Eckdaten der Lerneinheit
- Anwendungsbezug: Figuren in Goethes Wahlverwandtschaften (1809)
- Methode: Named Entity Recognition (NER)
- Angewendetes Tool: Stanford Named Entity Recognizer
- Lernziele: Automatische Annotation von Figuren, Berechnung der Güte des Ergebnisses, Verbesserung der Erkennung durch Training eines eigenen NER-Modells
- Dauer der Lerneinheit: 120 Minuten
- Schwierigkeitsgrad des Tools: mittel bis schwierig
Bausteine
- Anwendungsbeispiel
Welcher Primärtext liegt der Analyse zugrunde? Annotieren Sie automatisch die Figuren in Goethes Wahlverwandtschaften. - Vorarbeiten
Welche Arbeitsschritte sollten vor der Analyse ausgeführt werden? Das Tool wird installiert und eine digitale Reintextversion von Goethes Wahlverwandtschaften auf Ihren Rechner heruntergeladen. - Funktionen
Welche Funktionen bietet Ihnen der Stanford Named Entity Recognizer? Lernen Sie, Figuren, Orte und Organisationen in Texten automatisch annotieren zu lassen und ein eigenes Modell zur automatischen Annotation von Eigennamen zu trainieren. Dazu lösen Sie Beispielaufgaben. - Lösungen zu den Beispielaufgaben
Haben Sie die Beispielaufgaben richtig gelöst? Hier finden Sie Antworten.
1. Anwendungsbeispiel
In dieser Lerneinheit lassen Sie Figuren, Orte und Organisationen in Goethes Wahlverwandtschaften automatisch annotieren. Sie lernen, die Qualität Ihrer automatischen Annotation zu beurteilen und Sie verbessern das dahinter liegende Modell für Figuren. Die Methode → Named Entity Recognition (NER) hat ihren Ursprung in der linguistischen Forschung. Mittels NER werden dort hauptsächlich Sachtexte unterschiedlicher Art (journalistische Artikel, Social-Media-Postings u. Ä.) untersucht. Eine Domänenadaption der Methode für die Literaturwissenschaften ist häufig mit der Anpassung der implementierten Modelle verbunden. Darum lernen Sie in dieser Lerneinheit nicht nur, den → Stanford Named Entity Recognizer zu nutzen, sondern auch, die dort angebotenen Funktionen für literaturwissenschaftliche Forschung zu optimieren.
2. Vorarbeiten
Für die automatische Annotation von Eigennamen benötigen Sie den Stanford Named Entity Recognizer, ein Named-Entity-Recognition-Modell für die deutsche Sprache, eine aktuelle Version von Java und Ihren Primärtext im TXT-Format. Den Stanford Named Entity Recognizer können Sie hier herunterladen. Das Modell für die deutsche Sprache bekommen Sie hier. Sie müssen die Datei lediglich von der Dropbox-Adresse herunterladen, sie wird später mit dem Stanford Named Entity Recognizer geöffnet. In dieser Lerneinheit nutzen wir die Version 3.9.2 der deutschen NER-Modelle, die wir von der Webseite der Stanford Named Entity Recognition Group heruntergeladen und für Sie einzeln in eine ZIP-Datei verpackt haben. Wenn Sie das komplette Paket oder eine neue Version herunterladen wollen, kann es sein, dass die heruntergeladene Datei eine JAVA Datei ist (stanford-german-corenlp-2018-10-05-models.jar), die als Archiv genutzt wird. Um Dateien dieser Art zu entpacken, ist auf den meisten Betriebssystemen die Installation eines weiteren Programmes notwendig. Ein MacOS-Programm, das solche Dateien in einfache Ordner umwandeln kann, ist z. B. „Open All Files”, eines für Windows ist z. B. „WinZip”. Die aktuelle Java-Version (falls Sie noch keine auf Ihrem PC haben) finden Sie hier. Den vom → Deutschen Textarchiv (DTA) stammenden Primärtext in einer TXT-Version bekommen Sie hier als Direktdownload. Der Stanford Named Entity Recognizer benötigt keine Installation, sondern kann sofort genutzt werden.
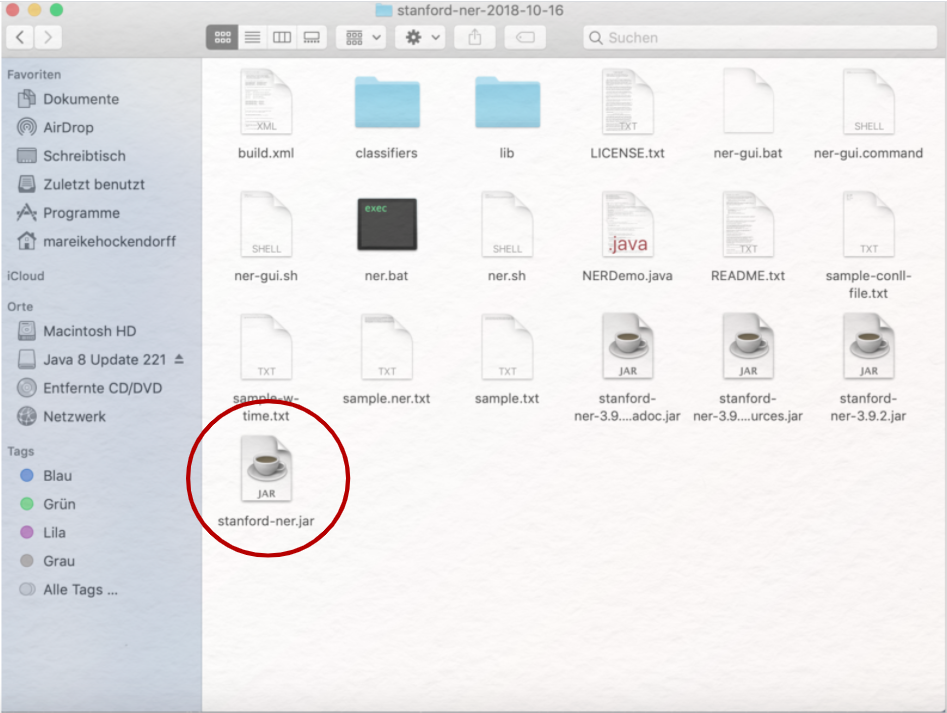
Entpacken Sie die ZIP-Datei, die Sie von der Homepage der Stanford Natural Language Group heruntergeladen haben, indem Sie doppelt auf den Archivordner klicken. Öffnen Sie den Ordner, der nun neu angelegt wurde, so sehen Sie darin mehrere Dateien und Unterordner. Je nach Version des Stanford Named Entity Recognizers und Ihres eigenen Betriebssystems, müssen Sie nun eine der ausführbaren Dateien öffnen. Eventuell müssen Sie dafür Ihre Sicherheitseinstellungen anpassen.
