1. Definition
In der digitalen Stilometrie werden Texte oder Textpassagen auf Grundlage statistischer Verteilungen (i. d. R. der häufigsten Wörter) stilistisch miteinander verglichen. So lässt sich beispielsweise die stilistische Entwicklung oder Differenzierung eines literarischen Textes, eines Œuvres, oder gar einer ganzen Epoche quantitativ nachvollziehen. Insbesondere werden stilometrische Methoden bei Autorschaftsattributionen, Genreklassifikationen, Epochendifferenzierungen oder auch in der forensischen Linguistik eingesetzt.
2. Anwendungsbeispiel
Sie beschäftigen sich mit einem unter Pseudonym veröffentlichten literarischen Text und möchten herausbekommen, wer die Verfasserin oder der Verfasser gewesen ist, um eine kontextsensitive literaturwissenschaftliche Analyse des Textes auf dieser Grundlage rechtfertigen zu können. Die Themenwahl, Figurenzeichnung, Plotentwicklung, das Setting oder auch der Stil erinnern Sie an andere Texte und Ihnen fallen drei Autorinnen ein (oder Sie ziehen dafür philologische Forschungsbeiträge zu Rate), die diesen Text potentiell geschrieben haben könnten. Sie stellen daher eine digitale Textsammlung aller Texte dieser Autorinnen zusammen, derer Sie habhaft werden können, und reichern diese Sammlung außerdem mit Texten weiterer vergleichbarer Autor*innen an, um die Möglichkeit fehlerhafter Ergebnisse zu minimieren. Eine digitale stilometrische Analyse wird Ihnen mit großer Zuverlässigkeit anzeigen, wem die Autorschaft des Textes am ehesten zugeschrieben werden kann.
3. Literaturwissenschaftliche Tradition
In mehreren Formen der literaturwissenschaftlichen Stilistik lassen sich Traditionslinien der digitalen Stilometrie ausmachen.
Die Stilanalyse bzw. Stilistik (damals noch mehr als normative Stilistik verstanden) löst als Textanalysemethode im späten 18. Jahrhundert die Rhetorik ab. Novalis erkannte 1798/99 in ihr „ungemein viel Aehnlichkeit mit der Declamationslehre – oder der Redekunst im strengern Sinne” (Czapla 2003, 515). Nach Schaffrick und Willand (2014, 29) richtet sich die Stilometrie „grundsätzlich an einer vergleichenden Fragestellung aus und stellt den Stil verschiedener Epochen, Werke, Gattungen oder […] Autoren gegenüber”. Manuell wurde dies bereits im 19. Jahrhundert vollzogen (vgl. Holmes 1998, 112; Kelih 2008, 31–44; Tuldava 2005, 370f.).
Die Stilanalyse als angewandte Stilforschung vor dem Hintergrund verschiedener Stiltheorien (vgl. Plummer, 2007, 734) wird von Meyer (2007, 70) auch als „Schlüsselqualifikation literaturwissenschaftlicher Arbeit” bezeichnet, da „Basiskenntnisse im Bereich der Stilanalyse eine Voraussetzung für jede professionelle Beschäftigung mit literarischen wie auch nichtliterarischen Texten” seien. Diese Schlüsselqualifikation findet in Form der digitalen Stilometrie ihre Tradition vor allem in quantitativ-stilistischen, aber auch in formalistisch und strukturalistisch ausgerichteten Stilanalysen.
In der formalistischen Stilanalyse Michael Riffaterres (vgl. Czapla 2003, 517) auch „Funktionalstilistik“ genannt) wird Stil als Normabweichung interpretiert (vgl. Meyer 2007, 74). In der strukturalistischen Stilanalyse wird hingegen die Regelhaftigkeit stilistischer Äquivalenz- und Oppositionsbeziehungen und damit die Erfüllung einer stilistischen Norm untersucht. Die strukturalistische Stilanalyse interessiert sich für „positive Merkmale einer poetischen Sprache, für artifizielle Gleichförmigkeiten (Isomorphien)” (Meyer 2007, 75). Sowohl die formalistische als auch die strukturalistische Stilanalyse können somit als Vorgänger der digitalen Stilometrie betrachtet werden, da sie sowohl Abweichungen als auch Isomorphien exploriert.
