Systemanforderungen: Die kostenfreie Demoversion ist für eine maximale Textgröße von 1000 Wörtern ausschließlich webbasiert nutzbar, die kostenpflichtige LIWC-Version steht für Windows- und Mac-Betriebssysteme zur Verfügung (Ausnahme: nicht kompatibel mit Windows XP und Macintosh OSX10.7.x – Lion)
Stand der Entwicklung: In den 1990er Jahren entwickelt, 2001 erstveröffentlicht, aktuelle Version: LIWC2015 v1.6
Herausgeber: LIWC Inc. (James W. Pennebaker, Roger J. Booth, Martha E. Francis)
Lizenz: Kommerzielle Version mit unterschiedlicher Laufzeit bzw. variierendem Funktionalitätsumfang (LIWCLITE 7, LIWC 2007, LIWC 2015), Lizenzmodelle mit Vergünstigungen für die Verwendung in Bildung und Forschung, Nutzung der LIWC-API nach erfolgreicher Bewerbung und genauen Angaben zum Verwendungszweck
Weblink: https://www.liwc.app
Im- und Export: Import von Dateien in den Formaten DOCX, DOC, TXT, RTF, PDF, XLSX, XLS, CSV; Export der Ergebnisse in diversen und mit SPSS, R, SAS, SciPy oder Weka kompatiblen Formaten wie TXT, CSV oder als Excel-Datei
Sprachen: Arabisch, Chinesisch, Niederländisch, Englisch, Deutsch, Französisch, Italienisch, Portugiesisch, Russisch, Serbisch, Spanisch und Türkisch
1. Für welche Fragestellungen kann LIWC eingesetzt werden?
Ursprünglich entwickelt, um Essays aus Experimenten zum expressiven bzw. therapeutischen Schreiben zu untersuchen (vgl. Wolf et al. 2008), eignet sich LIWC („Linguistic Inquiry and Word Count") für die Analyse diverser Textsorten wie persönlichen, subjektiven Texten, E-Mail-Korrespondenzen, Social-Media-Beiträgen wie Tweets oder Blogeinträgen, Werbetexten oder wissenschaftlichen Texten. Das Tool wurde in unterschiedlichen Studien zu persönlichkeits-, sozial- und klinisch-psychologischen Fragestellungen und für die Analyse von therapeutischen Essays, Alltagskommunikation, computervermittelter Kommunikation (vgl. Vergani 2015; Back, Küfner und Egloff 2011), (politischen) Reden (vgl. Abe 2011) sowie genderspezifischer Sprache (vgl. Newman et al. 2008) eingesetzt und gilt als zuverlässiges Softwareprogramm zur quantitativen Textanalyse (vgl. Hai-Jew 2016; Wolf et al. 2008; Proyer und Brauer 2018; Pennebaker und Chung 2008). Literaturwissenschaftlich relevante Fragestellungen, die Sie mit LIWC untersuchen können, betreffen die textbasierte Erforschung der emotionalen Dimension literarischer Texte wie beispielsweise: Welche emotionalen Affekte (wie Angst oder Aggressivität) prägen Edgar Allan Poes Kurzgeschichte The Tell-Tale Heart? Überwiegen die positiven oder die negativen Emotionen in Lewis Carrolls Alice in Wonderland und wie lässt sich die emotionale Tonalität der Novelle beschreiben? Untersucht werden können zudem Fragestellungen mit personenbezogenem Fokus wie „Welche persönlichen Eigenschaften lassen sich den Korrespondenzteilnehmern des Briefwechsels zwischen Samuel Clarke und Gottfried Wilhelm Leibniz zuordnen?”
2. Welche Funktionalitäten bietet LIWC und wie zuverlässig ist das Tool?
Die Konzeption des Tools basiert auf der Grundannahme, dass sich die Persönlichkeit des Menschen in der Sprache widerspiegelt, die er verwendet. LIWC liegt die auf gesprächstherapeutischer Forschung basierende Annahme zugrunde, dass die Analye der verwendeten Funktionswörter, die in der Kommunikation zumeist unbewusst eingesetzt werden (wie z. B. Pronomen, Artikel und Konjunktionen), besonders aussagekräftig ist. Rückschlüsse auf sich im Inneren des Verfassers abspielende Prozesse lassen sich folglich u. a. durch die Analyse der „kleinen” Wörter ziehen. Die Verwendung von Inhaltswörtern (Substantive, Adjektive und Verben), die zwar die Bedeutung eines Satzes tragen, aber deutlich stärker von externen Faktoren (wie der Vorgabe eines bestimmten Themas) beeinflusst werden, spielt bei der Analyse eine sekundäre Rolle. Inhaltliche Zusammenhänge werden bei der Textanalyse mit LIWC gänzlich ausgeblendet.