Für MacOS ist die in Abb. 1 eingekreiste JAR-Datei die richtige. Unter Windows probieren Sie am besten zuerst eine Datei, die GUI heißt (oben nicht im Bild). Öffnen Sie die Datei per Doppelklick, sollte sich eine einfache grafische Benutzeroberfläche zeigen:

Die Kategorien, die mit Hilfe des Tools automatisch annotiert werden können (Personen, Orte, Organisationen, Vermischtes), werden als „Classifier” bezeichnet und können über die obere Menüleiste geladen werden. Klicken Sie auf „Classifier” und dann auf „Load CRF from file”. CRF steht hier für Conditional Random Fields, eine statistische Konkretisierung der sequenziellen Modelle, die in den Classifiern angelegt sind (vgl. Sutton und McCallum 2010). Wählen Sie dann die aus der Dropbox heruntergeladene Datei „german.conll.germeval2014.hgc_175m_600.crf.ser.gz”. Nach einem kurzen Moment sollten sich an der rechten Seite der Benutzeroberfläche die Kategorien zeigen.
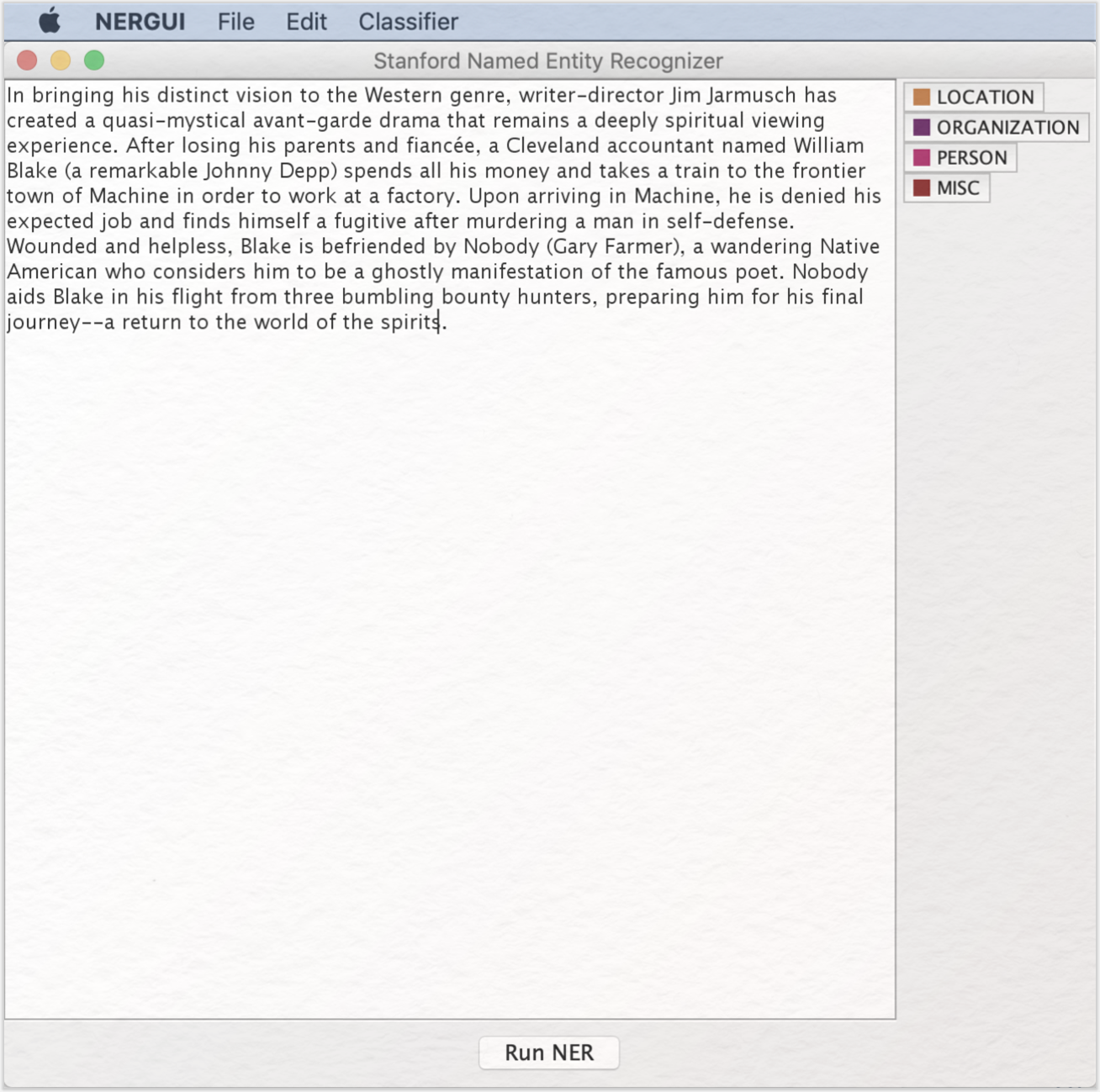
Jetzt gehen Sie in der oberen Menüleiste auf „File” und dann im Drop-Down-Menü auf „Open File”. Suchen Sie aus Ihrer Ordnerstruktur den Primärtext heraus und gehen auf „Öffnen”. Der Text zeigt sich in der Benutzeroberfläche des Tools:
3. Funktionen
Die Kernfunktion des Stanford Named Entity Recognizers – die automatische Annotation im Classifier festgelegter Kategorien – ist sehr einfach zu nutzen. Klicken Sie auf „Run NER” und warten Sie, bis die Schaltfläche nicht mehr blau unterlegt ist.