Ganz besonders jedoch knüpft die digitale Stilometrie an die Vorstöße der statistischen Stilanalyse an, die sich mit „Wortwiederholungshäufigkeiten, Wortverteilungshäufigkeiten, Strukturanalogien, Bildung semantischer Felder etc.” (Meyer 2007, 70) beschäftigt. Auch deshalb bezeichnet beispielsweise Czapla (2003, 515) die Stilistik als „Bindeglied zwischen Sprach- und Literaturwissenschaft”.
In der statistischen Stilanalyse begreift Doležel (1971, 253) Stil als „Wahrscheinlichkeitsbegriff”, d. h. unter der gegebenen Bedingung X (z. B. dass ein Text von einer bestimmten Autorin stammt) kommt die stilistische Erscheinung A (z. B. eine bestimmte Satzlänge) nur zu einer gewissen Wahrscheinlichkeit vor. Diese Art und Weise der Skizzierung von Stil arbeitet der späteren digitalen Modellierung bereits sehr entgegen und trägt der Tatsache Rechnung, dass eine Autorin, die für ihre kurzen Sätze bekannt ist, in ihren Texten auch längere Sätze schreiben kann und wird. Doležel (1971, 264) konstatiert außerdem: „[J]eder Text kann in einem multidimensionalen Raum beschrieben werden, in dem die Werte [der messbaren Textcharakteristiken] die individuellen Faktoren bilden” und nimmt damit eine Grundidee der digitalen Stilometrie vorweg.
4. Diskussion
Gern und häufig wird eine der bislang populärsten Verwendungen computergestützter stilometrischer Verfahren herangezogen, wenn es darum geht, die Wirkkraft dieser digitalen Methode zu veranschaulichen: Der unter dem Pseudonym „Robert Gailbraith" 2013 veröffentlichte Roman The Cuckoo’s Calling wurde mithilfe einer stilometrischen Analyse der Bestsellerautorin J. K. Rowling zugeschrieben, die sich daraufhin zur Autorschaft bekannte und dadurch nicht nur die Verkaufszahlen des Buches in die Höhe schnellen ließ, sondern nebenher auch noch die Methode selbst berühmt machte (vgl. Juola 2015). Der Algorithmus, der hinter diesem Verfahren steckt, heißt Burrows’ Delta und ist der am häufigsten angewendete in der computergestützten Stilometrie.
Die sog. Delta-Messung wird auch nach ihrem Erfinder „Burrows’ Delta” genannt (vgl. Burrows 2002). Bei dieser Methode wird Stil jedoch anders gedacht als in vielen der traditionelleren Stilanalysen: Statt semantischer Inhaltswörter werden hier besonders Funktionswörter betrachtet, oder um genau zu sein: die häufigsten Wörter (noch genauer: Tokens) eines Textes oder einer Textsammlung. Diese most frequent words (MFW) werden von Autor*innen „kaum bewusst manipuliert” (Jannidis 2014, 180) und bieten aufgrund ihres schlicht häufigeren Vorkommens eine verlässlichere Datenbasis für eine automatische Vergleichsanalyse als seltene Wörter.
