Eckdaten der Lerneinheit
- Anwendungsbezug: Gotthold Ephraim Lessings bürgerliches Trauerspiel Emilia Galotti
- Methode: Distant Reading und Textvisualisierung
- Angewendetes Tool: Voyant
- Lernziele: Textauswahl und Nutzung elementarer Voyant-Funktionalitäten: Erstellen einer Stoppwortliste, Arbeit mit dem Voyant-Toolkit, Export der erstellten Visualisierungen und deren Interpretation
- Dauer der Lerneinheit: ca. 60 Minuten
- Schwierigkeitsgrad des Tools: einfach
Bausteine
- Anwendungsbeispiel
Welche Texte werden analysiert? Untersuchen Sie Lessings Emilia Galotti mittels Distant Reading-Verfahren und interpretieren Sie die unterschiedlichen Visualisierungen der Textanalyse. - Vorarbeiten
Welche Arbeitsschritte müssen vor der Textanalyse erledigt werden? Laden Sie sich den Primärtext herunter und speisen diesen in die Voyant-Tools ein. - Funktionen
Welche Funktionen bietet Voyant für die digitale Textanalyse? Lernen Sie ausgewählte Tools, deren Analysefunktionen und Visualisierungsformen kennen. - Lösungen zu den Beispielaufgaben
Haben Sie die Beispielaufgaben richtig gelöst? Hier finden Sie die Antworten.
1. Anwendungsbeispiel
In dieser Lerneinheit werden Sie Lessings bürgerliches Trauerspiel Emilia Galotti mit dem Textanalysetool → Voyant untersuchen. Voyant vereint Distant-Reading-Verfahren und Formen der → Textvisualisierung. Im Hintergrund der Voyant-Tools steht die Methode des Distant Readings. Im Rahmen einer quantitativen Analyse werden Texte statistisch ausgewertet. Die einzelnen und individuell auswählbaren Voyant-Tools visualisieren die Ergebnisse dieser quantitativen Textanalyse auf ganz unterschiedliche Art und Weise. Distant-Reading-Verfahren eignen sich sowohl für die Exploration großer Textmengen (z. B. das Œuvre von Autor*innen) als auch für die Analyse vergleichsweise kleiner Textmengen (wie einzelner Werke). Für die erste Auseinandersetzung mit digitalen Methoden der Textanalyse und -visualisierung werden wir einen Einzeltext mithilfe von Voyant untersuchen.
2. Vorarbeiten
Zu Beginn beinahe jeder Form der digitalen Textanalyse steht die Frage nach der Textauswahl: Woher bekomme ich genau die Texte, die ich untersuchen möchte, oder sogar ein bereits zusammengestelltes thematisch passendes Textkorpus, das in brauchbarer Form digital vorliegt? Das → Deutsche Textarchiv (DTA) stellt eine etablierte Anlaufstelle für die Beantwortung dieser Frage dar. Hier werden Sie nun Ihren Untersuchungsgegenstand Emilia Galotti für die Analyse mit Voyant herunterladen. Suchen Sie die Homepage des DTA auf, indem Sie hier klicken. Nun befinden Sie sich auf der Startseite des DTAs und geben den passenden Suchbegriff in das Suchfeld ein (siehe Abb. 2).
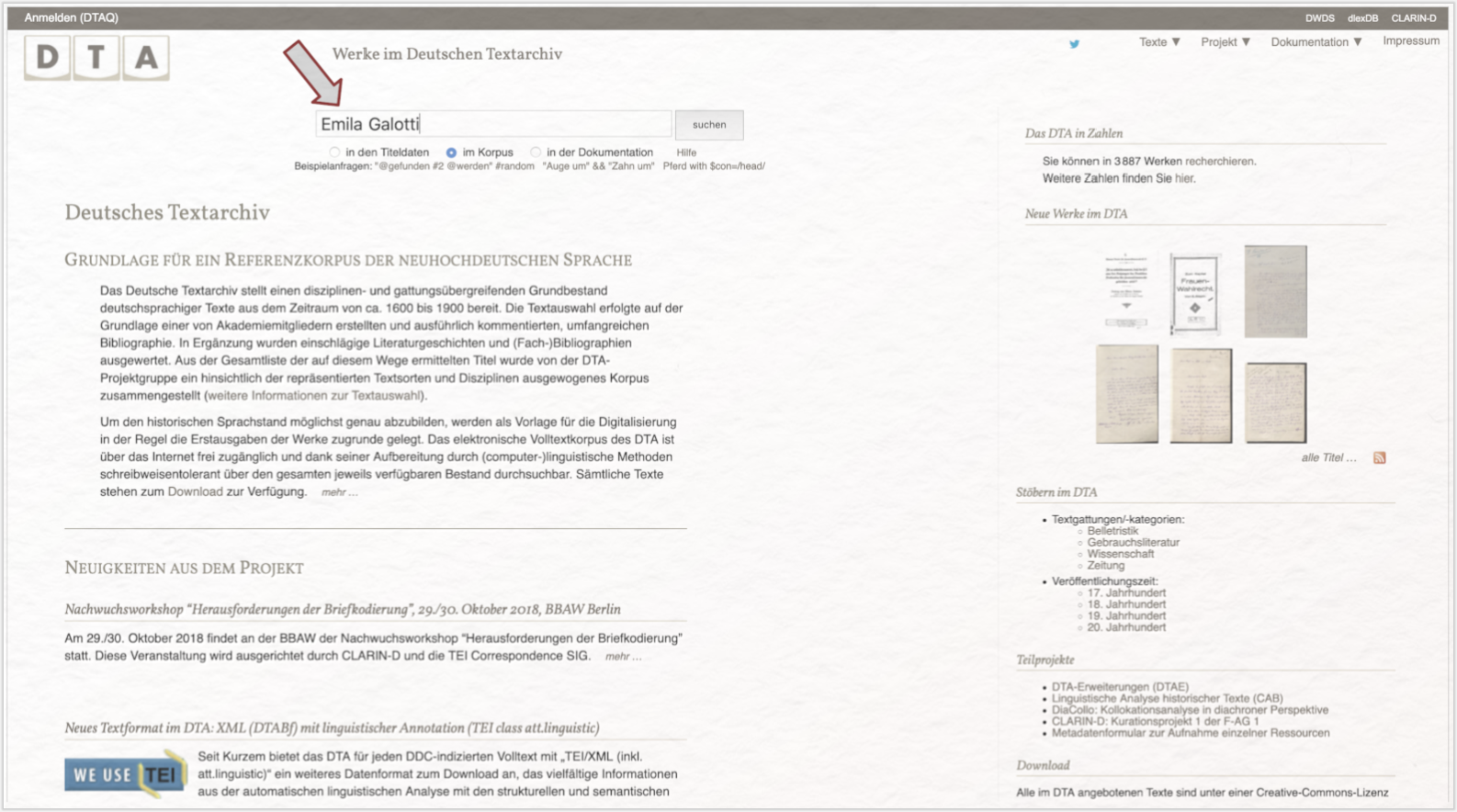
Unter den Suchergebnissen befindet sich neben unterschiedlichen Werken, in denen der Suchbegriff vorkommt, auch unsere Primärquelle Emilia Galotti von Lessing. Per Mausklick auf den mit „#5” gekennzeichneten Primärtext gelangen Sie in einem nächsten Schritt zu einer detaillierten dreiteiligen Werkansicht.
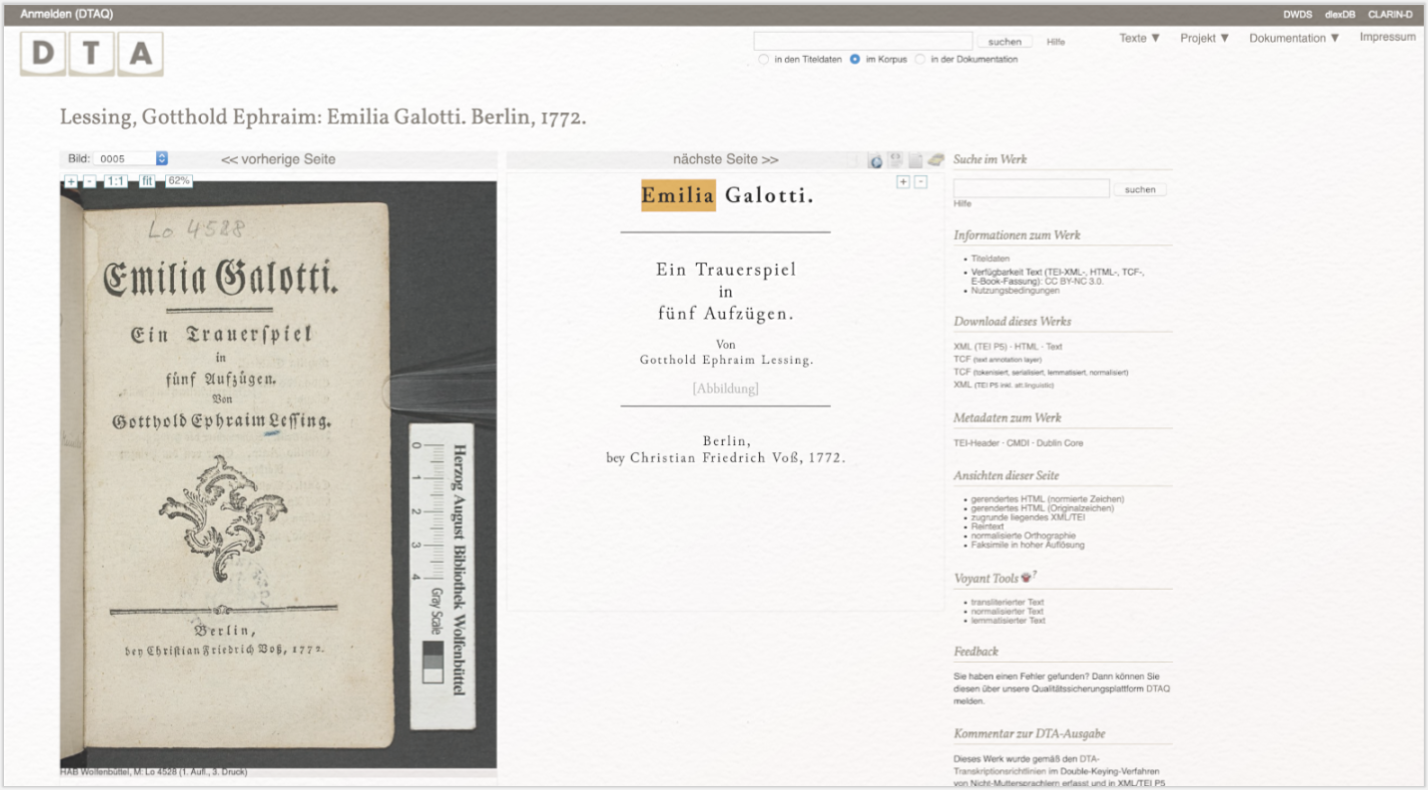
Hinweis: Durch eine Kooperation zwischen dem DTA und Voyant-Tools besteht bei einigen der im Repositorium enthaltenen Texte die Möglichkeit, die gewünschte Quelle direkt über die Seite des DTAs in Voyant zu importieren. Da Download und Import von Datensätzen als Teil der Korpuserstellung einen essentiellen Bestandteil der digitalen Textanalyse darstellen, werden wir in dieser Lerneinheit den „Umweg” über das eigenhändige Herunterladen des Textes einschlagen.