Aufgabe 1
Scrollen Sie durch Ihren annotierten Text und schauen Sie sich die in unterschiedlichen Farben markierten Eigennamen an. Was fällt Ihnen auf?
Die Qualität der Annotationen können Sie mit Hilfe des digitalen Annotationstools → CATMA messen. Speichern Sie dafür Ihr annotiertes Dokument. Gehen Sie dafür auf „File” und dann im Drop-Down-Menü auf „Save tagged file as”. Geben Sie der Datei einen Namen, der zeigt, dass es sich hierbei um eine annotierte Version der Wahlverwandtschaften handelt. Öffnen Sie dann die gespeicherte Datei mit einem Texteditor, der XML-Dateien erstellen kann. Für Windows ist z. B. Notepad ein solches Programm, für MacOS eignet sich BBEdit (ehemals TextWrangler). Öffnen Sie Ihre gerade gespeicherte Datei mit diesem Programm, so sehen Sie, dass der Stanford Named Entity Recognizer als Output eine TXT-Datei generiert hat, die HTML-Tags enthält. Damit ein anderes Programm wie z. B. CATMA erkennen kann, dass es sich um solche handelt (und nicht um Text), muss die Datei in eine vollständige XML-Datei umgewandelt werden. Dazu fügen Sie ganz oben einen sog. Opening-Tag ein. Dieser hat die Struktur <Ihr Opening Tag>. Fügen