Eine Charakterisierung des Stils einer bestimmten Autorin à la „XY benutzt besonders viele Neologismen” wird es in der digitalen Stilometrie daher nicht geben. Gerade im Zusammenhang mit der Untersuchung des Phänomens Autorenstil bedarf es jedoch numerischer Merkmale, die unabhängig von Textsorte, Thema und dem Verstreichen von Zeit wiederkehren (vgl. Jannidis 2014, 178). In der vergleichenden Stilanalyse Thomas und Heinrich Manns und Hermann Hesses untersucht Grimm (1991) daher beispielsweise die Vorkommnisse von syntaktischen, lexikalischen und morphologischen Mitteln, aber auch von Semikola oder Auslassungen durch drei Punkte. Da viele Autor*innen im Laufe ihres Lebens ihren Stil verändern (oder der Stil sich unbewusst verändert), ist es nach wie vor nicht gelungen, einen genuinen Autorenstil, der sich über das jeweilige Œuvre als Ganzes erstreckt, statistisch dingfest zu machen. Jannidis (2014) unterscheidet in diesem Zusammenhang einen starken und einen schwachen Begriff von Autorstil, wobei der starke Begriff sämtliche Texte eines Autors/einer Autorin meint, der schwache jedoch nur einige Texte. Die Konzentration auf den schwachen Begriff von Autorenstil macht es möglich, ein Œuvre als Ganzes zu begreifen und dennoch seine dynamische stilistische Entwicklung zu beschreiben.
„Welche Stilprinzipien jeweils für eine Epoche, Textsorte oder Autor-Individualität von tendenzieller Geltung sind und was dabei jeweils als sprachliche Angemessenheit, Ornamentik, Eleganz o. ä. postuliert wird, ist von zeitgebundenen Paradigmen abhängig” (Michel 2003, 520). Die digitale Stilometrie bringt mit ihrer Konzentration auf die most frequent words in den Kanon dieser Stilprinzipien eine neue Perspektive ein, die einen großen Erkenntniszuwachs bringt, die anderen Aspekte jedoch nicht ablösen kann: Über Ornamentik, Eleganz etc. von Texten vermag sie keine Aussage zu treffen.
Die digitale Stilometrie ist zudem rein textimmanent und kann extratextuelle Zeichen wie z. B. die Beschaffenheit des Manuskripts mit all seinen stilistischen Zusatzinformationen, die in der Druckfassung verloren gegangen sind (vgl. Meyer 2007, 78), nicht mit deuten. Dies ist freilich ein generelles Problem vieler digitaler Methoden und betrifft insbesondere die → Möglichkeiten der Textdigitalisierung und die → digitale Manuskriptanalyse.
Die Konzentration auf ein bestimmtes Stilmerkmal beim Vergleich unterschiedlicher Texte, Gattungen oder Œuvres macht die Stilanalyse jedoch handhabbar, oder wie Jannidis (2014, 172) zusammenfasst: „Deutlich moderater wäre ein Test, dem es gelingt, aufgrund bestimmter Merkmale und Merkmalskombinationen die Texte eines Autors von den Texten anderer Autoren zu unterscheiden, also ein individualisierendes oder unterscheidendes Verfahren”. Man sollte die vergleichsweise unbewusste Verwendung von häufigen Funktionswörtern in Texten jedoch nicht mit einer Art ‘stilistischem Fingerabdruck’ von Autor*innen gleichsetzen, denn einzigartige Merkmale oder Merkmalsbündel, die Stil individuell definitiv bestimmen, gibt es nicht. Stilometrische Verfahren liefern stattdessen wahrscheinliche Autorschaftszuschreibungen und diese Wahrscheinlichkeit kann höher oder niedriger sein (vgl. Jannidis 2014, 183).
Neben der Autorschaftsattribution kann die stilometrische Analyse nach Burrows in weiteren Zusammenhängen fruchtbar gemacht werden: So lässt sie Rückschlüsse auf Textsortenzugehörigkeiten, Œuvreperiodisierungen, Übersetzungsstilistiken, Epochenzusammenhänge, Genderzugehörigkeiten etc. zu. Es hat sich zudem gezeigt, dass die Wahl der Menge der häufigsten Wörter sprachabhängig ist (vgl. Rybicki und Eder 2011), da „bei Sprachen mit größerer morphologischer Formenvielfalt zu erwarten [ist], daß die relative Häufigkeit der häufigen Wörter insgesamt weniger groß ist” (Bock et al. 2016, 9). Rybicki und Eder (2011) kommen in ihren Experimenten daher zu dem Ergebnis, dass Burrows’ Delta am besten mit englischen oder deutschen Prosatexten funktioniert.