Voyant kann mit Texten in unterschiedlichen Formaten wie XML, HTML, RDF, RTF, MS-Word-Dateien oder Reintexten (TXT) arbeiten. Für die Arbeit mit Voyant bietet sich dieses Textformat an, da wir ausschließlich den Reintext von Emila Galotti untersuchen möchten. Wählen Sie per Mausklick das Format „Text” aus und beginnen den Downloadprozess (siehe Abb. 4).

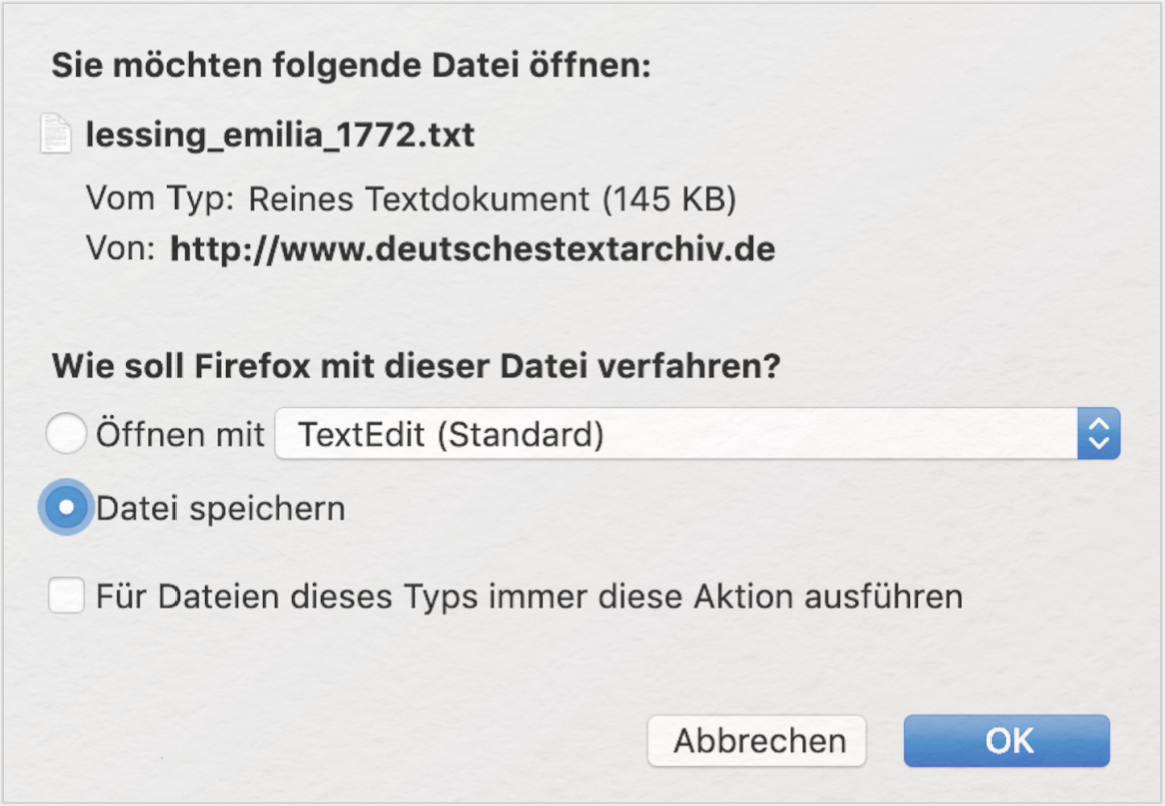
Klicken Sie auf den „Text”-Button und speichern Sie die Datei „lessing_emilia_1772.txt” z. B. auf Ihrem Desktop ab. Der Downloadprozess des Textes kann je nach Betriebssystem variieren. I. d. R. werden Sie dazu aufgefordert, den Text direkt zu öffnen und an einem beliebigen Ort auf Ihrem Rechner zu speichern (siehe Abb. 5).
Nun haben Sie die ersten Schritte auf dem Weg zur quantitativen digitalen Textanalyse von Emilia Galotti erfolgreich absolviert: Ihr Untersuchungsgegenstand liegt in einem mit Voyant kompatiblen Format auf Ihrem Desktop vor und ist bereit für die Implementierung in Voyant. Das Tool selbst verwenden wir in diesem Fall als webbasierte Variante.
Um Emilia Galotti bei Voyant hochzuladen, suchen Sie bitte die Startseite von Voyant auf, indem Sie hier klicken. Die sich nun öffnende Seite beinhaltet ein Eingabefeld. Um Texte hochzuladen, stehen Ihnen drei unterschiedliche Möglichkeiten zur Verfügung: Die direkte Eingabe in das zentrale Eingabefeld, das Öffnen bereits erstellter Textkorpora oder das Hochladen eigener Dokumente. Im Eingabefeld können Sie URLs eingeben (mehrere URLs werden pro Zeile eingegeben, durch ein „Enter” voneinander getrennt und per Klick auf den blauen „Reveal”-Button hochgeladen) oder Text per Copy & Paste (ebenfalls durch „Reveal” bestätigen) einfügen. Über den Open-Button lassen sich übrigens vorbereitete Textkorpora – bestehend aus acht Werken Jane Austens oder aus 27 Werken Shakespeares – hochladen und mit Voyant explorieren. Da Sie aber einen eigenen Text untersuchen möchten, muss der Text über den „Upload”-Button hochgeladen werden (siehe Abb. 6).


Hinweis: Bereits vor dem Hochladen Ihres Textes können Sie Voreinstellungen festlegen. Hierfür nutzen Sie die Menüleiste in der oberen rechten Ecke des Eingabefeldes (siehe Abb. 7).
Das Interface von Voyant ist auf Englisch voreingestellt, darüber hinaus aber über „Language Interface Options” in zehn weiteren Sprachen abrufbar. Sofern Sie ein größeres Textkorpus hochladen möchten, können Sie via „Options” bereits an dieser Stelle bestimmte Voreinstellungen vornehmen, die während des Hochladens auf das Textkorpus angewendet werden. Hier können Sie bspw. Titel für mehrere Dokumente in einem Korpus festlegen, ein Zugangspasswort zu einer Voyant-Session vergeben, festlegen, dass nur Teile einer HTML-Datei in die Voyant-Analyse einbezogen werden oder JSON-Dateien zu bearbeiten. Die meisten dieser Einstellungen richten sich an erfahrene Nutzer*innen und spielen bei dieser Lerneinheit keine Rolle. Tipp: Eine Beschreibung sämtlicher Tools finden Sie im Voyant-Guide. Hier werden alle Visualisierungsmöglichkeiten detailliert vorgestellt, häufig gestellte Fragen beantwortet und weitere hilfreiche Hinweise für die Arbeit mit Voyant bereitgestellt.
Das Hochladen eigener Texte erfolgt in drei Schritten. Klicken Sie im Eingabefeld zunächst den Upload-Button und navigieren Sie zu der auf Ihrem Desktop abgespeicherten Datei „lessing_emilia_1772.txt”. Diese laden Sie hoch, indem sie die Datei markieren und die Auswahl bestätigen, indem Sie den „Öffnen”-Button betätigen.
Nachdem Sie das Hochladen der Datei bestätigt haben, lädt Voyant den Text automatisch hoch, worüber das bewegte „Uploading-Corpus”– bzw. „Fetching your Corpus”– Symbol informiert.
Dieser Prozess kann je nach Größe der Datei einige Zeit in Anspruch nehmen, in diesem Fall sollte er aber in wenigen Sekunden abgeschlossen sein. In dieser Zeit wird der von Ihnen ausgewählte Text statistisch ausgewertet. Nach dem Upload-Prozess öffnet sich automatisch das Voyant-Interface (siehe Abb. 10).
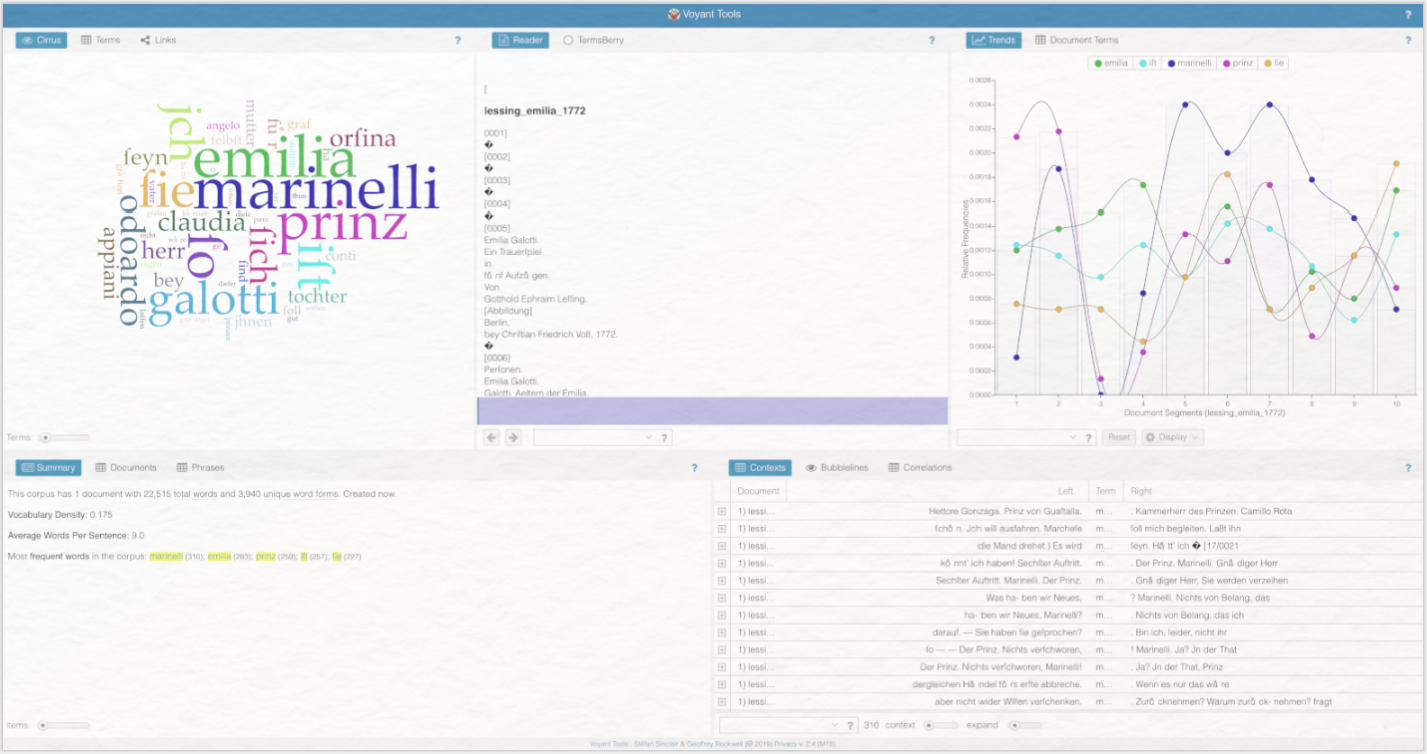
Nun öffnet sich die Benutzeroberfläche von Voyant. Nehmen Sie sich einen Augenblick Zeit und verschaffen sich einen ersten Überblick über die Benutzeroberfläche: Sie sehen unterschiedliche Visualisierungen der statistischen Auswertung von Emilia Galotti.