LIWC führt eine automatisierte Ein-Wort-Analyse (word-by-word basis) auf Basis eines v. a. von Psycholog*innen entworfenen Lexikons durch. Sobald Sie im Besitz einer kommerziellen LIWC-Version sind, können Sie die Wörterbücher einsehen, insofern Sie die Demoversion verwenden, stehen diese jedoch nicht zur freien Verfügung. Es gilt zu bedenken, dass sich alltägliche Sprache und innerliterarische, innerkünstlerische Sprache erheblich unterscheiden. Eine LIWC-basierte Analyse eines literarischen Textes – unter Rückgriff auf ein eher psychophysisch, alltagssprachlich ausgerichtetes Wörterbuch – ist fragwürdig: Emotivität ist in literarischen Texten auf andere Art und Weise kodiert als anderen Textgattungen. Darüber hinaus finden sich Emotionen als textuelle Phänomene nicht nur auf allen sprachlichen Ebenen (Morpheme, Wörter, Sätze). Die Informationsstruktur des gesamten Textes ist emotionskonstituierend und -ausdrückend, literarische Texte weisen unterschiedliche emotionale Dimensionen auf (vgl. Schwarz-Friesel 2017), die durch eine Ein-Wort-Analyse kaum erfasst werden können. Nach dem Erwerb einer lizenzierten Version können Sie allerdings nicht nur das deutschsprachige LIWC-Lexikon herunterladen, sondern auch eigens erstellte Lexika integrieren. Bei der Konzeption (in Word oder Excel) und Implementierung (als .txt-Datei, die allerdings auf .dic endend abgespeichert werden muss) müssen Sie die LIWC-Syntax beachten. Hierbei können Sie z. T. reguläre Ausdrücke verwenden, was die Erstellung eines umfassenden textsortenspezifischen Lexikons erleichtert (indem Sie z. B. sämtliche Flexionsformen eines Wortes durch ein * am Ende des Stammwortes abfragen).
In der Standardeinstellung greift LIWC auf das integrierte englischsprachige LIWC-Lexikon aus dem Jahr 2015 zurück. Bei Bedarf können Versionen aus den Jahren 2001 und 2007 aktiviert werden. Darüber hinaus wurde das LIWC-Lexikon nicht nur in die deutsche, sondern auch in diverse weitere Sprachen (italienisch, norwegisch, spanisch, brasilianisch, portugiesisch, französisch, niederländisch, russisch, traditionelles wie vereinfachtes Chinesisch) übertragen. Für die Mehrzahl der LIWC-Kategorien kann eine gute Äquivalenz der deutschen Version mit dem englischen Original bestätigt werden, für einige basislinguistischen Kategorien wurden allerdings Unterschiede festgestellt (vgl. Wolf et al. 2008).
Funktionen:
Bei der Verwendung der ausschließlich mit englischsprachigen Texten funktionierenden Demoversion u. a.:
- Automatisierte Ein-Wort-Analyse (word-by-word basis): Im Kern nutzt dieses Analyseverfahren einen Wortzählalgorithmus, der die Wörter eines Textes auszählt und diese vorab definierten und in einem internen Wörterbuch organisierten Wortkategorien zuordnet (vgl. Wolf et al. 2008). Die Analyse spielt sich folglich ausschließlich auf der lexikalischen Ebene ab und basiert auf dem Abgleich des hochgeladenen individuellen Textes mit dem implementierten LIWC-Lexikon.
- Auskunft über prozentualen Anteil der I-Words (I, me, my), der Social Words, der Positive Emotions, der Negative Emotions und der Cognitive Processes.
- Die Variable Analytical Thinking erfasst den Grad, in dem die schreibende Person Wörter verwendet, die auf formale, logische und hierarchische Denkstrukturen verweisen.
- Clout beschreibt den sozialen Status bzw. das Selbstbewusstsein und Führungsverhalten, das die schreibende Person zum Ausdruck bringt.