Die quantitative digitale Stilometrie ermöglicht einen neuen Blick auf Stile in Textsammlungen. Für gute Ergebnisse ist eine ausreichende (möglichst große) Datengrundlage jedoch unumgänglich. Ist diese gegeben, spricht die Qualität der Ergebnisse für sich: Sie sind mit so hoher Wahrscheinlichkeit korrekt, dass die Verfahren sogar in der forensischen Linguistik Anwendung finden und als vor Gericht haltbar gelten können (vgl. Fobbe 2011, 109f.). Dieser quantitative Blick ist jedoch nur eine Perspektive auf Stil und kann und will (insbesondere bei kürzeren Texten) die qualitative Stilanalyse nicht ersetzen (vgl. Tuldava 2005, 369).
5. Technische Grundlagen
Die stilometrische Analyse mit Burrows’ Delta betrachtet die häufigsten Wörter der Textsammlung. In Burrows’ eigenem Beispiel sind das die 30 häufigsten Wörter und diese MFW (most frequent words) bezeichnet er als „markers of potentially equal power” (Burrows 2002, 271) für Stildifferenzen. Nun ist es bei nach Häufigkeiten angeordneten Wortlisten so, dass die Zahlenwerte sehr schnell abfallen, dass also beispielsweise die ersten 3 bis 5 Wörter sehr viel häufiger vorkommen als die Wörter 6–10 usw. Damit die häufigsten dieser häufigen Wörter das Ergebnis der stilometrischen Analyse nicht allein dominieren, sondern alle 30 häufigsten Wörter in der Berechnung ein gleiches Gewicht bekommen, wird nicht mit Rohwerten, sondern mit dem sog. z-score gerechnet. Im z-score wird vom Zahlenwert der häufigsten Wörter der Mittelwert abgezogen und das Ergebnis wird durch die Standardabweichung (d. h. die durchschnittliche Streuung um den Mittelwert) geteilt.
Um schließlich das Delta zu berechnen, werden die 30 (bzw. n) z-scores des einen Textes oder der einen Textsammlung von den 30 z-scores des anderen Textes oder der anderen Textsammlung abgezogen. Diese Differenzen werden aufaddiert und das Ergebnis wird durch die gewählte Menge der häufigsten Wörter (in diesem Beispiel 30) geteilt. Bei dieser rechnerischen Komplexitätsreduktion kommt ein numerischer Wert heraus; Delta kann also in einer Zahl angegeben werden und wird auch als Distanzmaß bezeichnet (vgl. Schöch 2017, 292). Kleinere Deltawerte (im Verhältnis zu allen in einem Analysedurchgang jeweils errechneten Deltawerten) stehen laut dieser Berechnung für größere stilistische Nähe bzw. für kleinere stilistische Differenz. Eine etwas ausführlichere Erläuterung dieser Rechnung findet sich bei Jannidis (2014, 183–185). Eine Vereinfachung der Formel (bei welcher der Mittelwert herausgekürzt und somit der Bezug auf einen normgebenden Haupttext geschmälert wird) bietet Argamon (2007).
Bei der quantitativen Berechnung stilistischer Unterschiedlichkeit entstehen schnell Werte, die durch eine Vielzahl von Faktoren bestimmt werden. Wenn in einer Textsammlung von nur 10 Texten beispielsweise die jeweils 30 häufigsten Wörter stilometrisch analysiert werden sollen (in tatsächlichen stilometrischen Analysen sind es häufig sowohl sehr viel mehr Texte als auch eine größere Anzahl der MFW; vgl. bspw. Rybicki und Eder 2011), lässt sich jeder einzelne Text durch einen Vektor mit 30 Zahlen repräsentieren: die Frequenzen der jeweils häufigsten 30 Wörter. Dadurch nimmt jeder Text einen spezifischen Punkt in einem 30-dimensionalen Raum ein.