3. Funktionen
Im Rahmen dieser Lerneinheit werden Sie zunächst die voreingestellte Benutzeroberfläche von Voyant kennenlernen. Diese beinhaltet die fünf Tools Cirrus, Reader, Trends, Contexts und Summary. Jedes dieser Tools ist in einem Panel beheimatet. Die fünf voreingestellten Tools heben unterschiedliche Ergebnisse der Textanalyse auf ganz unterschiedliche Art und Weise hervor. Doch zunächst zu den Gemeinsamkeiten: Jedes Panel verfügt über eine Symbolleiste, über die z. B. Tooleinstellungen angepasst und die entworfenen Grafiken heruntergeladen werden können. Diese Leiste befindet sich stets in der oberen rechten Ecke eines jeden Panels. Die Symbolleiste erscheint erst, wenn Sie mit der Maus über den Bereich links neben dem in jedem Panel sichtbaren Fragezeichen-Symbols hovern. Die Exportfunktionen und die Möglichkeit, das ausgewählte Tool durch ein anderes zu ersetzen, besteht für jedes Panel. Die manuell anpassbaren Tooleinstellungen unterscheiden sich von Tool zu Tool bzw. sind nicht für jedes Tool vorhanden.
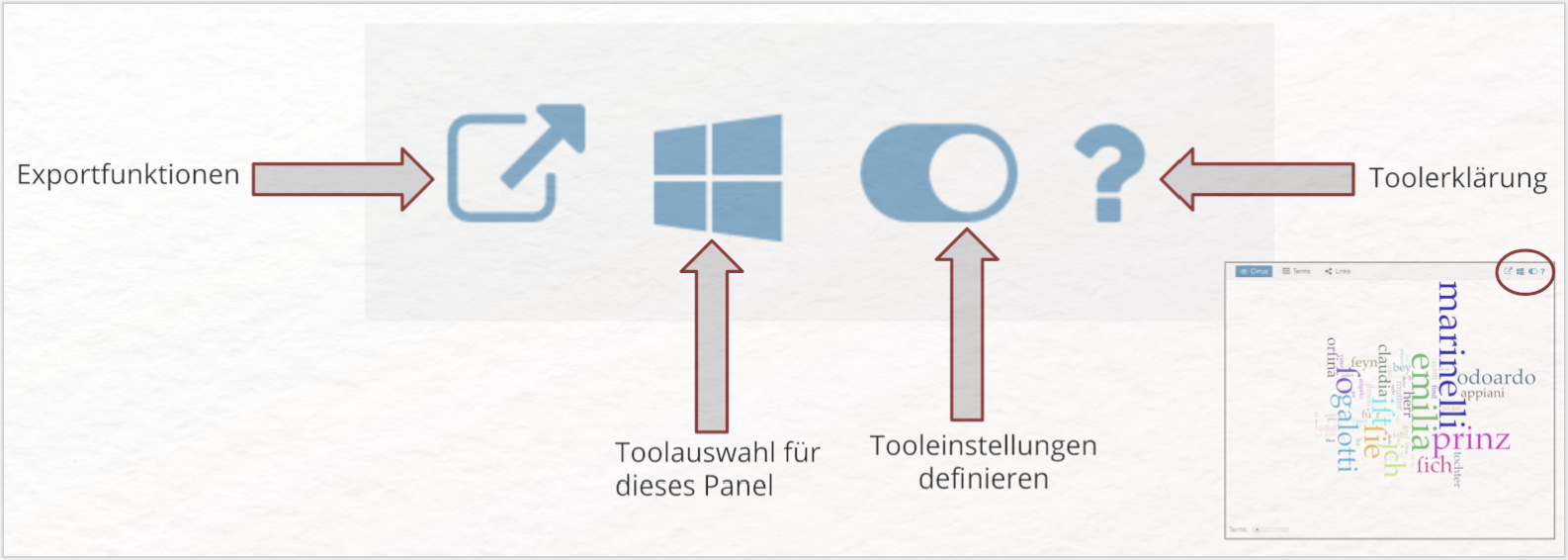
Zu einer wichtigen und manuell festlegbaren Tooleinstellung zählt v. a. das Generieren einer Stoppwortliste. Stoppwörter sind diejenigen Wörter, die in Ihrer Textanalyse unberücksichtigt bleiben sollen. Sämtliche durch Voyant automatisch durchgeführten Analyseschritte sollen folglich unter Ausschluss dieser Wörter durchgeführt werden. In den meisten Fällen handelt es sich dabei um Funktionswörter (Personalpronomen, Präpositionen, Konjunktionen, Interrogativpronomen, Possessivpronomen), die in Texten – grammatisch bedingt – besonders häufig vorkommen und dadurch den Blick auf die Inhaltswörter (Substantive, Verben, Adjektive) versperren. Da es in diesem Fall vor allem die Inhaltswörter sind, die dabei helfen, aus den Ergebnissen der quantitativen Textanalyse eine Interpretation abzuleiten, möchten wir möglichst viele Funktionswörter auf die Stoppwortliste setzen und diese dadurch aus den Visualisierungen herausrechnen lassen. Erkunden Sie hierzu zunächst die Symbolleiste der unterschiedlichen Tools. Über den „Define options for this tool”-Button gelangen Sie zu der Stoppwortliste.
Aufgabe 1
Für welche der fünf Tools lässt sich eine Stoppwortliste festlegen und für welche nicht? Welche Grundeinstellungen finden Sie hier vor?
Wie Sie wahrscheinlich festgestellt haben, muss nicht für jedes einzelne Tool eine Stoppwortliste erstellt werden. Durch das Häkchen vor „apply globally” wird die einmal entworfene Stoppwortliste automatisch in die Auswertung sämtlicher Tools einbezogen. Generell gilt: Die fünf Tools agieren miteinander. Voyant bietet für unterschiedliche Sprachen bereits definierte Stoppwortlisten an. Das ist hilfreich und zeitsparend, da sprachspezifische Funktionswörter bereits in einer Liste gesammelt wurden, die Sie nun per Mausklick von Ihrer Textanalyse ausschließen können. In den folgenden Schritten werden wir nun die deutschsprachige Stoppwortliste aktivieren. Klicken Sie zunächst in einem der drei möglichen Tools auf den „Define options for this tool”-Button. Nun öffnet sich ein Fenster, in dem Sie ihre Stoppwortliste bearbeiten können.
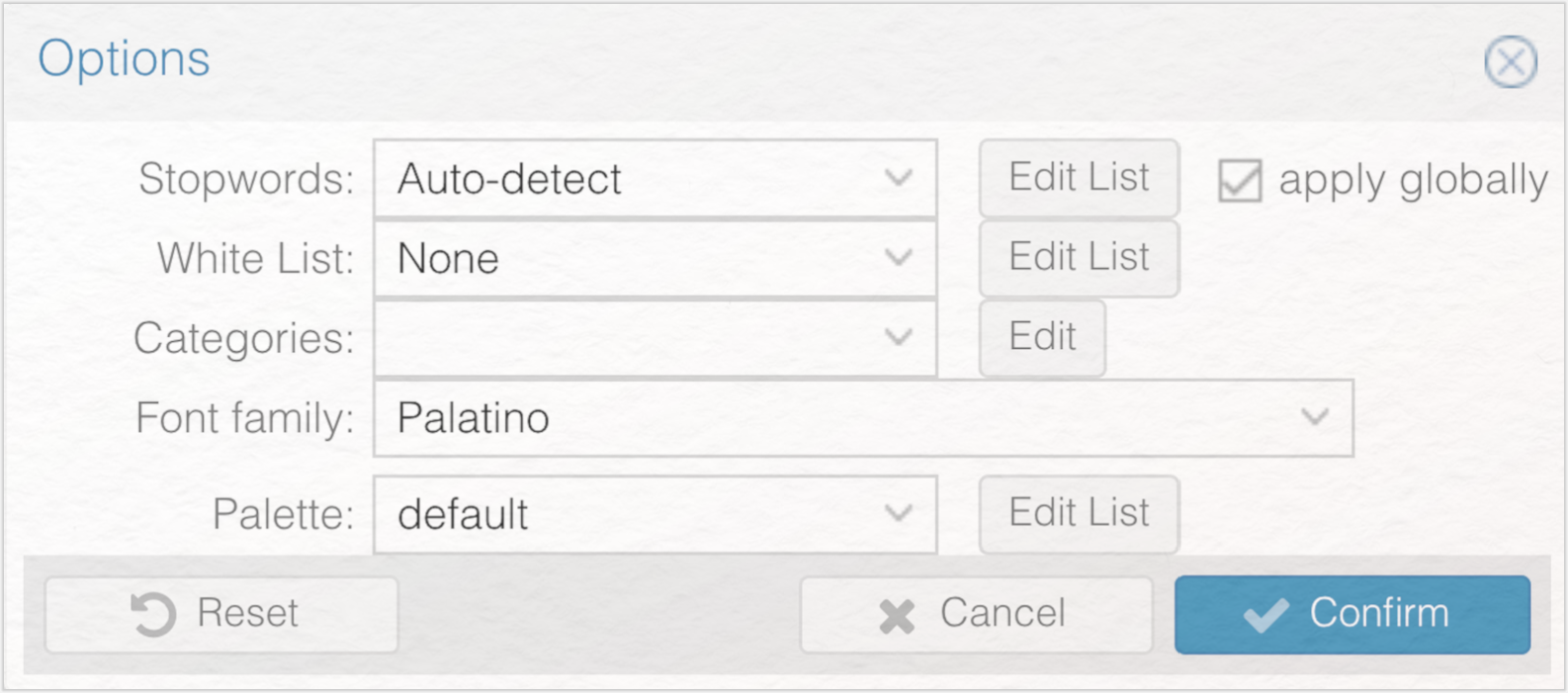
Das Erstellen einer guten Stoppwortliste stellt einen zentralen Arbeitsschritt der digitalen Textanalyse mit Voyant dar. Sobald Sie die Stoppwortliste aufgerufen haben, stehen unterschiedliche Möglichkeiten zur Verfügung, um die Liste auf Ihre Anliegen anzupassen. Unter „Stopwords” finden Sie eine Auswahl aus vordefinierten Stoppwortlisten. Unter „White List” können Sie Wörter festlegen, die in jedem Fall in die Analysen einbezogen werden sollen, während unter „Categories” gleiche Wörter in Kategorien zusammengefasst sind, die Sie im Ganzen auf die Stoppwortliste setzen können. Unter „Font family” können Sie die Schriftart und unter „Palette” die Farben der Visualisierungen festlegen. Wählen Sie hinter „Stopwords” nun „German” aus und bestätigen Sie diese Auswahl mit einem Klick auf den „Confirm”-Button. Damit haben Sie bereits einige für die Interpretation Ihrer Ergebnisse störende Funktionswörter ausgeschlossen. Doch welche sind das überhaupt und wie lassen sich weitere individuell ausgewählte Stoppwörter in die Liste aufnehmen? Um einsehen zu können, welche Wörter auf der Liste enthalten sind, gehen Sie erneut via „Define Options for this Tool” in das Menü, in dem Sie die Stoppwortliste bearbeiten können (siehe Abb. 12). Hinter der zuvor ausgewählten deutschsprachigen Stoppwortliste gelangen Sie per Klick auf den „Edit-List”-Button auf die detaillierte Ansicht der Stoppwortliste.

