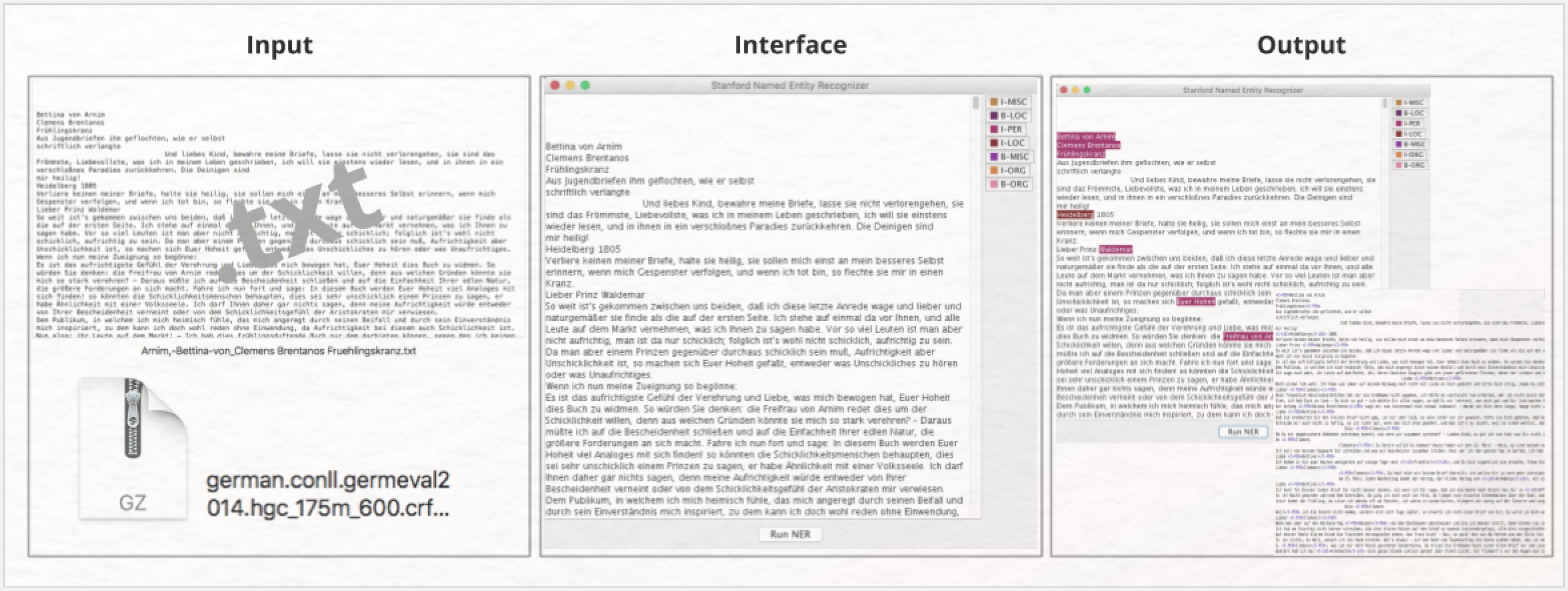
Systemanforderungen: Läuft auf Windows und Mac, benötigt aktuelle Java-Version
Stand der Entwicklung: Seit der Erstveröffentlichung 2006 laufend aktualisiert und für weitere Sprachen angepasst
Herausgeber: Stanford Natural Languages Processing Group
Lizenz: Open Source Tool, das kostenfrei genutzt werden kann
Weblink: https://nlp.stanford.edu/software/CRF-NER.html#About
Im- und Export: Import einzelner Texte als TXT-Datei, Export als TXT-Datei mit HTML-Tags
Sprachen: Deutsch, Englisch, Spanisch, Chinesisch, Italienisch, Ungarisch
1. Für welche Fragestellungen kann Stanford-NER eingesetzt werden?
Mit Stanford-NER können vor allem Fragen nach quantitativen Aspekten von Figurennamen, Orten und Organisationen bearbeitet werden (vgl. → Named Entity Recognition (NER)). Dazu gehören Fragen wie: Wie viele Figuren werden in einem Text benannt? Welche Figuren werden am häufigsten erwähnt? Wie ist die Verteilung von Ortsnennungen im Text? Welche Orte werden erwähnt? In welchem Kontext werden Organisationen genannt?