Um dieses hochdimensionale Raumkonstrukt greifbar zu machen, werden die 30 Dimensionen auf zwei Achsen reduziert. Dazu braucht man die sog. principal component analysis (PCA). Anstatt für jedes Wort eine neue Dimension zu eröffnen, bildet dabei die Varianz selbst die Grundlage für die neu definierten Dimensionen: x-Achse = PC1 und y-Achse = PC2 (bei Bedarf noch eine z-Achse = PC3). Entlang der Achse Principal Component 1 werden somit die Texte in Bezug auf die größte Varianz aufgefächert, entlang der Achse Principal Component 2 in Bezug auf die zweitgrößte Varianz usw. Damit hat man in der Regel schon eine so große Menge an Daten abgedeckt, dass weitere Principal Components vernachlässigt werden können, ohne dass der Informationsverlust zu groß wäre.
Die Reduktion auf zwei Dimensionen bietet den großen Vorteil, dass sämtliche Texte einer stilometrischen Analyse innerhalb eines Koordinatensystems wie auf einer Karte visualisiert werden können, in dem räumliche Nähe (da Delta ein Distanzmaß ist) auch für stilistische Nähe steht. (Zu den Chancen und Risiken von unterschiedlichen Datenvisualisierungen vgl. → Textvisualisierung). Statt die Vollständigkeit der gesamten Daten abzubilden, liegt der Fokus der PCA-Analyse also auf Aspekten, die für die stilistische Varianz von besonderer Bedeutung sind (vgl. Bock et al. 2016; Tweedie 2005, 388).
Bei dieser und auch den im Folgenden erwähnten Verfahren und Möglichkeiten der Ergebnisvisualisierung bestimmen immer Sie selbst die jeweiligen Parameter, die in die Analyse einbezogen werden, und auch die Ergebnisse müssen von Ihnen vor dem Hintergrund Ihres literaturwissenschaftlichen Fachwissens gedeutet werden. Diese Aufgaben kann die digitale Methode nicht übernehmen.
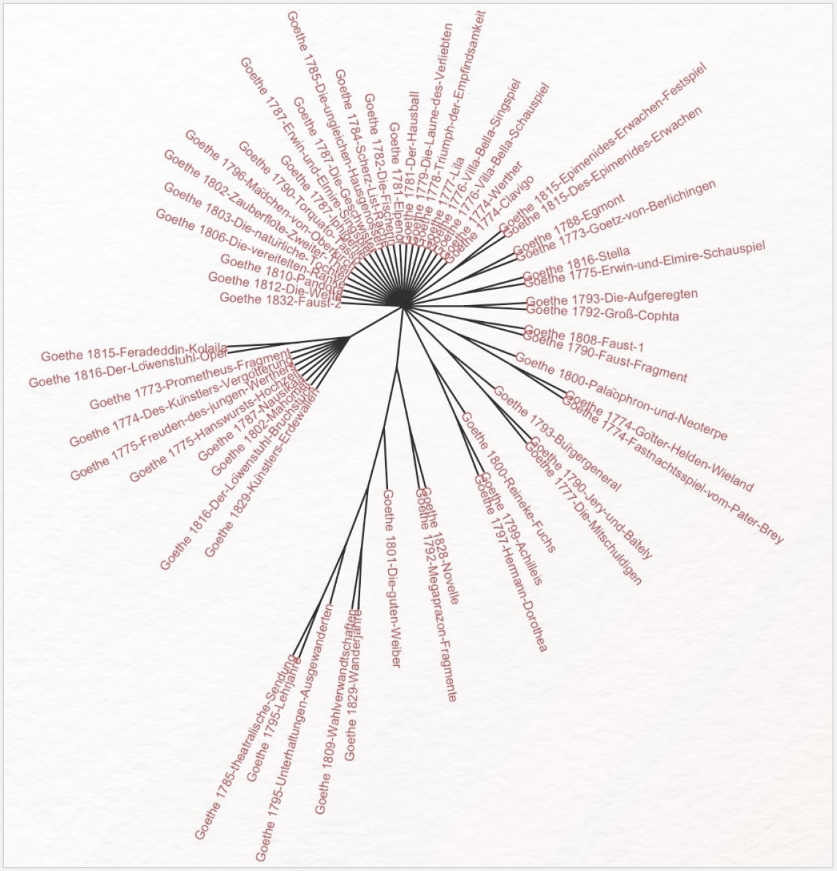
Eine häufiger verwendete Möglichkeit, stilistische Nähe von Texten zu visualisieren, ist die Darstellung in einem Baumdiagramm oder Dendrogramm, bei dem i. d. R. die vertikale Anordnung von Textgruppen in sog. Clustern auf den gleichen Ästen des Diagramms die stilistische Nähe dieser Texte zueinander anzeigt.