Sie jetzt den Opening-Tag <NER> ganz oben in Ihr Dokument ein (selbstverständlich können Sie auch eine andere Bezeichnung als „NER” wählen). Fügen Sie ganz unten im Dokument dann einen sog. Closing-Tag ein, der dazu passt. Für unser Beispiel ist </NER> der richtige Closing-Tag.


Gehen Sie dann auf „Speichern unter”, geben eine XML-Endung ein und setzen die Codierung auf UTF-8 (wenn diese Einstellung nicht automatisch vorgenommen wurde):
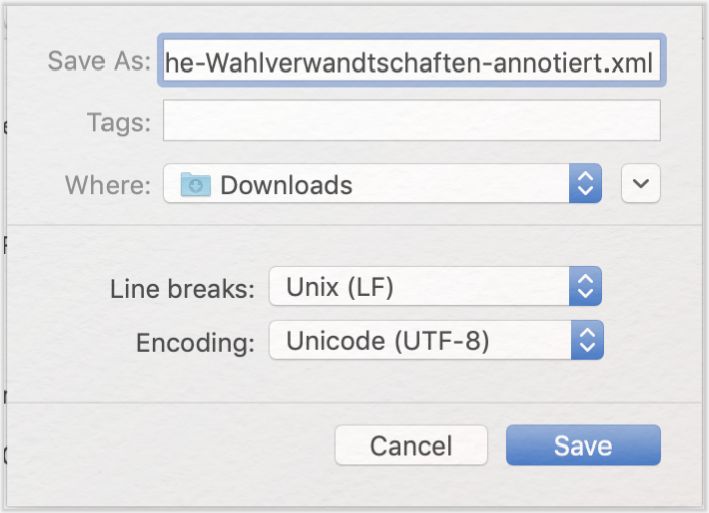
Sobald Sie die Datei als XML gespeichert haben, erscheinen die HTML-Tags nicht mehr als Text in schwarz, sondern werden in blau hervorgehoben:
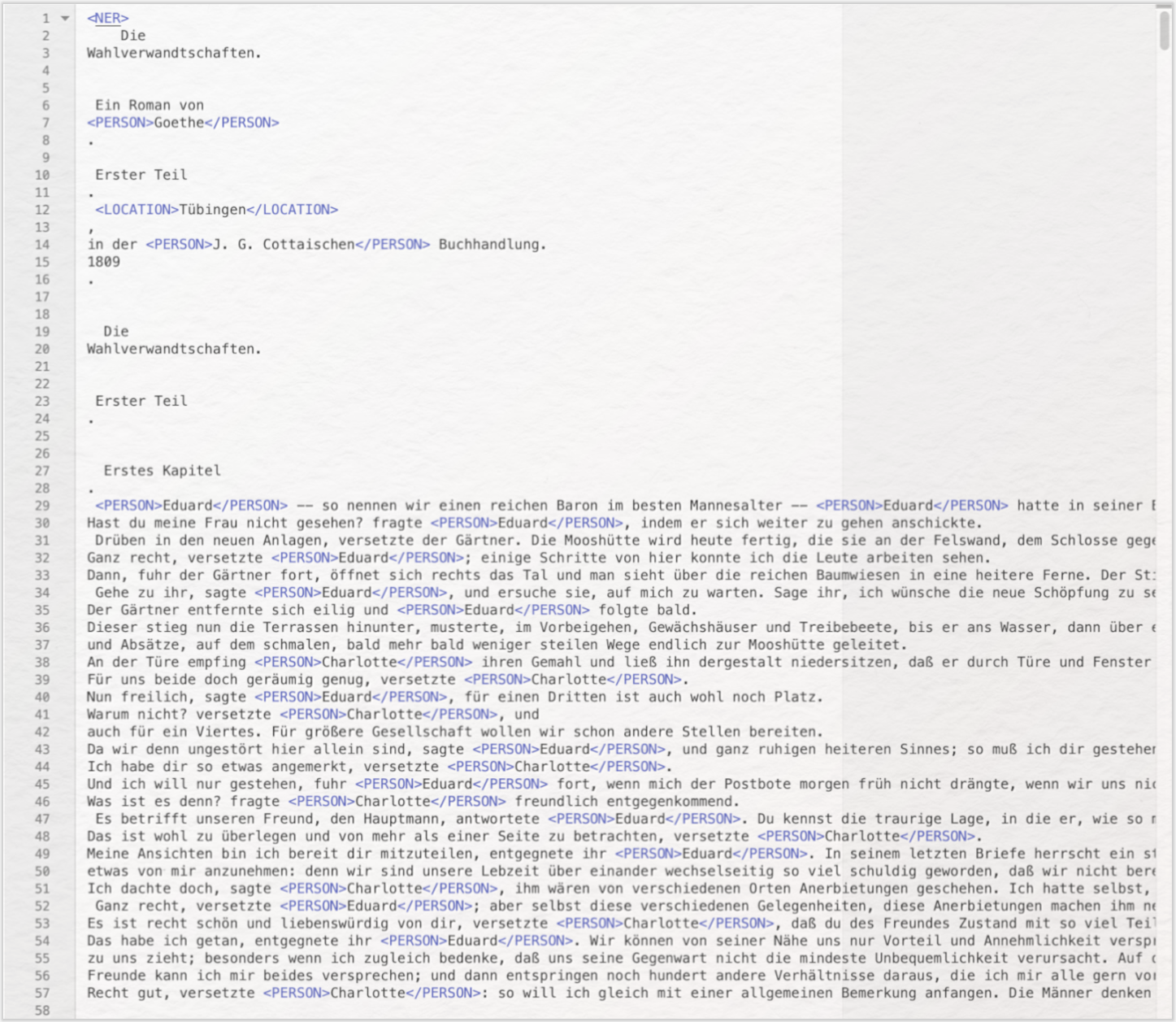
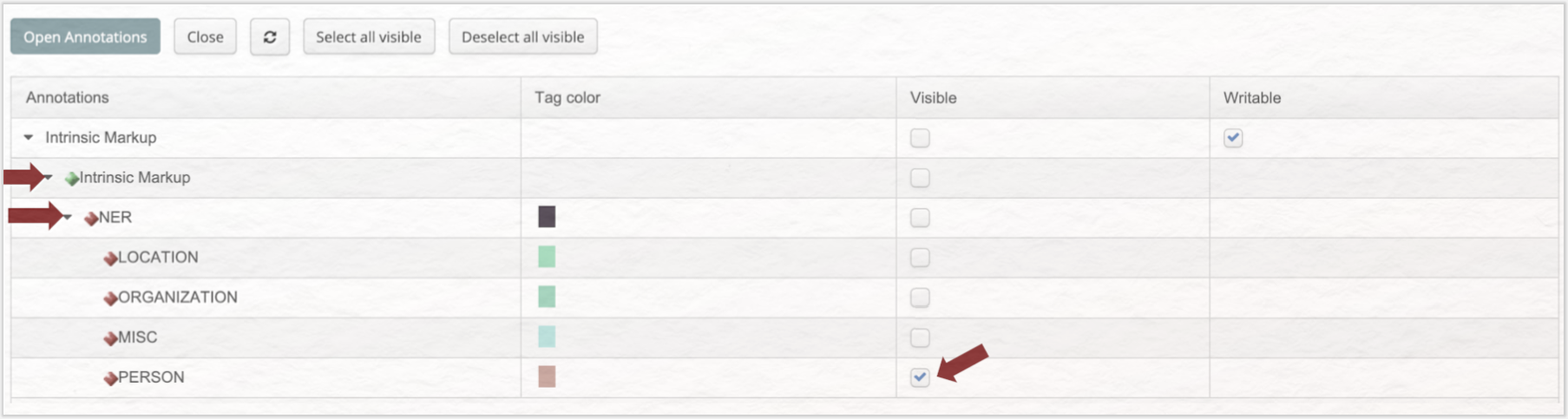
Gehen Sie nun zu CATMA und loggen Sie sich ein oder erstellen einen Account. Laden Sie über die Schaltfläche „Add Document” (es öffnet sich ein Upload-Assistent) Ihre XML-Datei hoch. Klicken Sie dann auf den kleinen Pfeil vor Ihrem Upload, sodass sich die Schaltfläche „Annotations” öffnet, dann auf den kleinen Pfeil vor „Annotations”, sodass „Intrinsic Markup” sichtbar wird. Wählen Sie „Intrinsic Markup” aus und klicken Sie auf „Open Annotations”.