2. Welche Funktionalitäten bietet Stanford-NER und wie zuverlässig ist das Tool?
Funktion: Eigennamenerkennung in Texten zahlreicher Sprachen.
Zuverlässigkeit: Die höchste Zuverlässigkeit wird in Sachtexten erreicht. Hier liegt die Erkennungsquote für deutschsprachige Texte bei rund 70% F-Score (mehr zur Methode der Named Entity Recognition und ihren Qualitätskriterien finden Sie hier). Auf der Stanford-NER-Homepage wird darauf hingewiesen, dass das deutsche Modell von 2018 erheblich besser ist, es werden aber keine genauen Zahlen genannt. Damit erreicht der Stanford-NER eine vergleichsweise hohe Zuverlässigkeit. Bei der Anwendung auf literarische Texte wird eine weit geringere Zuverlässigkeit erreicht. Diese kann allerdings durch die Anpassbarkeit des Tools erhöht werden.
3. Ist Stanford-NER für DH-Einsteiger*innen geeignet?
| Checkliste | √ / teilweise / – |
|---|---|
| Methodische Nähe zur traditionellen Literaturwissenschaft | √ |
| Grafische Benutzeroberfläche | √ |
| Intuitive Bedienbarkeit | √ |
| Leichter Einstieg | √ |
| Handbuch vorhanden | – |
| Handbuch aktuell | – |
| Tutorials vorhanden | teilweise |
| Erklärung von Fachbegriffen | – |
| Gibt es eine gute Nutzerbetreuung? | teilweise |
Das Stanford-NER-Tool ist in seiner Grundfunktionalität sehr einsteigerfreundlich. Bisher wurde das Tool hauptsächlich in der Computerlinguistik eingesetzt. Um das Tool für die Literaturwissenschaft anzupassen, sind einige technische Grundkenntnisse vonnöten. Die Nutzerbetreuung findet hauptsächlich in der recht aktiven NLP-Community statt und kann je nach Frage in Schnelligkeit und Qualität der Antwort variieren.
4. Wie etabliert ist Stanford-NER in den (Literatur-)Wissenschaften?
Stanford-NER ist ein sehr gängiges computerlinguistisches Tool, das Gegenstand in zahlreichen Publikationen ist. In der Literaturwissenschaft ist es noch nicht etabliert, da eine Domänenadaption hier gerade erst beginnt.
5. Unterstützt Stanford-NER kollaboratives Arbeiten?
Stanford-NER ist ein Java-basiertes Desktop-Tool, das ohne weitere Installation offline über den eigenen PC ausgeführt wird. Kollaboratives Arbeiten wird dadurch nicht unterstützt.
6. Sind meine Daten beim Stanford-NER sicher?
Ja. Da es sich um ein desktopbasiertes Tool handelt, ist keine Anmeldung und/oder Angabe personenbezogener Daten für die Nutzung notwendig. Texte werden auf dem eigenen Rechner analysiert und Ergebnisse werden lokal gespeichert. Durch die Nutzung des Stanford-NER ergeben sich also keine datenschutz- oder urheberrechtlich bedenklichen Situationen.
7. Nachweise und weiterführende Literatur
- Stanford-Core-NLP auf GitHub: https://github.com/stanfordnlp/CoreNLP [Zugriff: 12. Juli 2018].
- Stanford-NLP Named Entity recognition Results: https://nlp.stanford.edu/projects/project-ner.shtml [Zugriff: 12. Juli 2018].