Die in diesem Beitrag aufgeführte Visualisierung (s. o.) nennt sich Bootstrap Consensus Tree und wurde mit → Stylo (s. nächsten Absatz) erstellt. Sie zeigt die stilistische Varianz von Goethes dramatischem und epischem Œuvre. Die Visualisierung beruht (im Gegensatz zum Dendrogramm) auf wiederholten und vergleichenden Durchläufen der Berechnung mit unterschiedlichen Parametern (bspw. jeweils unterschiedlich viele MFW) und zeigt stilistisch ähnliche Texte an den gleichen Ästen an. Dabei werden nur diejenigen Ähnlichkeiten angezeigt, die in einem vorher festgelegten prozentualen Anteil der Analysedurchläufe auftreten. Die Entfernung vom Zentrum hat dabei keine semantische Aussagekraft, sondern ist lediglich der visuellen Darstellbarkeit geschuldet.
Auch für Einsteiger*innen nach kurzer Einführung relativ leicht zugänglich und nutzbar ist das sog. „Stylo"-Package (vgl. Eder, Kestemont und Rybicki 2016), das in der Java-basierten statistischen Programmierumgebung R kostenlos angewendet werden kann und bei Bedarf sogar über eine grafische interaktive Benutzeroberfläche verfügt. Die grundlegenden Befehle werden hier über speziell dafür eingerichtete Buttons ausgeführt und Skript- oder Codekenntnisse sind (bis auf das Laden und Starten des Programms) nicht zwangsläufig vonnöten.
6. Nachweise und weiterführende Literatur
- Argamon, Shlomo (2007): „Interpreting Burrows’s Delta: Geometric and Probabilistic Foundations“. In: Literary and Linguistic Computing. 23 (2), 131–147.
- Burrows, John (2002): „Delta: A Measure for Stylistic Difference and a Guide to Likely Authorship“. In: Literary and Linguistic Computing. 17 (3), 267–287.
- Czapla, Ralf Georg (2003): „Stilistik“. In: Reallexikon der deutschen Literaturwissenschaft. Neubearbeitung des Reallexikons der deutschen Literaturgeschichte, Bd. 3: P-Z. Berlin, New York: de Gruyter, 515–518.
- Doležel, Lubomír (1971): „Ein Begriffsrahmen für die statistische Stilanalyse“. In: Jens Ihwe (Hrsg.): Literaturwissenschaft und Linguistik. Ergebnisse und Perspektiven, Bd. 1: Grundlagen und Voraussetzungen. Frankfurt am Main: Athenäum, 253–273.
- Eder, Maciej, Jan Rybicki und Mike Kestemont (2016): „Stylometry with R: A Package for Computational Text Analysis“. In: The R Journal. 8 (1), 107–121.