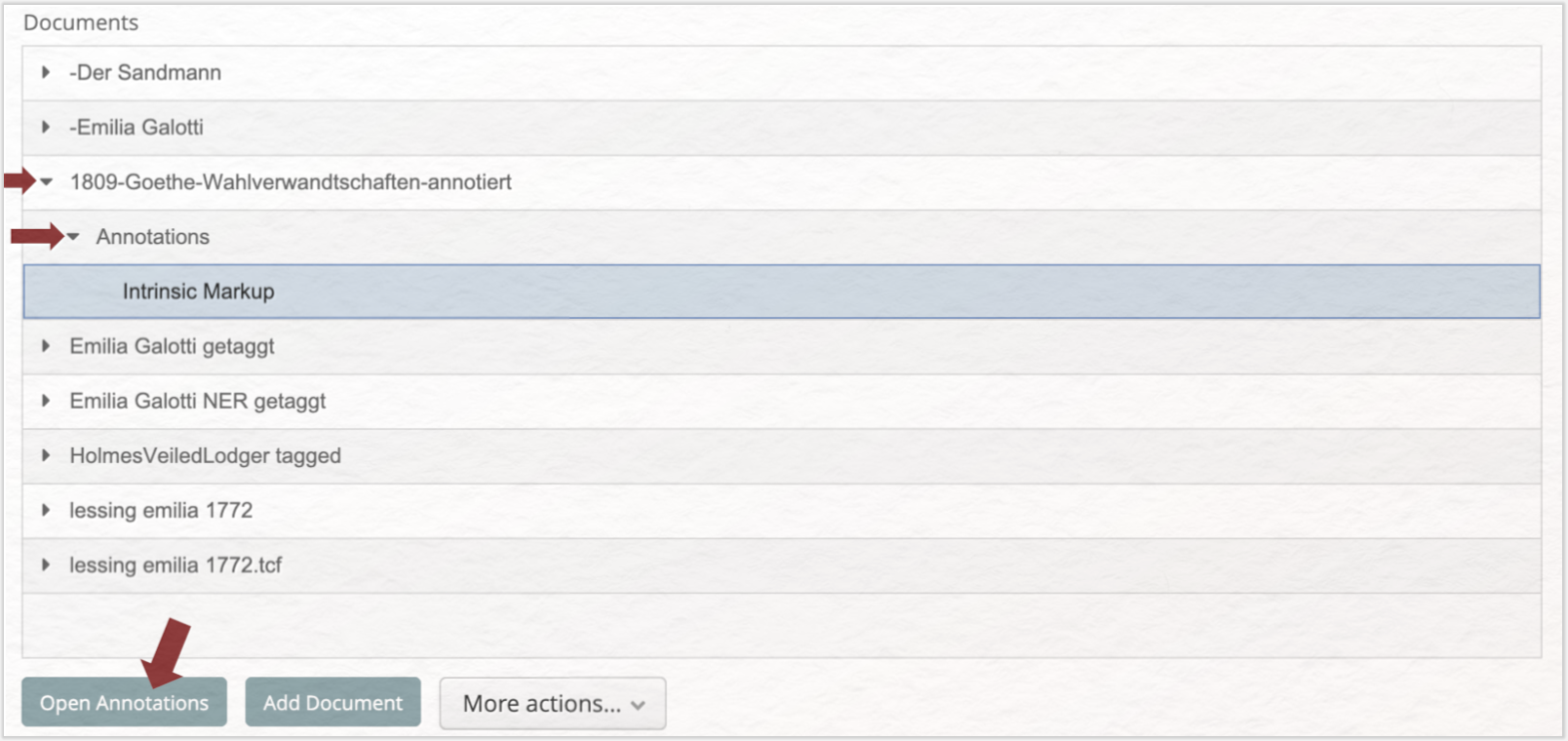
Wenn das Dokument geöffnet ist, klicken Sie erst auf den kleinen Pfeil vor „Intrinsic Markup” und dann auf den Pfeil vor „NER”. Setzen Sie nun einen Haken hinter „PERSON”, sodass alle gefundenen Personennamen unterstrichen dargestellt werden.
Wir berechnen nun die gängigen Bewertungskennzahlen für Named Entity Recognition, „Precision”, „Recall” und „F-Score” beispielhaft anhand der Kategorie PERSON. Dabei zeigt der „Precision”-Wert wie viele der annotierten Textstellen korrekt annotiert wurden. Der „Recall”-Wert gibt Aufschluss darüber wie viele der relevanten Textpassagen annotiert wurden. Mit der Berechnung des „F-Score” werden die beiden Werte mathematisch kombiniert, sodass sich ein Richtwert für die Bewertung des Modells ergibt.
Aufgabe 2
Zählen Sie nun auf den Seiten 2–6 (es handelt sich dabei um von CATMA vergebene Seiten) folgende Werte aus: Wie viele Textstellen hat der Stanford Named Entity Recognizer mit dem Tag „PERSON” belegt? Wie viele dieser Textstellen wurden fälschlich mit dem Tag „PERSON” annotiert? Wie viele Figuren wurden nicht gefunden (Achtung: Das Konzept der literarischen Figur geht über das der Eigennamen hinaus)? Berechnen Sie nun den Wert für „Precision” indem Sie die Zahl der korrekt gefundenen Personennamen durch die Gesamtzahl der mit dem Tag „PERSON” annotierten Textstellen dividieren. Berechnen Sie dann den Wert für „Recall”, indem Sie die Zahl der korrekt gefundenen Personennamen durch die Gesamtzahl der Personennamen dividieren. Berechnen Sie anschließend den F-Score nach folgender Formel: 2 x ((Precision x Recall) / (Precision + Recall)).
Dass die Werte insgesamt noch nicht ausreichend sind, um die automatische Annotation für die Literaturanalyse zu nutzen, liegt daran, dass das Tool für Sachtexte optimiert ist. Außerdem entspricht das linguistische Konzept der Entitäten nicht dem der literarischen Figur. Da der Stanford Named Entity Recognizer einige Funktionalitäten mitbringt, die das sogenannte Training eines eigenen Modells unterstützen, kann man hier allerdings nachhelfen. Das bedeutet, dass das Tool für das eigene Textkorpus optimiert werden kann.
Grundsätzlich gibt es dafür zwei Ansätze. Entweder wird ein korpusspezifisches, sehr enges Modell trainiert, dass für die eigene Analyse gute Ergebnisse erzielt. Die andere Möglichkeit ist, ein generisches Modell zu entwickeln, das auch auf andere Texte mit ähnlichen Eigenschaften übertragen werden kann. In dieser Lerneinheit trainieren wir ein Modell, dass für Goethes Wahlverwandtschaften optimiert ist und nicht gut auf andere Texte übertragen werden kann. Dazu legen wir zuerst ein Trainingskorpus an, das aus dem ersten Kapitel besteht, das wir per Copy/Paste in eine TXT-Datei überführen, die wir dann „GoetheWahlverwandtschaftenErstesKapitel.txt” nennen und in dem Ordner ablegen, in dem auch der Stanford Named Entity Recognizer liegt (Ordner-Name „stanford-ner-2018-02-27”). Wollten Sie ein übertragbares Modell trainieren, müssten Sie für das Trainingskorpus ungefähr gleich große Ausschnitte aus verschiedenen Texten zusammen kopieren, die ähnliche Eigenschaften wie die zu untersuchenden haben. Ein generisches Modell, dass auch für Goethes Wahlverwandtschaften gute Ergebnisse erzielen sollte wäre z. B. mit Hilfe eines Trainigskorpus erstellt, das folgende Eigenschaften besitzt: Erstellt aus zufällig ausgewählten Passagen aus 50 deutschsprachigen Romanen des 19. Jahrhunderts, Gesamtumfang mindestens 40.000 Tokens.