Nun können Sie zum einen sehen, welche Wörter bereits auf der Liste stehen und zum anderen manuell Wörter ergänzen, indem Sie diese am Ende der Liste eintippen. Pro Zeile, die durch das Betätigen der Enter-Taste voneinander getrennt werden, kann ein Wort eingegeben werden. Durch einen Klick auf den „Save”-Button bestätigen Sie die Aktualisierung Ihrer Stoppwortliste.
Aufgabe 2
Welche Wörter sollten auf einer „guten” Stoppwortliste stehen?
Nun haben Sie einen wichtigen Bestandteil von Voyant kennengelernt, der darüber hinaus in vielen Methoden der digitalen Textanalyse eine tragende Rolle spielt. Eine weitere Funktion, die sämtlich Panels gemeinsam haben, ist die Exportfunktion. Grundsätzlich bestehen zwei Exportmöglichkeiten: Sie können entweder die einzelne Visualisierung eines Panels oder die gesamte Voyant-Sitzung exportieren. Einzelne Abbildungen lassen sich als SVG- oder PNG-Datei exportieren. In diesem Fall exportieren Sie quasi eine Momentaufnahme Ihres Analyseprozesses. Darüber hinaus besteht die Möglichkeit, die Visualisierung als URL zu exportieren und sich eine Zitierhilfe anzeigen zu lassen. Wählen Sie die URL-Exportmöglichkeit, exportieren Sie die dynamische Visualisierung in Form der URL, die zu Ihrer Visualisierung zurückführt. Die gesamte Voyant-Sitzung lässt sich nur als URL exportieren und bleibt damit – genau wie der Export der dynamischen Visualisierung – webbasiert. Der Export der Bilddatei ist vor allem dann sinnvoll, wenn sie die Visualisierungen bspw. in eine Printpublikation einbinden möchten.
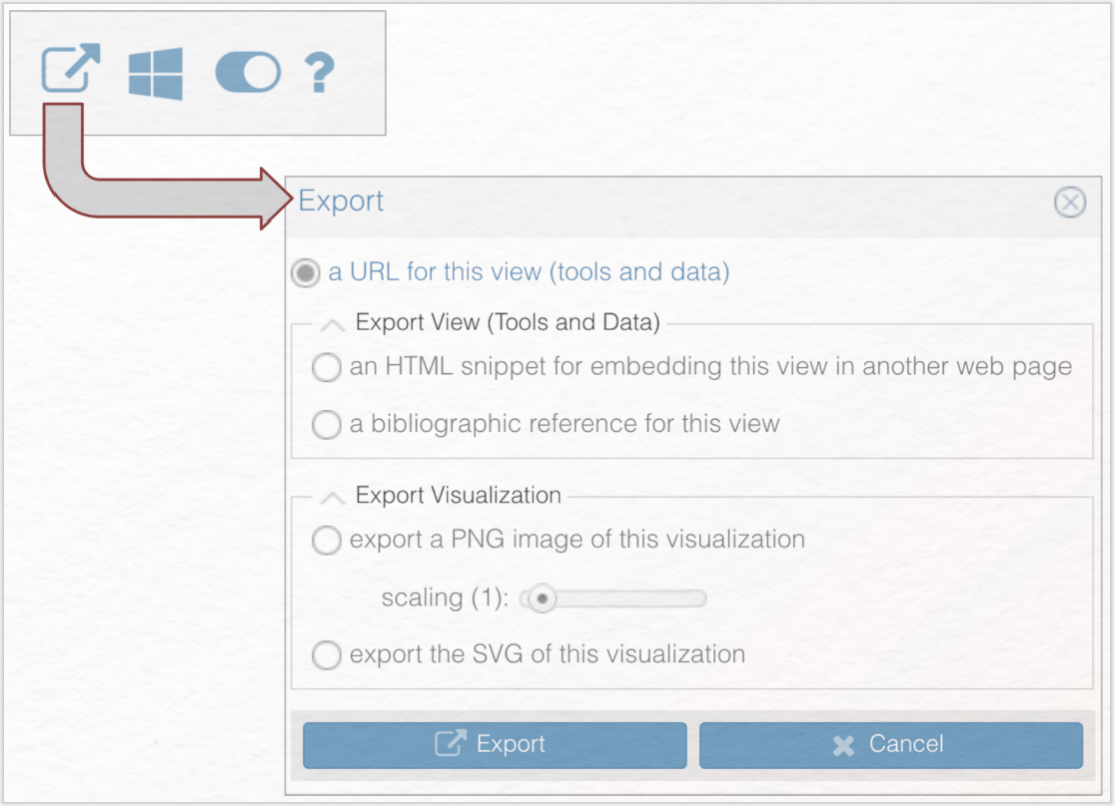
Nun haben Sie elementare Voyant-Bestandteile kennengelernt, die jegliche Arbeit mit Voyant begleiten werden: Die Stoppwortliste, die Funktionen der Menüleiste der einzelnen Panels und die unterschiedlichen Exportfunktionen. Jetzt wenden wir uns den einzelnen Tools und den hier dargestellten Formen der Textvisualisierungen zu. In den unterschiedlichen Panels werden die Ergebnisse der statistischen Auswertung von Emilia Galotti unterschiedlich dargestellt. Doch welches Panel verbildlicht welche Textdaten und welche Interpretation lässt sich daraus ableiten? Um die schrittweise erfolgende Beantwortung dieser Fragen wird es in dem folgenden Teil der Lerneinheit gehen.
Kernelement der digitalen Textanalyse mit Voyant sind die Auswertung und Interpretation der erhobenen Daten und deren Visualisierung.
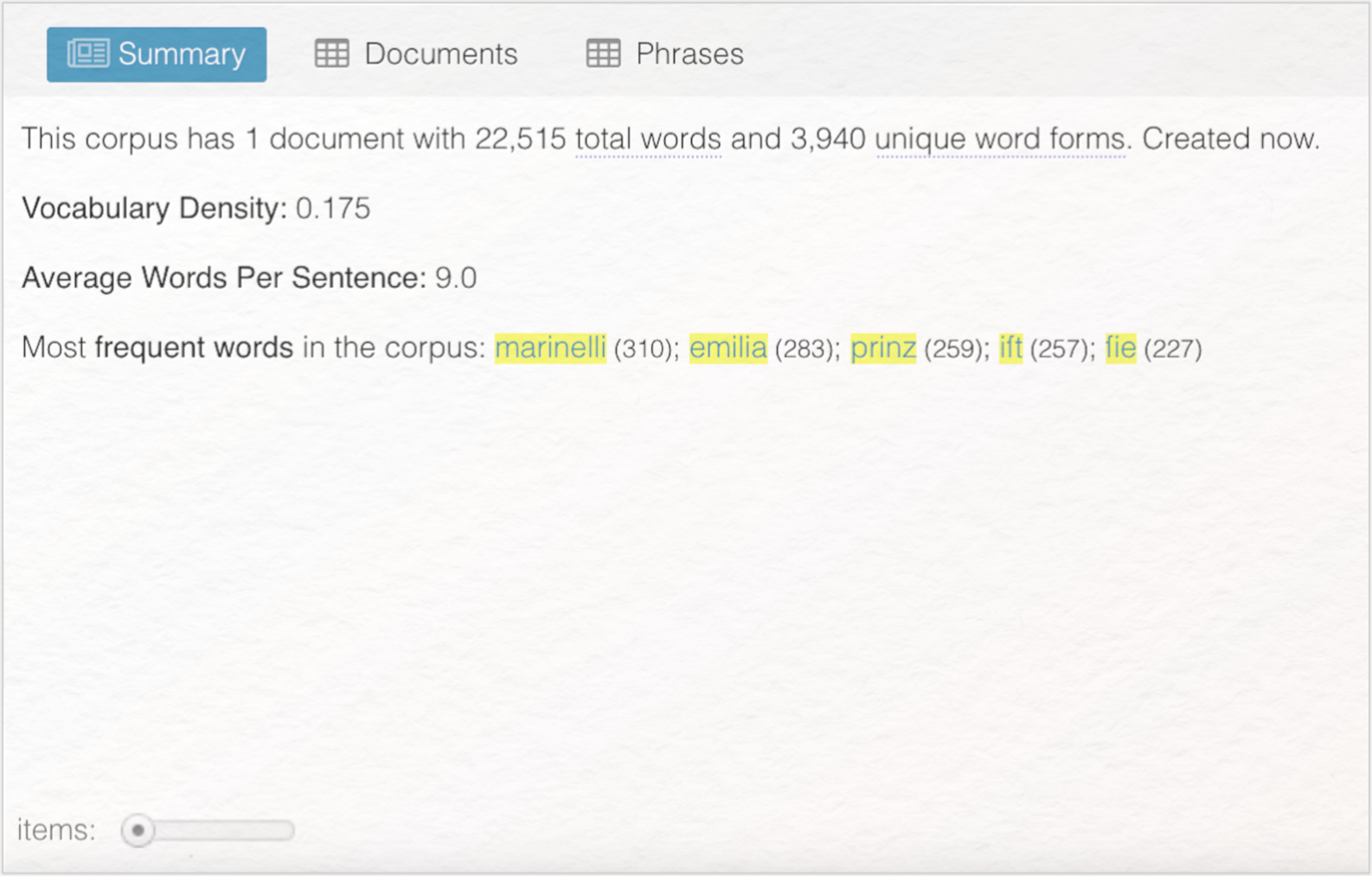
Summary listet die wichtigsten Ergebnisse der quantitativen Textanalyse auf und hat vor allem eine informierende Funktion. Angezeigt wird die gesamte Wortzahl, die Wortdichte (Relation von Type und Token bzw. Wortschatz: je näher die Token- der Typezahl, desto größer der jeweilige Wortschatz), die durchschnittliche Anzahl von Wörtern pro Satz sowie die am häufigsten vorkommenden Wörter (most frequent words, MFW). Durch einen Blick auf Summary entsteht ein erstes Gefühl für die quantitative Beschaffenheit der Textgrundlage: Hier finden Sie die konkreten Zahlen, auf denen z. B. die Wortwolke basiert. Summary ist vor allem dann hilfreich, wenn Sie mit einem aus mehreren Texten bestehenden Textkorpus arbeiten. In diesem Fall werden für jedes Textdokument die Ergebnisse der quantitativen Auswertung aufgelistet. Anhand der Ergebnisse über Wortvorkommen, Textlänge etc. lassen sich die Texte rein quantitativ miteinander vergleichen.
