; Anpassen der Visualisierungen; automatische Annotation ausgewählter Keywords
● Dauer der Lerneinheit: ca. 90 Minuten
● Schwierigkeitsgrad des Tools: leicht


")
")
: Digitale Textanalyse und -visualisierung")