Erstellen Sie mit Hilfe des im Stanford Named Entity Recognizer enthaltenen Tokenizers aus Ihrem Trainingskorpus eine Wortliste. Öffnen Sie dazu die Commandline ihres Computers (auf dem Mac finden Sie diese unter Dienstprogramme → Terminal, bei Windows gehen Sie auf das Windows-Symbol unten links, geben dann cmd in die Suchleiste ein und wählen das entsprechende Programm aus). Gehen Sie nun in Ihrer Ordnerstruktur auf den Ordner, in dem der Stanford Named Entity Recognizer liegt. Nutzen Sie dafür den Commandline-Befehl „Change Directory”, der cd abgekürzt wird. Wenn der Stanford Named Entity Recognizer in Ihrem Downloads-Ordner ist, geben Sie also ein:
„cd downloads/stanford-ner-2018-10-16” (ohne die Anführungszeichen).
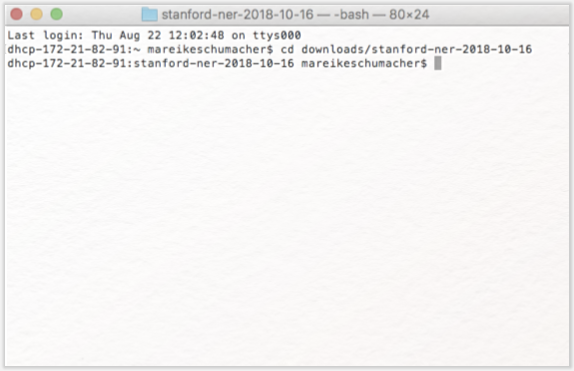
Ist dies nicht der Fall, ändern Sie den Befehl entsprechend Ihrer eigenen Ordner-Struktur. Geben Sie danach folgenden Befehl ein:
„java -cp stanford-ner.jar edu.stanford.nlp.process.PTBTokenizer GoetheWahlverwandtschaftenErstesKapitel.txt > GoetheWahlverwandtschaftenErstesKapitel.tok” (ohne Anführungszeichen).
Sobald Sie den Befehl mit Enter bestätigt haben, wird Ihr Computer ihn ausführen und eine Datei namens GoetheWahlverwandtschaftenErstesKapitel.tok im Stanford-Ordner entwerfen. Um Ihr Trainingskorpus so annotieren zu können, dass das Tool es später lesen kann, müssen Sie diese Datei nun noch in eine Tabelle umwandeln. Auch dafür hat der Stanford Named Entity Recognizer eine Funktion, die sie aufrufen, indem Sie Folgendes in Ihre Commandline tippen:
„perl -ne 'chomp; print "$_\tO\n"' GoetheWahlverwandtschaftenErstesKapitel.tok > GoetheWahlverwandtschaftenErstesKapitel.tsv” (ohne Anführungszeichen).
Die Tabelle, die Sie in Ihrem Stanford-Ordner finden, nachdem Ihr Computer den Befehl ausgeführt hat, öffnen Sie nun in einem Tabellenprogramm wie LibreOffice.
Aufgabe 3
Annotieren Sie Ihr Trainingskorpus, indem Sie bei jeder Figurenreferenz in der zweiten Tabellenspalte das O gegen das Wort Figur austauschen. Was fällt Ihnen beim Annotieren auf?
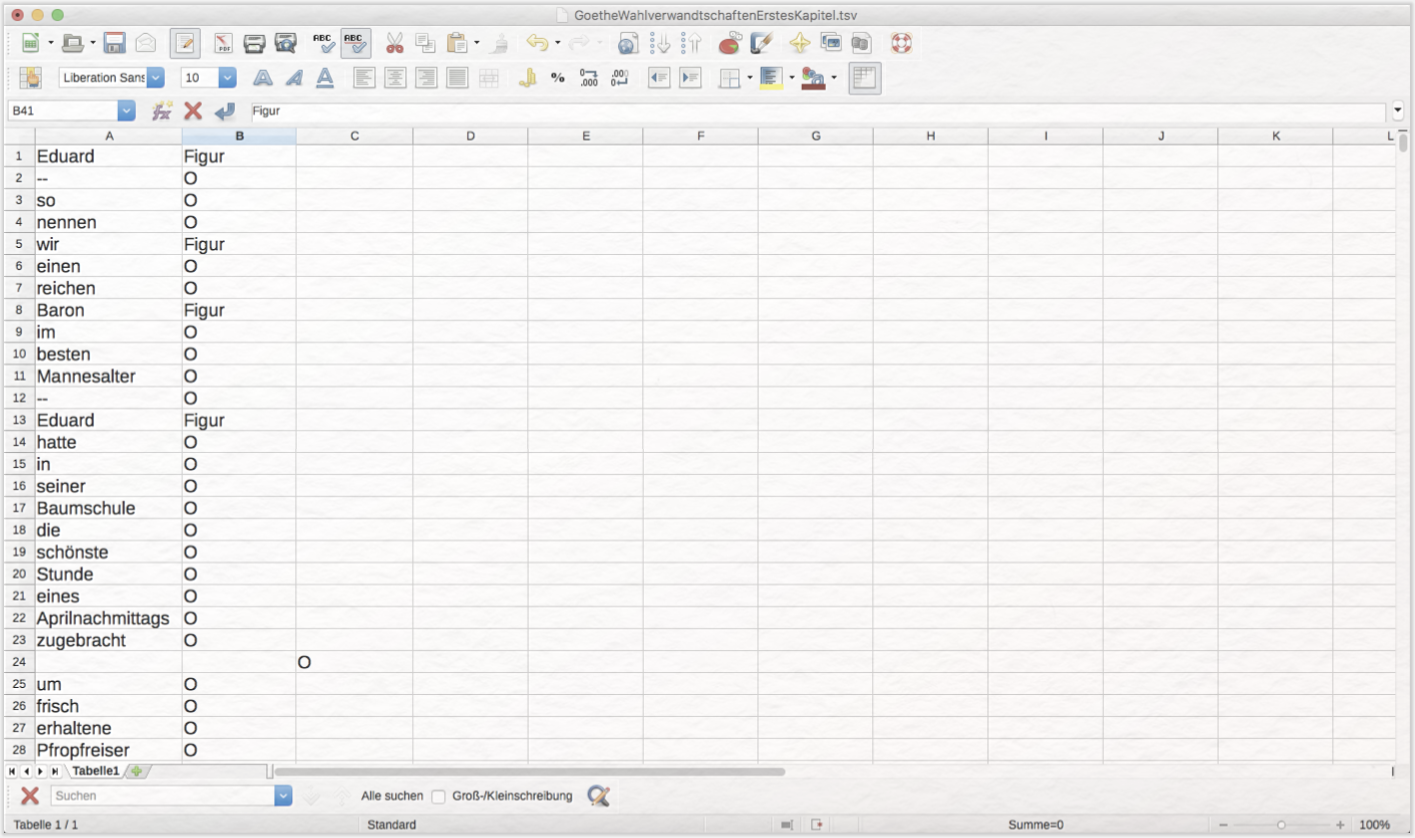
Sie haben nun Ihr eigenes Trainingskorpus erstellt. Dies ist ein zentraler Bestandteil für das Training des Stanford Named Entity Recognizers, da hier Beispiele der Kategorie, die Sie automatisch annotieren wollen im Satzzusammenhang enthalten sind. Neben diesen Beispielen benötigt das Tool noch eine Reihe von sogenannten Features, anhand derer die Beispiele analysiert werden können. Ein solches Feature wäre z. B. die Orthografie (Personennamen bestehen oft aus zwei Wörtern, die beide groß geschrieben sind), andere Feature-Beispiele sind vorangehende Wörter und nachgestellte Wörter. Der Stanford Named Entity Recognizer ist mit 15 solcher Features ausgestattet, die allerdings auch angepasst werden können. Sowohl die Trainingsdaten als auch die Features werden in einer Properties-Datei spezifiziert.