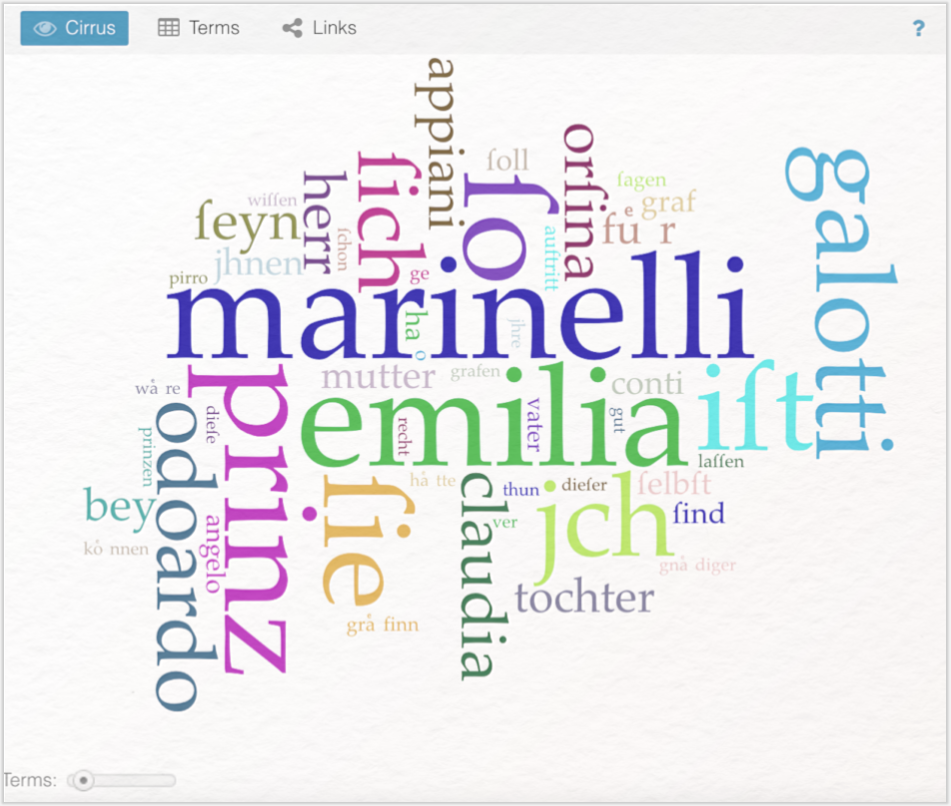
In Cirrus wird eine Wortwolke dargestellt. Hier werden Wörter der Häufigkeit ihres Vorkommens entsprechend visualisiert. Häufig vorkommende Wörter werde größer dargestellt als selten vorkommende Wörter.
Aufgabe 3
Werten Sie die Wortwolke aus: Welche Wörter kommen besonders häufig, welche weniger häufig vor? Leiten Sie basierend auf den Worthäufigkeiten eine erste Interpretationshypothese ab, indem Sie Vermutungen über Inhalte, Handlungen, Figuren, Orte oder epochencharakteristische Merkmale anstellen. Spielen Farbe und die topografische Anordnung der Wörter eine Rolle und wenn ja, welche? Exportieren Sie Ihre Grafik als PNG-Dokument.

Der Reader bildet den gesamten hochgeladenen Text ab. Wenn Sie in diesem Panel mit der Maus über einzelne Wörter hovern, wird Ihnen die Vorkommenshäufigkeit dieses Wortes angezeigt. Über eine unter dem Text platzierte Suchleiste können Sie nach jedem beliebigen Wort innerhalb des Texts suchen. Das Ergebnis wird im Text gelb markiert.
Aufgabe 4
Welche Wörter, die mit dem Wort „schuld” verwandt sind, kommen in Emilia Galotti vor?
Wie bereits erwähnt, sind die einzelnen Tools in Voyant miteinander vernetzt: Das gilt auch für die Tools Reader, Trends und Contexts.
Aufgabe 5
Klicken Sie im Reader auf „Marinelli”. Wie reagieren die Einstellungen der anderen Tools darauf?
Trends visualisiert das Vorkommen der fünf am häufigsten im gesamten Text/Textkorpus vorkommenden Wörter. Eine Legende am oberen Rand des Graphen teilt jedem Wort eine Farbe zu. Da sie vorher im Reader „Marinelli” ausgewählt haben, müssen Sie Trends zunächst in seine Grundeinstellung zurückversetzen, um nicht mehr ausschließlich Marinellis Verlaufskurve, sondern diejenige sämtlicher MFWs angezeigt zu bekommen. Hierfür wird die „Reset”-Funktion verwendet, die fester Bestandteil eines jeden Panels ist und manuell vorgenommene Tooleinstellungen deaktiviert.
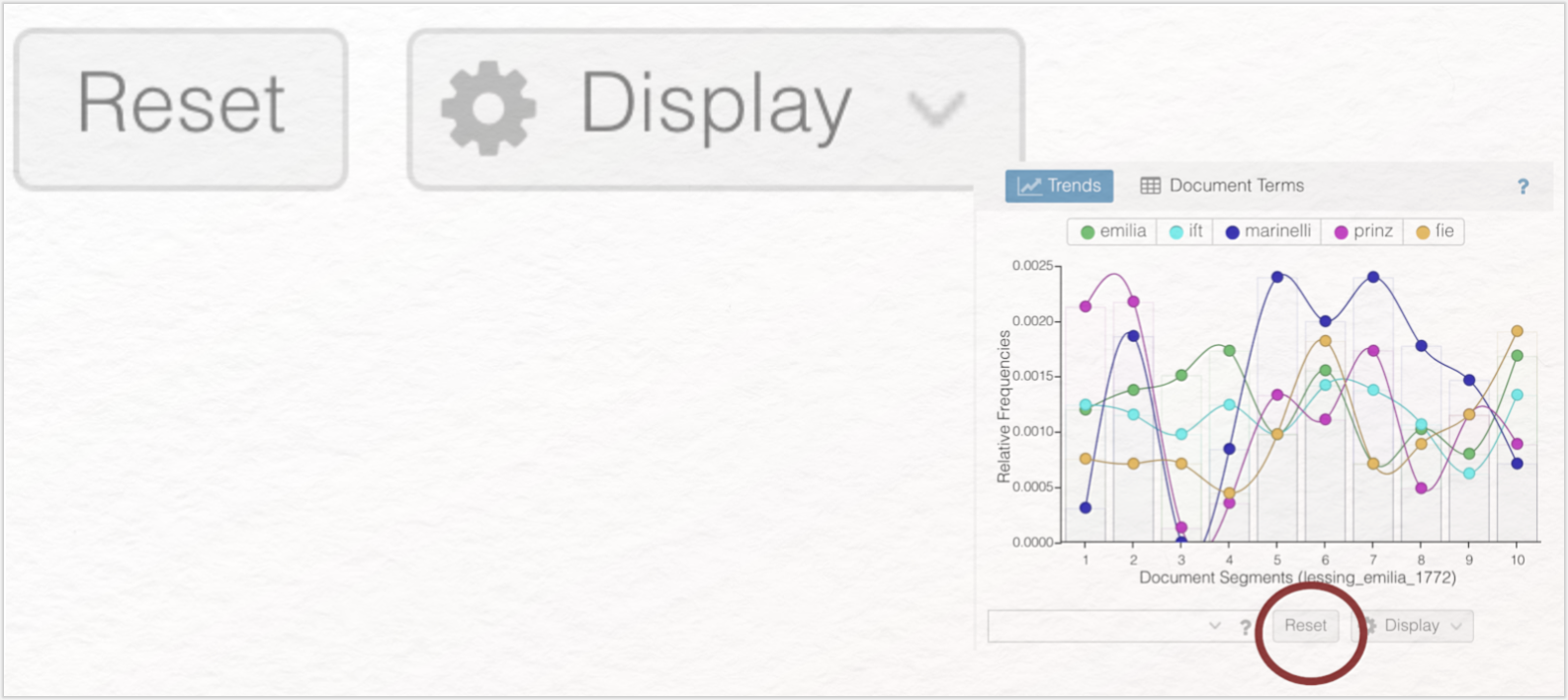
Klicken Sie nun auf die „Reset”-Taste und setzen das Tool in seine Grundeinstellung zurück. Wenn Sie auf ein Wort in der Legende klicken, wird es im Graphen nicht mehr angezeigt. Voyant teilt den gesamten Text in Trends automatisch in gleichgroße Segmente auf. Diese werden im Graphen als farbige Säulen dargestellt. Für jedes Segment wird angegeben, wie häufig jedes der fünf Wörter innerhalb dieses Textsegments vorkommt. Wenn Sie über die Knotenpunkte hovern, werden Ihnen Informationen zu dem jeweiligen Wort (Wort, Häufigkeit, Titel des Textes, Segmentnummer) dargeboten. Sobald Sie auf den Knotenpunkt klicken, wird eine Vernetzung zu zwei weiteren Tools hergestellt: Contexts und Reader. Im Reader wird das angeklickte Wort innerhalb des gesamten Textes gelb markiert (siehe Abb. 17). Unter Contexts (s. u.) werden Ihnen Textstellen angezeigt, die vor und nach dem angeklickten Wort auftauchen.