- Authenticity erfasst, ob die schreibende Person authentisch und ehrlich kommuniziert.
- Emotional Tone erfasst, ob dem untersuchten Dokument ein überwiegend positiver oder negativer Ton zugrunde liegt.
- Darüber hinaus werden vergleichende Daten zur Verfügung gestellt, die zeigen, wie Texte derselben Kategorie durchschnittlich zusammengesetzt sind.
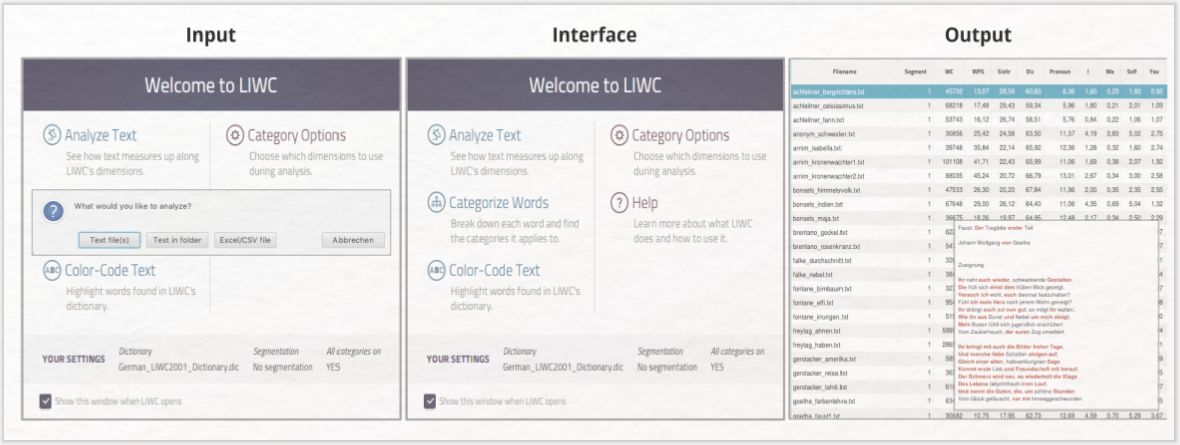
Die kommerzielle Variante des Tools beinhaltet drei Darstellungsweisen der Ein-Wort-Analyse:
- Analyze Text ist eine tabellarische Übersicht der Analyseergebnisse des gesamten Dokuments (Dokumentebene).
- Categorize Text bietet eine Liste sämtlicher Wörter mit Angabe der jeweiligen Kategorie (Wortebene).
- Color-Code Text ist eine Ansicht des gesamten Textes bei farblicher Hervorhebung derjenigen Wörter, die einer Kategorie zugeordnet wurden (Satzebene).
Zuverlässigkeit: LIWC funktioniert zuverlässig. Sofern Sie keine einzelnen Texte, sondern ein größeres Textkorpus untersuchen möchten, kann der Analyseprozess jedoch einige Zeit dauern.
3. Ist LIWC für DH-Einsteiger*innen geeignet?
| Checkliste | √ / teilweise / – |
|---|---|
| Methodische Nähe zur traditionellen Literaturwissenschaft | teilweise |
| Grafische Benutzeroberfläche | √ |
| Intuitive Bedienbarkeit | √ |
| Leichter Einstieg | √ |
| Handbuch vorhanden | √ |
| Handbuch aktuell | √ |
| Tutorials vorhanden | √ |
| Erklärung von Fachbegriffen | √ |
| Gibt es eine gute Nutzerbetreuung? | √ |
Detaillierte Erklärungen der Funktionalitäten finden Sie auf der LIWC-Homepage und im Operator's Manual. Darüber hinaus helfen Ihnen Tutorials dabei, LIWC schrittweise kennenzulernen und unterschiedliche Funktionen – wie z. B. die Konzeption eines individuellen Lexikons – auszuführen. Relevante Funktionen lassen sich dank einer intuitiv bedienbaren Benutzeroberfläche aber auch ohne die Konsultation eines Handbuchs und technisches Vorwissen ausführen. Nutzeranfragen per E-Mail werden zuverlässig und in kurzer Zeit beantwortet.