Erstellen Sie eine Properties-Datei, indem Sie in einem Programm wie BBEdit (Mac) oder Notepad (Windows) ein neues Dokument öffnen, in das Sie Folgendes hinein kopieren:
„trainFile = GoetheWahlverwandtschaftenErstesKapitel.tsv
serializeTo = ner-modelWahlverwandtschaften.ser.gz
map = word=0,answer=1
useClassFeature=true
useWord=true
useNGrams=true
noMidNGrams=true
maxNGramLeng=6
usePrev=true
useNext=true
useSequences=true
usePrevSequences=true
maxLeft=1
useTypeSeqs=true
useTypeSeqs2=true
useTypeySequences=true
wordShape=chris2useLC
useDisjunctive=true” (ohne Anführungszeichen).
Speichern Sie die Datei unter „GoetheWahlverwandtschaften.prop”. Sie können die Features anpassen, indem Sie die Liste der use-Befehle ergänzen. Weitere Features, die Sie ergänzen können, finden Sie hier.
Sie haben nun ein Trainingskorpus erstellt und manuell nach Ihren Vorstellungen annotiert. In Ihrer Properties-Datei haben Sie spezifiziert, welche Trainingsdatei verwendet werden soll und welche Features beim Training berücksichtigt werden. Sie sind nun startklar, um Ihr eigenes Modell erstellen zu lassen.
Aufgabe 4
Kopieren Sie folgenden Befehl in Ihre Commandline:
„java -cp stanford-ner.jar edu.stanford.nlp.ie.crf.CRFClassifier -prop GoetheWahlverwandtschaften.prop” (ohne Anführungszeichen).
Es kann eine Weile dauern, bis Ihr Computer das Training abgeschlossen hat. Anschließend finden Sie eine Datei namens ner-modelWahlverwandtschaften.ser.gz in Ihrem Stanford-Ordner. Sie können nun zurück zur grafischen Benutzeroberfläche des Stanford Named Entity Recognizers wechseln. Laden Sie über Classifier → Load Classifier → ner-modelWahlverwandtschaften.ser.gz Ihr eigenes NER-Modell in das Tool. Falls Sie die Benutzeroberfläche wieder neu öffnen mussten, rufen Sie über File → Open file Goethes Wahlverwandtschaften auf. Klicken Sie anschließend auf „Run-NER”. Schauen Sie sich die Ergebnisse Ihres Trainings an. Entsprechen Sie Ihren Erwartungen? Wie können Sie nun die Qualität Ihres Modells erfassen? Wie können Sie das Modell noch präziser werden lassen?
4. Lösungen zu den Beispielaufgaben
Aufgabe 1: Scrollen Sie durch Ihren annotierten Text und schauen Sie sich die in unterschiedlichen Farben markierten Eigennamen an. Was fällt Ihnen auf?
Der Stanford Named Entity Recognizer annotiert Figurennamen meist korrekt. Allerdings findet das Tool nicht alle Referenzen auf Personen. Personalpronomen und Beschreibungen bleiben z. B. unberücksichtigt. Für literarische Texte sind aber häufig gerade Beschreibungen, Spitznamen oder indirekte Referenzen auf Figuren interessant.