Aufgabe 6
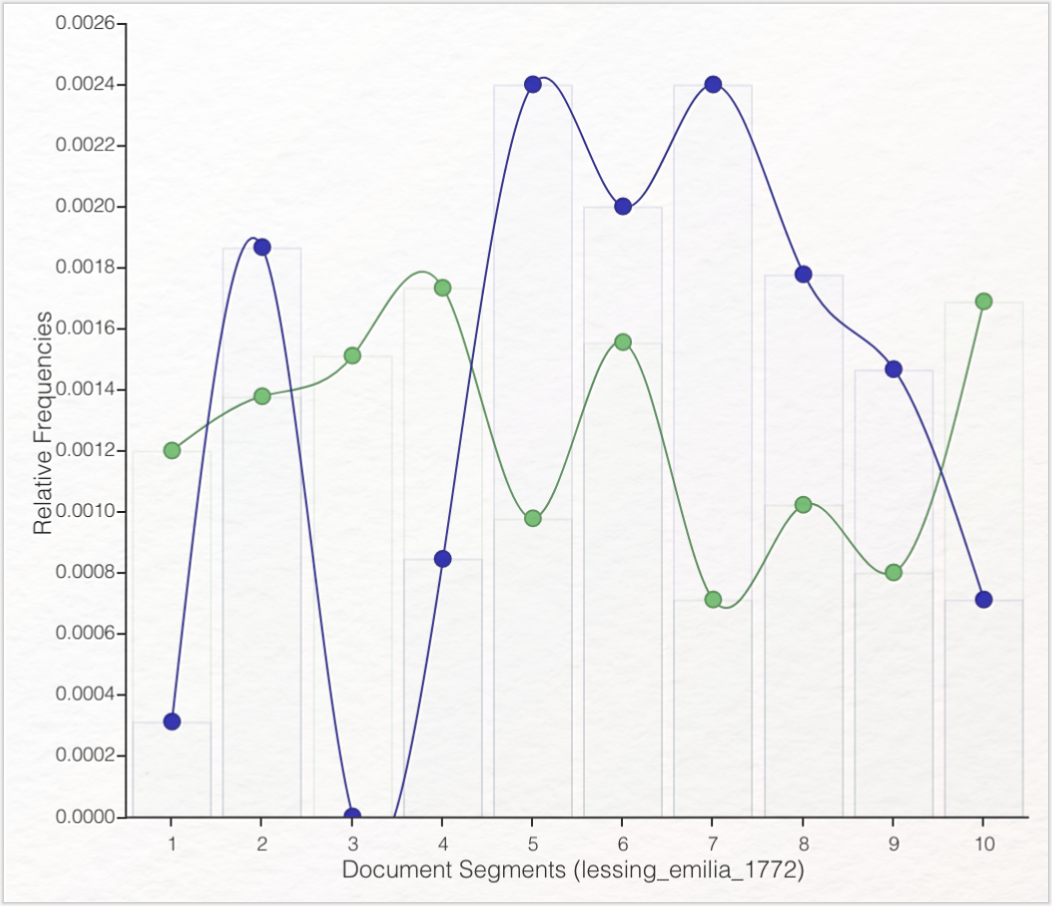
Erstellen Sie einen Graphen, in dem nur die beiden häufigsten Wörter vorkommen und exportieren diese Grafik. In welchen beiden Segmenten kommen diese Wörter am häufigsten vor und in welchen Segmenten kommen beide Wörter zusammen vor? Welche Rückschlüsse lassen sich hieraus auf die Figurenkonstellation des Stücks ziehen?
Tipp: Nutzen Sie den „Display”-Button rechts neben der „Reset”-Funktion, um die aktuelle Verlaufskurve durch einen anderen Graphentypen zu ersetzen.
Contexts zeigt Ihnen die direkte Umgebung eines ausgewählten Wortes an und steht in Verbindung mit den Tools Trends und Reader. Contexts ermöglicht also – genau wie Reader –, aus der statistischen Erhebung heraus wieder in den Text zurückzukehren und sich das Umfeld eines ausgewählten Wortes – die sog. Keywords in Context – genauer anzuschauen.
Nun haben Sie die fünf klassischen und zum Teil miteinander vernetzten Voyant-Tools kennengelernt. Während Reader und Contexts eher als Close Reading-Tools bezeichnet werden können, haben Sie mit Cirrus, Trends und Summary drei Tools der quantitativen Textanalyse kennengelernt. Darüber hinaus haben Sie einige der Grafiken interpretiert und damit den Brückenschlag zwischen statistischer Auswertung von Texten und literaturwissenschaftlicher Interpretation gemacht. Die Grundlage Ihrer Interpretation – die Visualisierungen – haben Sie exportiert.
Neben der Arbeit mit den fünf voreingestellten Tools besteht in jedem Panel die Möglichkeit, das voreingestellte Tool durch ein anderes Werkzeug aus dem Voyant-Toolkit zu ersetzen. Anders als die standardmäßig aktivierten Tools sind die inaktiven Tools nicht blau hinterlegt. Im Cirrus-Panel können Sie per Mausklick auf die Tools Terms oder Links umschalten, während Reader sich durch TermsBerry ersetzen lässt. Trends können Sie mit Document Terms auswechseln, Contexts mit Bubblelines oder Correlations austauschen. Summary kann per Mausklick auf das Tools Documents oder Phrases umgeschaltet werden.

Nehmen Sie sich etwas Zeit, um die unterschiedlichen Tools auszuprobieren. Keine Angst: Sie können ohne Bedenken zwischen unterschiedlichen Tools hin- und herspringen. TermsBerry visualisiert durch farbliche Kennzeichnungen, im Zusammenhang mit welchen anderen Wörtern die MFWs besonders häufig vorkommen.
Aufgabe 7
Ersetzen Sie Reader durch TermsBerry. In Verbindung mit welchen vier Wörtern kommt „marinelli” am häufigsten vor und wie verhält es sich mit „emilia”? Welche Rückschlüsse lassen sich hieraus ziehen?
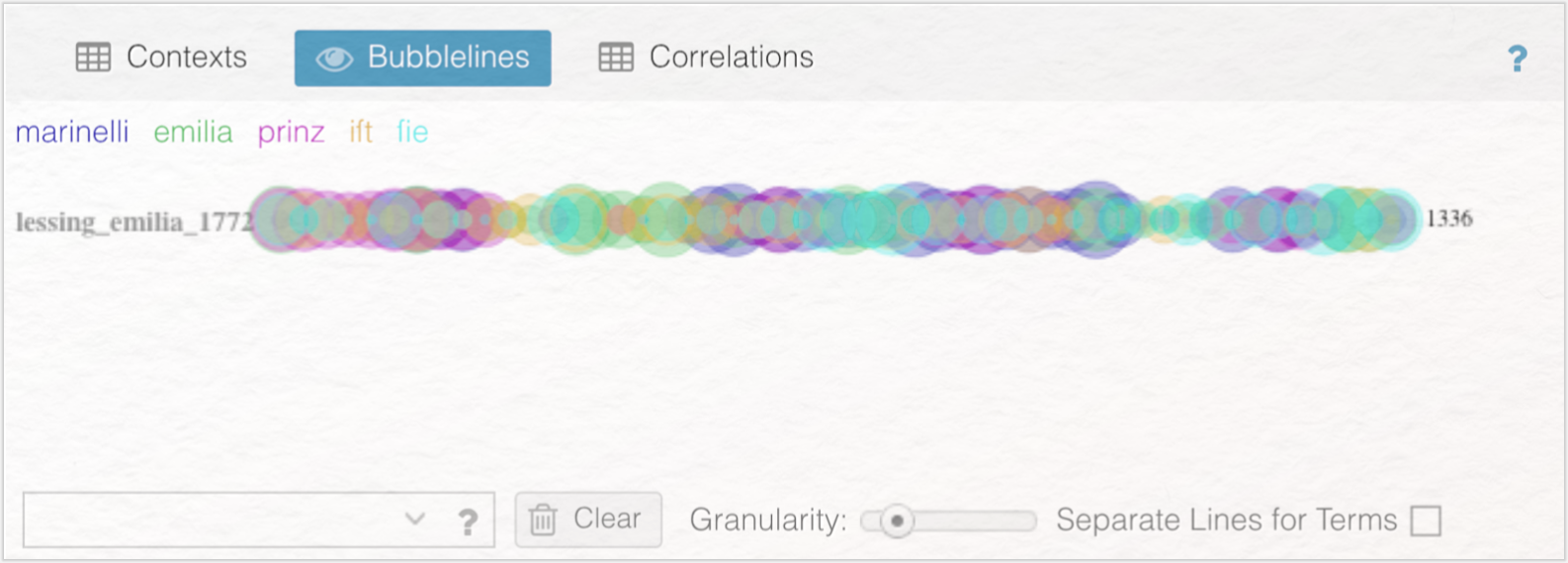
Bei dem Tool Bubblelines, welches in dem Contexts-Panel ausgewählt werden kann, repräsentiert die horizontale Linie das Textdokument. Diese Linie, d. h. das Textdokument, ist in gleich lange Segmente unterteilt (Grundeinstellung: 50 Segmente, auch dies lässt sich in den Tooleinstellungen verändern). Jedes von Ihnen ausgewählte Wort wird als kreisförmige Blase (eben als Bubble) angezeigt. Die Größe der Blase zeigt die Häufigkeit, in der dieses Wort innerhalb des Segments vorkommt: Je größer die Blase, desto häufiger kommt das Wort in dem jeweiligen Textsegment vor. Wenn Sie Bubblelines auswählen, werden zunächst sämtliche MFWs in einer Linie angezeigt. Das Durcheinander von bunten Bubbles kann schnell etwas unübersichtlich anmuten. Um einzelne Wörter aus der Bubbleline zu entfernen, klicken Sie einfach auf das entsprechende Wort oberhalb der Bubbleline und blenden es per „Hide Term” aus oder entfernen es endgültig via „Remove Term”. Durch die Interdependenz der Panels kann es sein, dass in Ihrer Bubbleline zunächst nur ein bestimmtes Wort angezeigt wird. Sollten Sie in anderen Panels ein bestimmtes Wort angeklickt haben, wird Ihnen bspw. nur die Bubbleline dieses Wortes angezeigt. Um sämtliche MFWs zu integrieren, nutzen Sie das Eingabefeld in der unteren linken Ecke des Panels (siehe Abb. 22). Begriffe können über die Suchbox hinzugefügt werden, indem Sie den Suchbegriff eingeben und mit „Enter” bestätigen.
Aufgabe 8
Ersetzen Sie Contexts durch Bubblelines und integrieren Sie die fünf MFWs in Ihre Bubbleline. Klicken Sie auf „Seperate Lines from Terms”, um sich pro Segment nur das Vorkommen eines der MFWs anzeigen zu lassen. Blenden die Wörter „ist” und „sie” aus. Exportieren Sie auch diese Grafik. Was bildet dieses Tool ab und wie lassen sich die Ergebnisse interpretieren?
Wie anfangs erwähnt, handelt es sich bei Voyant um den Zusammenschluss von mittlerweile 29 unterschiedlichen Tools, die jeweils unterschiedliche Formen der Textvisualisierung ermöglichen. In den vorangegangenen Schritten haben Sie unterschiedliche interne Tools angewendet. Sie sind Bestandteil der standardmäßig festgelegten Benutzeroberfläche. Den Einbezug eines weder in den Voreinstellungen noch in der Menüleiste der Panels enthaltenen Tools – d. h. eines externen Voyant–Tools – setzen Sie in wenigen Schritten in die Tat um: Klicken Sie in der Menüleiste des gewünschten Panels auf „Click to choose another tool for this panel location”. Nun können Sie ein beliebiges Tool für das jeweilige Panel auswählen.