4. Wie etabliert ist LIWC in den (Literatur-)Wissenschaften?
In seinem ursprünglichen Forschungsbereich – der Psychologie – ist das Tool etabliert, auch wenn es aufgrund des Außerachtlassens komplexerer Bedeutungsstrukturen durchaus kontrovers diskutiert wird. In der Literaturwissenschaft wurde das Tool bisher kaum verwendet, obwohl es sich durch die Möglichkeit, ein individuelles deutschsprachiges Lexikon zu integrieren, durchaus für die Analyse deutschsprachiger Texte eignet und Untersuchungen zufolge bspw. für die Analyse lyrischer Texte oder Erzählungen in Frage käme (vgl. Wolf et al. 2008 zur Analyse von Hermann Hesses Siddhartha). Eine literaturwissenschaftliche Adaption wäre außerdem möglich, da sich die intuitiv bedienbare GUI von LIWC mit der Verwendung von existierenden Sentimentwörterbüchern wie SentiWS oder – besser noch – domänenspezifischen, eigens entworfenen Sentimentwörterbüchern (→ Sentimentanalyse), die z. B. historische und orthographische Besonderheiten einbeziehen, kombinieren ließe. Es gilt festzuhalten, dass für die Analyse deutsprachiger literarischer Texte ein Lexikon benötigt wird, welches durch spezifische Analysekategorien der Beschaffenheit literarischer Texte gerecht wird.
5. Unterstützt LIWC kollaboratives Arbeiten?
Nein, LIWC ist für die Einzelarbeit konzipiert.
6. Sind meine Daten bei LIWC sicher?
Ja, sobald Sie eine LIWC-Version erworben haben, wird das Tool desktopbasiert ausgeführt. Hier sind Ihre Textdaten sicher. Zur Zahlungsabwicklung müssen Sie personenbezogene Daten angeben, was sich bei der Verwendung der Demoversion erübrigt.
7. Nachweise und weiterführende Literatur
- Abe, Jo Ann A. (2011): „Changes in Alan Greenspan’s Language Use Across the Economic Cycle: A Text Analysis of His Testimonies and Speeches“. In: Journal of Language and Social Psychology. 30 (2), 212–223. DOI: 10.1177/0261927X10397152.
- Back, Mitja D., Albrecht C. P. Küfner und Boris Egloff (2011): „Automatic or the People? Anger on September 11, 2001, and Lessons Learned for the Analysis of Large Digital Data Sets“. In: Psychological Science. 22 (6), 837–838. DOI: 10.1177/0956797611409592.
- Hai-Jew, Shalin (2016): „Extracting Linguistic Patterns from Texts with LIWC (‚luke‘) for Analysis“. In: C2C Digital Magazine (Fall 2016 / Winter 2017). 16–25.
- Newman, Matthew L., Carla J. Groom, Lori D. Handelman und James W. Pennebaker (2008): „Gender Differences in Language Use: An Analysis of 14,000 Text Samples“. In: Discourse Processes. 45 (3), 211–236. DOI: 10.1080/01638530802073712.
- Proyer, René T. und Kay Brauer (2018): „Exploring adult playfulness: Examining the accuracy of personality judgments at zero-acquaintance and an LIWC analysis of textual information“. In: Journal of Research in Personality. 73, 12–20. DOI: 10.1016/j.jrp.2017.10.002.
- Pennebaker, James W. und Cindy K. Chung (2008): „Computerized Text Analysis of Al-Qaeda Transcripts“. In: Klaus Krippendorf und Mary Angela Bock (Hrsg.): The content analysis reader. Los Angeles (u.a.): SAGE Publications, 453–467.
- Vergani, Matteo und Ana-Maria Bliuc (2015): „The evolution of the ISIS’ language: A quantitative analysis of the language of the first year of Dabiq magazine“. In: Sicurezza, terrorismo e società. 2, 7–20.
- Schwarz-Friesel, Monika (2017): „Das Emotionspotenzial literarischer Texte“. In: Anne Betten; Ulla Fix und Berbelin Wanning (Hrsg.): Handbuch Sprache in der Literatur, Bd. 17. Berlin, Boston: de Gruyter, 351–370.
- Wolf, Markus, Andrea Mehl, Matthias Severin, Haug Severin, James W. Pennebaker und Hans Kordy (2008): „Computergestützte quantitative Textanalyse: Äquivalenz und Robustheit der deutschen Version des Linguistic Inquiry and Word Count“. In: Diagnostica. 54 (2), 85–98. DOI: 10.1026/0012-1924.54.2.85.