Aufgabe 2: Zählen Sie nun auf den Seiten 2–6 (es handelt sich dabei um von CATMA vergebene Seiten) folgende Werte aus: Wie viele Textstellen hat der Stanford Named Entity Recognizer mit dem Tag „PERSON” belegt? Wie viele dieser Textstellen wurden fälschlich mit dem Tag „PERSON” annotiert? Wie viele Figuren wurden nicht gefunden (Achtung: Das Konzept der literarischen Figur geht über das der Eigennamen hinaus)? Berechnen Sie nun den Wert für „Precision” indem Sie die Zahl der korrekt gefundenen Personennamen durch die Gesamtzahl der mit dem Tag „PERSON” annotierten Textstellen dividieren. Berechnen Sie dann den Wert für „Recall”, indem Sie die Zahl der korrekt gefundenen Personennamen durch die Gesamtzahl der Personennamen dividieren. Berechnen Sie anschließend den F-Score nach folgender Formel: 2 x ((Precision x Recall) / (Precision + Recall)).
Anzahl von Textstellen, die mit dem Tag PERSON belegt wurden: 27,
Anzahl von Textstellen ,die fälschlich mit dem Tag „PERSON” belegt wurden: 1,
Anzahl von Figurenreferenzen, die nicht gefunden wurden: 182.
(Ihre Zahl kann hier abweichen, wenn Sie ein anderes Konzept von Figur verfolgt haben als wir.)
Mit diesen Werten ist:
Precision = 0,96296 oder 96,3%,
Recall = 0,1244 oder 12,44% und
F-Score = 0,22034 oder 22,03%.
Das bedeutet, dass das Tool zwar relativ präzise Figuren erkennt, die meisten als Personen annotierten Passagen also tatsächlich auf Figuren verweisen. Der sehr niedrige Recall-Wert zeigt, dass nicht sehr viele Figurenreferenzen gefunden wurden. Das liegt hier vor allem daran, dass das Konzept der literarischen Figur mehr beinhaltet als nur die Bezeichnung einer Figur mit einem Eigennamen. Der F-Score kombiniert die beiden oberen Werte mathematisch. Das Ergebnis zeigt, dass eine Domänenadaption für die Literatur sehr sinnvoll ist, da vor allem der Recall-Wert verbessert werden muss. Das kann durch das Training eines eigenen NER-Modells erreicht werden.
Aufgabe 3: Annotieren Sie Ihr Trainingskorpus, indem Sie bei jeder Figurenreferenz in der zweiten Tabellenspalte das O gegen das Wort Figur austauschen. Was fällt Ihnen beim Annotieren auf?
Beim Annotieren müsste Ihnen aufgefallen sein, dass Sie ein möglichst klares Modell dessen verwenden sollten, was Sie als Kategorie annotieren lassen möchten. Haben Sie einen weiten Begriff von Figurenreferenzen, annotieren Sie vielleicht auch Possessivpronomen und Figurengruppen („wir”, „Männer”, „Frauen”). Bei einem engen Verständnis der Figur annotieren Sie vielleicht nur Namen, Spitznamen und Beschreibungen von Charakteren.
Aufgabe 4: Kopieren Sie folgenden Befehl in Ihre Commandline:
„java -cp stanford-ner.jar edu.stanford.nlp.ie.crf.CRFClassifier -prop GoetheWahlverwandtschaften.prop” (ohne Anführungszeichen).
Es kann eine Weile dauern, bis Ihr Computer das Training abgeschlossen hat. Anschließend finden Sie eine Datei namens ner-modelWahlverwandtschaften.ser.gz in Ihrem Stanford-Ordner. Sie können nun zurück zur grafischen Benutzeroberfläche des Stanford Named Entity Recognizers wechseln. Laden Sie über Classifier → Load Classifier → ner-modelWahlverwandtschaften.ser.gz Ihr eigenes NER-Modell in das Tool. Falls Sie die Benutzeroberfläche wieder neu öffnen mussten, rufen Sie über File → Open file Goethes Wahlverwandtschaften auf. Klicken Sie anschließend auf „Run-NER”. Schauen Sie sich die Ergebnisse Ihres Trainings an. Entsprechen Sie Ihren Erwartungen? Wie können Sie nun die Qualität Ihres Modells erfassen? Wie können Sie das Modell noch präziser werden lassen?
Vielleicht entsprechen die Ergebnisse, die Ihr eigenes Modell erzielt, noch nicht Ihren Erwartungen. Mit der Berechnung von Precision, Recall und F-Score können Sie genau messen, wie „gut” Ihr Modell ist. Sollte sich zeigen, dass die Werte noch nicht zufriedenstellend sind (F-Score von 50% und weniger), können Sie Folgendes tun:
- Erweitern Sie Ihr Trainingskorpus um 10.000 Tokens (selbstverständlich müssen Sie diese dann auch noch einmal in eine Wortliste und dann in eine Tabelle umwandeln, den Inhalt dieser Tabelle in Ihre erste bereits annotierte Tabelle hinein kopieren und die 10.000 zusätzlichen Tokens manuell annotieren).
- Diversifizieren Sie Ihr Trainingskorpus, indem Sie Ausschnitte aus unterschiedlichen Texten derselben Zeitspanne zusammen kopieren.
- Variieren Sie die Features, indem Sie der Feature-Liste in der Properties Datei weitere use-Befehle hinzufügen. Die genauen Befehle finden Sie in der Feature Factory von Stanford NLP.
5. Nachweise und weiterführende Literatur
- Sutton, Charles und Andrew McCallum (2010): „An Introduction to Conditional Random Fields“. URL: https://people.cs.umass.edu/~mccallum/papers/crf-tutorial.pdf [Zugriff: 22. August 2019].
| Dateianhang | Größe |
|---|---|
| 509.88 KB |