Auf diese Weise können Sie sich eine individuelle Toollandschaft erstellen. Die 29 unterschiedlichen Tools lassen sich in unterschiedliche Kategorien einteilen. Einige eignen sich besonders gut, um einzelne Dokumente zu untersuchen, so wie Sie es in dieser Lerneinheit gemacht haben. Andere sind dafür prädestiniert, ein aus mehreren Texten bestehendes Textkorpus zu analysieren, so wie das vorbereitete Shakespeare- oder Austen-Textkorpus. Wieder andere Tools erstellen ausschließlich Rastergrafiken. An den folgenden Symbolen erkennen Sie die Kategorien.

Corpus Tools: Tools, die sich für die Analyse eines Textkorpus eignen: Cirrus, Terms, Bubblelines, Correlation, Collocates, DreamScape, DreamScape, Loom, Mandala, MicroSearch, StreamGraph, Phrases, Documents, Summary, Trends, ScatterPlot, TermsRadio, Topics, Veliza, WordTree.

Document Tools: Tools, die sich für die Analyse einzelner Dokumente eignen: Bubbles, Cirrus, Document Terms, Reader, TextualArc, Trends, Knots, Topics.

Visualizationtools: Cirrus, Bubbles, Bubblelines, Links, DreamScape, Loom, Knots, Mandala, MicroSearch, StreamGraph, ScatterPlot, TextualArc, Trends, Termsberry, TermsRadio, WordTree.

Grid Tools: Tools, die Rastergrafiken/Tabellen erstellen: Terms, Collocate, Correlations, Phrases, Contexts, Document Terms, Documents, Topics.
Aufgabe 9
Erstellen Sie eine Toollandschaft, die aus jeder der vier Hauptkategorien mindestens ein Tool enthält und exportieren Sie diese Voyant-Sitzung als URL.
Es ist ratsam, sich vorab im Voyant-Guide über die Funktionen der unterschiedlichen Tools zu informieren, damit Sie an dieser Stelle bewusst eine bestimmte Visualisierung auswählen können, deren Ergebnisse Sie interpretieren können. Ohne Kenntnis über die Konzeption und Funktion der unterschiedlichen Visualisierungen kann deren Auswertung und Interpretation kaum gelingen.
Nun sind Sie am Ende der Lerneinheit angelangt und haben wichtige Schritte der digitalen Textanalyse mit Voyant ausprobiert: Korpuserstellung, Hochladen der Daten, Erstellen einer Stoppwortliste, Analyse und Interpretation der Visualisierungen (Cirrus, Trends, Contexts, Summary, Bubblelines, Reader, TermsBerry) und Export der Visualisierungen. Ihre Interpretationsansätze beruhen auf der statistischen Auswertung von Emilia Galotti, dem Sie sich mit Distant-Reading-Verfahren angenähert haben. Um Ihre Hypothesen zu überprüfen, empfiehlt sich spätestens jetzt die Methode des Close Reading: Kommt die Titelfigur wirklich weniger häufig vor als Marinelli? In welchem Verhältnis stehen die most frequent words „marinelli”, „prinz” und „emilia” zueinander? Adel vs. Bürgertum: Trifft diese Konstellation zu und wie wirken Gefühlswörter wie „herz”, „hand” oder „auge” auf Sie?
4. Lösungen zu den Beispielaufgaben
Aufgabe 1
Für welche der fünf Tools lässt sich eine Stoppwortliste festlegen und für welche nicht? Welche Grundeinstellungen finden Sie hier vor?
Eine Stoppwortliste lässt sich über die Symbolleiste der Tools Cirrus, Trends und Summary erstellen. Über die Tools Reader und Contexts kann keine Stoppwortliste erstellt werden. Die Voreinstellungen hinter „Stopwords“ sind auf „Auto-detect“ eingestellt. Bestimmte Stoppwörter werden also automatisch bereits erfasst und in den Visualisierungen nicht abgebildet. Das angekreuzte „apply globally“ verweist darauf, dass eine Stoppwortliste für sämtliche Tools gilt – unabhängig davon, über welches der drei Tools die Stoppwortliste bearbeitet wird.
Aufgabe 2
Welche Wörter sollten auf einer „guten” Stoppwortliste stehen?
Die ersten drei Wörter der deutschsprachigen Stoppwortliste lauten „ab”, „aber” und „abgerufen”. Dabei handelt es sich um Funktionswörter, die für eine Interpretation oder Analyse des Textes nicht essentiell sind und deshalb auch in der Visualisierung nicht zwingend abgebildet werden müssen. Das Erstellen einer fundierten und gut durchdachten Stoppwortliste stellt einen wichtigen vorbereitenden Schritt der digitalen Textanalyse dar, weil sie sich in den generierten Visualisierungen niederschlägt, die in der digitalen Textanalyse häufig die Grundlage der Interpretation darstellen. Auf einer „guten” Stoppwortliste stehen folglich die Wörter, die keine tragende Rolle bei der Textinterpretation spielen und die Sie auch in einer völlig analog durchgeführten Textanalyse nicht berücksichtigen würden. Wörter wie „zu”, “ „in”, „aber”, „ab”, „welcher”, „welchem” oder „welche” können relativ bedenkenlos auf die Liste gesetzt werden und stehen berechtigterweise auch bei Voyant auf der umfangreichen deutschsprachigen Stoppwortliste. Dennoch gilt grundlegend: Die Stoppwortliste stellt einen Filter dar, der die Ergebnisse der digitalen Textanalyse beeinflusst. Transparenz und Nachvollziehbarkeit sind auch hier zu berücksichtigen.
Aufgabe 3
Werten Sie die Wortwolke aus: Welche Wörter kommen besonders häufig vor und welche Wörter kommen weniger oft vor? Leiten Sie basierend auf den Worthäufigkeiten eine erste Interpretationshypothese ab, indem Sie Vermutungen über den Inhalt, Handlungen, Figuren, Orte oder epochencharakteristische Merkmale anstellen. Spielen Farbe und die topographische Ausrichtung der Wörter eine Rolle und wenn ja, welche?

In der Wordcloud sind die Wörter „marinelli” (325), „prinz” (259), „emilia” (131), „odoardo” (120), „claudia” (92), „orsina” (85) und „appiani” (74) besonders zentral und groß abgebildet. Die Visualisierung liefert einen Überblick über die handelnden Personen, die im Mittelpunkt der Handlung stehen. Die titelgebende Figur „emilia” ist in der Wortwolke allerdings kleiner abgebildet als „marinelli” oder „prinz”. Schließt man von der Worthäufigkeit auf die Zentralität der in dem Stück beteiligten Figuren – also auf die Hauptfigur – müssten „marinelli” oder der „prinz” die Hauptfiguren sein. Der Schluss von der Worthäufigkeit auf die Zentralität einer Figur bzw. auf die Hauptfigur stellt dabei nur eine Möglichkeit von vielen dar, um Zentralität zu definieren und lädt angesichts des Titels dazu ein, die Figurenkonstellation genauer zu untersuchen. Die ebenfalls in der Wortwolke abgebildeten Interjektionen „o” und „ah” verweisen auf eine ausdrucks- und gefühlsbetonte Sprache. „grafen” (51), „gräfin” (43) und „gnädiger” (31) zeigen, dass der untersuchte Text die Rolle des Adels thematisiert und einige der handelnden Figuren dem Adel zugerechnet werden können. Dem adeligen Setting und einer möglichen politischen Dimension kann ein familiäres, bürgerliches Setting gegenübergestellt werden. Die „tochter”- (72), „mutter”- (61), „vater”- (47) Konstellation wird in der Wortwolke deutlich abgebildet und verweist auf eine bürgerliche Opposition. Zentrale Themenkomplexe des Textes könnten die Themenfelder Recht („recht”: 35), Tod („tot”: 22), Wahrheit („wahr”: 20), Leben („leben”: 15) und Ehre („ehre”: 14) berühren. Die Lexeme „herz” (14) „hand” (25) und „augen” (25) werden zwar nicht primär dem Emotionswortschatz zugeordnet, gelten jedoch als bildlicher Ausdruck für Emotionen. Sie werden als Signalwörter behandelt, die inhaltlich über ein besonders hohes Assoziationspotenzial verfügen, um Gefühle darzustellen. Hinter diesen Gefühlswörtern verbergen sich häufig Konzeptualisierungsstrukturen von emotionalem Erleben. Sie werden – z. B. in Literaturkritiken – eingesetzt, um ein intrasubjektives Erleben zu gestalten. Die Lexeme ermöglichen der Leserschaft also ein Sich-Einfühlen in die erzählte Welt. Werden diese Wörter besonders häufig verwendet, könnte man dem Autor eine „Sinngebung der Empfindung durch Ritualisierung” (vgl. Stoeva-Holm 2015, 37f.) unterstellen. Eine mögliche Hypothese könnte es also sein, dass in dem untersuchten Text Gefühlswörter eingesetzt wurden, um auf die Leserschaft einzuwirken und sie emotional zu involvieren. Weder die Ausrichtung der Wörter in der Wortwolke noch die Farbgebung haben eine semantische Bedeutung. Ob die Wörter horizontal oder vertikal ausgerichtet sind oder welche Position innerhalb der Visualisierung sie einnehmen, spielt keine Rolle.
Aufgabe 4
Welche Wörter, die mit dem Wort „schuld” verwandt sind, kommen in Emilia Galotti vor?
Die Wörter „schuld” (5), „schuldigkeit” (4) und „schulden” (1) kommen in Lessings Trauerspiel wortwörtlich vor. Es handelt sich aber um eher selten vorkommende Wörter.
Aufgabe 5
Klicken Sie im Reader auf „Marinelli”. Wie reagieren die Einstellungen der anderen Tools darauf?
Wenn Sie im Reader auf „Marinelli” klicken, wird der Name im gesamten im Reader abgebildeten Text gelb markiert. Trends generiert eine Einzelansicht der Wortverteilung im gesamten Text. Im dritten Segment kommt „marinelli” am wenigsten vor.
Aufgabe 6
Erstellen Sie einen Graphen, in dem nur die beiden häufigsten Wörter vorkommen und exportieren diese Grafik. In welchen beiden Segmenten kommen diese Wörter am häufigsten vor und in welchen Segmenten kommen beide Wörter zusammen vor? Welche Rückschlüsse lassen sich hieraus auf die Figurenkonstellation des Stücks ziehen?hieraus auf die Figurenkonstellation des Stücks ziehen?