- Fobbe, Eilika (2011): Forensische Linguistik. Eine Einführung. Tübingen: Narr.
- Grimm, Christian (1991): Zum Mythos Individualstil. Mikrostilistische Untersuchungen zu Thomas Mann. Würzburg: Königshausen & Neumann.
- Holmes, David I. (1998): „The Evolution of Stylometry in Humanities Scholarship“. In: Literary and Linguistic Computing. 13 (3), 111–117. DOI: 10.1093/llc/13.3.111.
- Jannidis, Fotis und Gerhard Lauer (2014): „Burrows’s Delta and Its Use in German Literary History“. In: Matt Erlin und Lynne Tatlock (Hrsg.): Distant Readings: Topologies of German Culture in the Long Nineteenth Century. Rochester, New York: Camden House, 29–54.
- Juola, Patrick (2006): „Authorship Attribution“. In: Foundations and Trends in Information Retrieval. 1 (3), 233–334. DOI: 10.1561/1500000005.
- Juola, Patrick (2015): „The Rowling Case: A Proposed Standard Analytic Protocol for Authorship Questions“. In: Digital Scholarship in The Humanities. 30 (1), 100–113. DOI: 10.1093/llc/fqv040.
- Kelih, Emmerich (2008): Geschichte der Anwendung quantitativer Verfahren in der russischen Sprach- und Literaturwissenschaft. Hamburg: Kovač.
- Meyer, Urs (2007): „Stilanalyse“. In: Thomas Anz (Hrsg.): Handbuch Literaturwissenschaft, Bd. 2: Methoden und Theorien. Stuttgart, Weimar: Metzler, 70–80.
- Michel, Georg (2003): „Stilprinzip“. In: Reallexikon der deutschen Literaturwissenschaft. Neubearbeitung des Reallexikons der deutschen Literaturgeschichte, Bd. III: P-Z. Berlin, New York: de Gruyter, 518–521.
- Bock, Sina, Keli Du, Michael Huber, Stefan Pernes und Steffen Pielström (2016): „Der Einsatz quantitativer Textanalyse in den Geisteswissenschaften: Bericht über den Stand der Forschung“. In.:
- Plummer, Patricia (2007): „Stilistik“. In: Dieter Burdorf; Christoph Fasbender und Burkhard Moenninghoff (Hrsg.): Metzler Lexikon Literatur. Begriffe und Definitionen. Stuttgart, Weimar: Metzler, 734.
- Rybicki, Jan und Maciej Eder (2011): „Deeper Delta Across Genres and Languages: Do We Really Need the Most Frequent Words?“ In: Literary and Linguistic Computing. 26 (3), 315–321.
- Schaffrick, Matthias; und Marcus Willand (Hrsg.) (2014): Theorien und Praktiken der Autorschaft. Berlin, Boston: de Gruyter.
- Schöch, Christof (2017): „Quantitative Analyse“. In: Fotis Jannidis; Hubertus Kohle und Malte Rehbein (Hrsg.): Digital Humanities. Eine Einführung. Stuttgart: Metzler, 279–298.
- Stamatatos, Efstathios (2009): „A Survey of Modern Authorship Attribution Methods“. In: Journal of the American Society for Information Science and Technology. 60 (3), 538–556. DOI: 10.1002/asi.21001.
- Tuldava, Juhan (2005): „Stylistics, author identification“. In: Reinhard Köhler; Gerold Ungeheuer und Herbert Ernst Wiegand (Hrsg.): Quantitative Linguistik: ein internationales Handbuch. Berlin, New York: de Gruyter, 368–387.
- Tweedie, Fiona J. (2005): „Statistical Models in Stylistics and Forensic Linguistics“. In: Reinhard Köhler; Gerold Ungeheuer und Herbert Ernst Wiegand (Hrsg.): Quantitative Linguistik: ein internationales Handbuch. Berlin, New York: de Gruyter, 387–397.