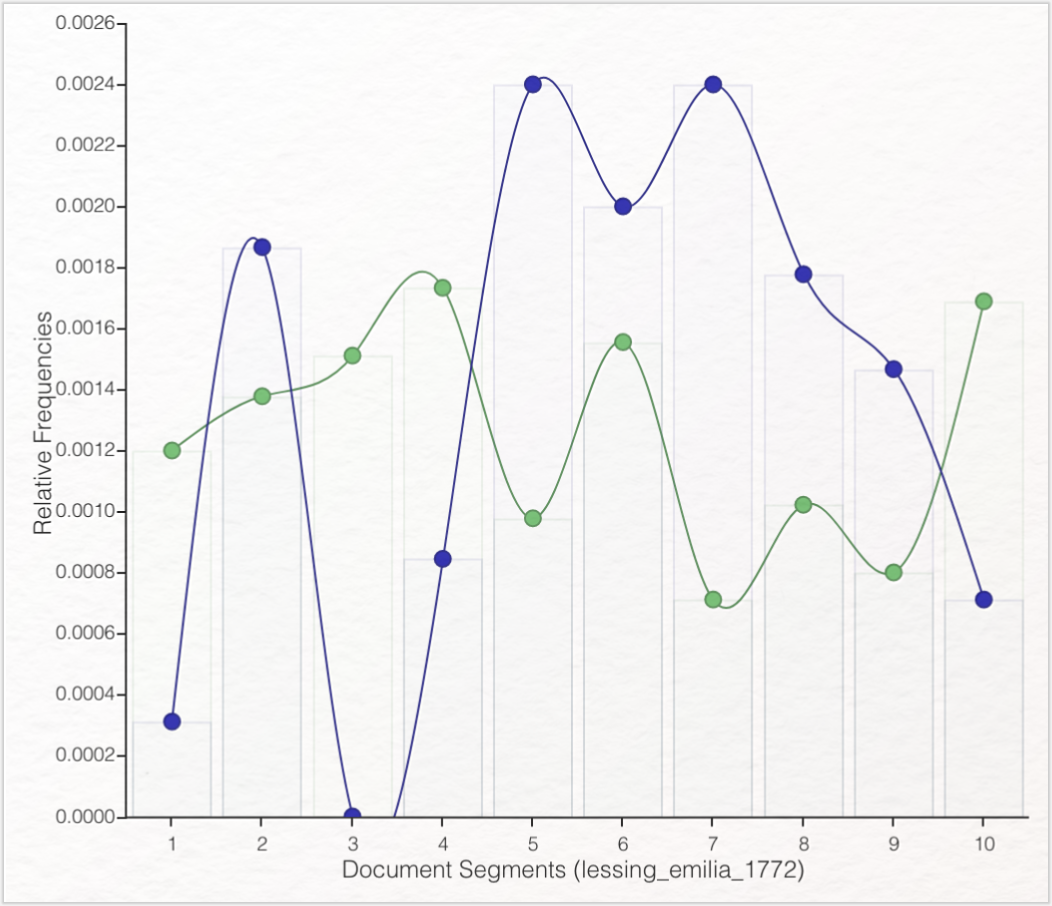
Um in Trends wieder alle MFWs anzeigen zu lassen (nicht mehr nur „marinelli”), müssen Sie den Graphen zunächst per Klick auf den „Reset”-Button in die Grundeinstellung zurückversetzen. Nun können Sie „claudia”, „odoardo” und „prinz” aus dem Graphen entfernen, indem Sie diese Wörter anklicken. Bei „marinelli” und „emilia” handelt es sich um die most frequent words. „marinelli” kommt in den Segmenten fünf und sieben am häufigsten vor, während „emilia” in den Segmenten vier und zehn am häufigsten genannt wird. Die Verlaufskurve beider Wortvorkommen verdeutlicht, dass die titelgebende „emilia” deutlich weniger häufig vorkommt, als „marinelli”. Die bei der Auswertung der Wordcloud aufgestellte Annahme verhärtet sich: Die Titelfigur ist hier nicht mit der Hauptfigur gleichzusetzen. Schließt man von der Häufigkeit des Vorkommens eines Wortes im gesamten Text auf den Rang einer Figur, kann in diesem Fall Marinelli als Hauptfigur bestimmt werden. Die Beantwortung der Frage, warum die weibliche titelgebende Figur nicht die Hauptfigur des Stücks ist, könnte den Ausgangspunkt für eine tiefergehende genderspezifische Erforschung des Textes darstellen.
Aufgabe 7
Ersetzen Sie Reader durch TermsBerry. In Verbindung mit welchen vier Wörtern kommt „marinelli” am häufigsten vor und wie verhält es sich mit „emilia”? Welche Rückschlüsse lassen sich hieraus ziehen?
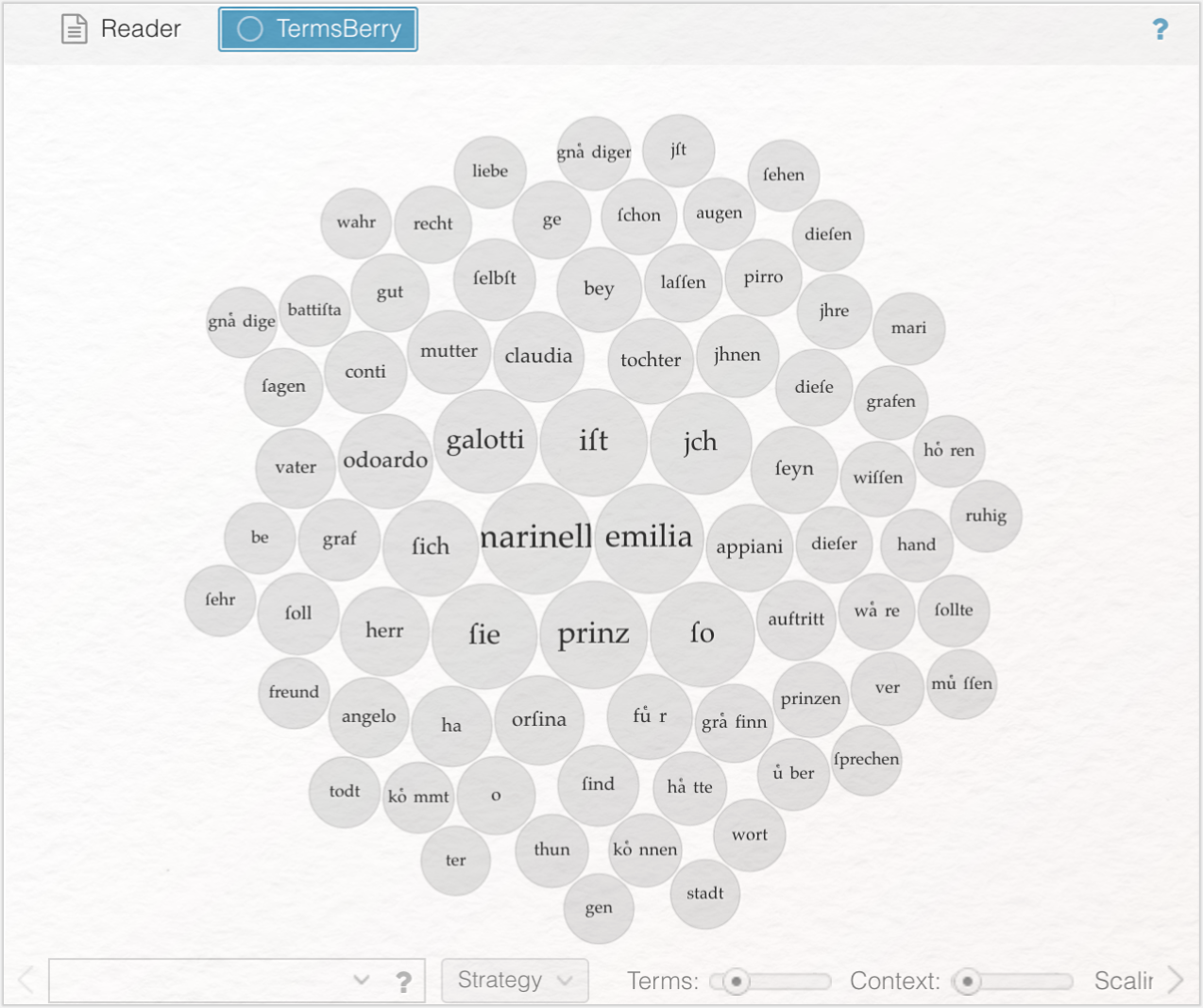
TermsBerry visualisiert – genau wie die Wortwolke – die besonders häufig vorkommende Wörter, indem es diese in zentraler Position und innerhalb einer Bubble mit größerem Radius abbildet. Hovert man über die Wörter, wird durch die Farbgebung angezeigt, mit welchen anderen Wörtern das ausgewählte Wort besonders häufig gemeinsam vorkommt. „marinelli“ kommt am häufigsten in Verbindung mit „prinz” (23) vor, gefolgt von „emilia” (28), „ich” (14) und „ist” (9). „emilia” taucht am häufigsten mit „galotti” (183), „marinelli” (27), „appiani (8) und „orfina” (5) auf. Das Tool eignet sich, um erste Vermutungen bspw. über Figuren und deren Beziehungen zueinander anzustellen. Marinelli scheint in einer sehr engen Beziehung zu dem Prinzen zu stehen. Der Prinz könnte also eine für Marinelli wichtige Bezugsperson darstellen. Anders als für Emilia, die zwar für Marinelli eine wichtige Rolle spielt, mit dem Prinzen aber vergleichsweise wenig interagiert. Marinelli und Emilia können als zentrale Figuren aufgefasst werden. Dass „galotti” überdurchschnittlich oft in Verbindung mit „emilia” vorkommt, ist nicht verwunderlich. Schließlich handelt es sich hierbei um den Nachnamen der Figur. Über Marinelli könnte man mutmaßen, dass er ichbezogene, egozentrische oder besonders selbstbewusste Charaktereigenschaften aufweist, da er den eigenen Standpunkt vertritt und/oder häufiger über sich selbst spricht als Emilia es tut.
Aufgabe 8
Ersetzen Sie Contexts durch Bubblelines und blenden die Wörter „ist” und „sie” aus. Was bildet dieses Tool ab und wie lassen sich die Ergebnisse interpretieren?
Das Tool zeigt, wie häufig die Wörter „marinelli”, „emilia” und „prinz” in dem gesamten Text, der in 50 gleich große Segmente unterteilt wurde, vorkommen. Durch den Vergleich der drei Bubblelines wird deutlich, dass „marinelli” im Vergleich zu „prinz” und „emilia” am häufigsten vorkommt. „emilia” taucht stetig auf, während „marinelli” und „prinz” phasenweise gar nicht vorkommen. Darüber hinaus lässt diese Visualisierung Rückschlüsse auf die Interaktion der Figuren untereinander zu: „prinz” und „marinelli” kommen häufiger zusammen vor als „marinelli” und „emilia”. Der längste zusammenhängende Abschnitt, indem „prinz” und „emilia” gemeinsam vorkommen, findet sich in der Mitte der Bubbleline. Geht man davon aus, dass ein gleichzeitiges Vorkommen beider Wörter auf eine tatsächliche Begegnung und Interaktion beider Figuren miteinander im Text schließen lässt, stehen „marinelli” und der „prinz” sich besonders nahe.
5. Nachweise
-
Stoeva-Holm, Dessislava (2015): „Gefühle worten. Zum Emotionalisieren in zeitgenössischer Literaturkritik“. In: Kaulen, Heinrich und Christina Gansel (Hrsg.) Literaturkritik heute: Tendenzen – Traditionen – Vermittlung. Göttingen: V & R Unipress, 27–42.
