1. Kurzbeschreibung
Das Deutsche Textarchiv (DTA) ist ein digitales Vollltextkorpus historischer Druckwerke zwischen 1600 und 1900 und eignet sich als eine hochwertige Quelle für zitierfähige Primärtexte.
Steckbrief
- http://www.deutschestextarchiv.de
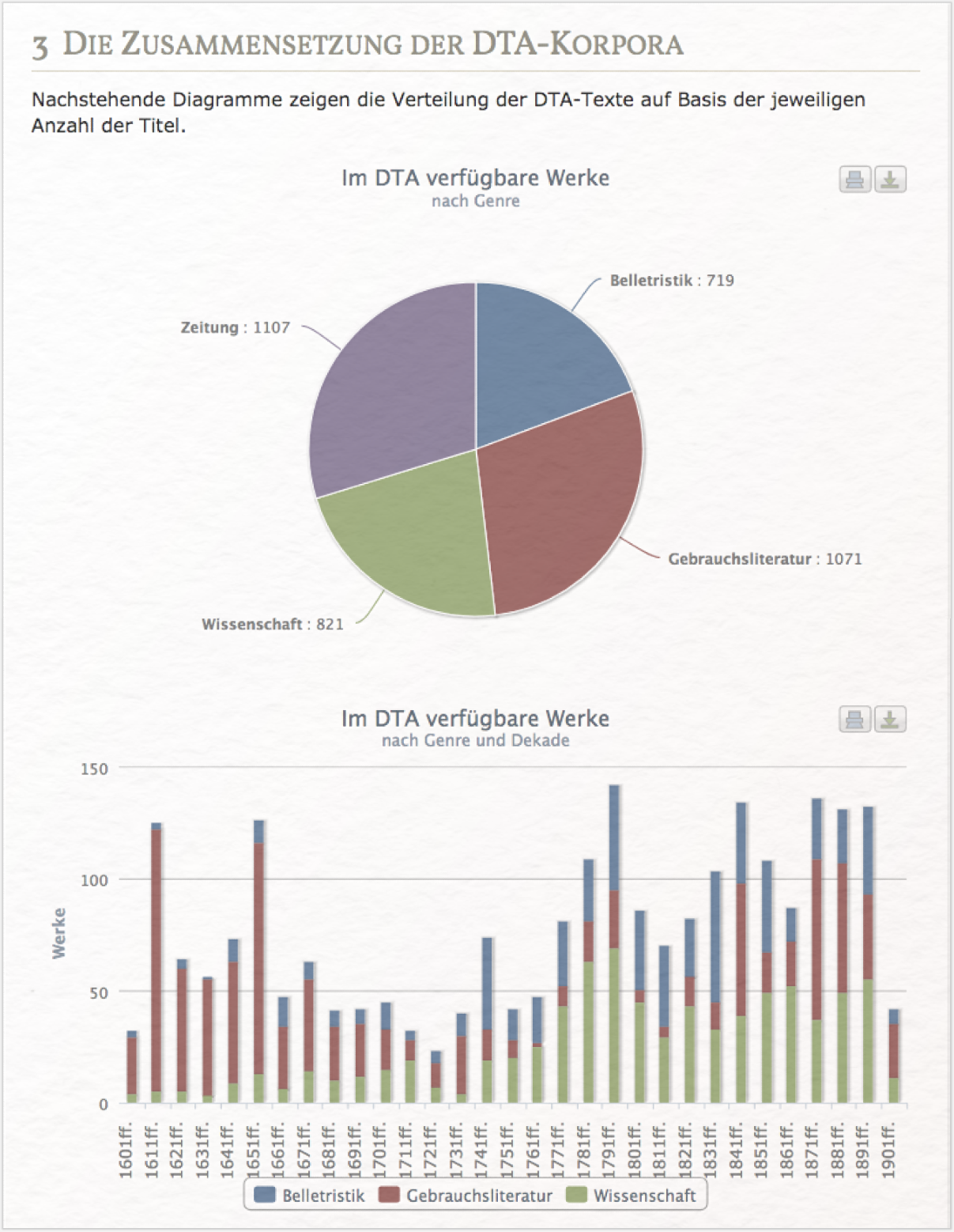
- Volltextsammlung: 4422 deutschsprachige Druckwerke zwischen ca. 1600 und ca. 1900 (aktuelle Zahlen unter: http://www.deutschestextarchiv.de/doku/ueberblick#umfang)
- Ausgaben: vorzugsweise Erstveröffentlichungen, ggf. historisch-kritisch
- Textsorten: Zeitung, Gebrauchsliteratur, Wissenschaft, Belletristik; gedruckte und handschriftliche Vorlagen
- Metadaten: Titel, Autor, Herausgeber, Übersetzer, Ort, Verlag, Auflage, Band (DTA-Basisformat)
- Projekt der Berlin-Brandenburgischen Akademie der Wissenschaften (BBAW), gefördert von der Deutschen Forschungsgemeinschaft (DFG) von 2007 bis 2016; Erweiterung im Rahmen von CLARIN-D von 2017 bis 2020
- Ziel: Abbildung der sprachhistorischen Entwicklungen der deutschen Sprache seit dem Ende der frühneuhochdeutschen Sprachperiode
- Downloadformate: XML (TEI P5), HTML, Text, TCF (text annotation layer), TCF (tokenisiert, serialisiert, lemmatisiert, normalisiert); weitere Downloadformate für Metadaten sowie spezifische Downloadformate für Tools (wie etwa → Voyant)
2. Anwendungsbeispiel
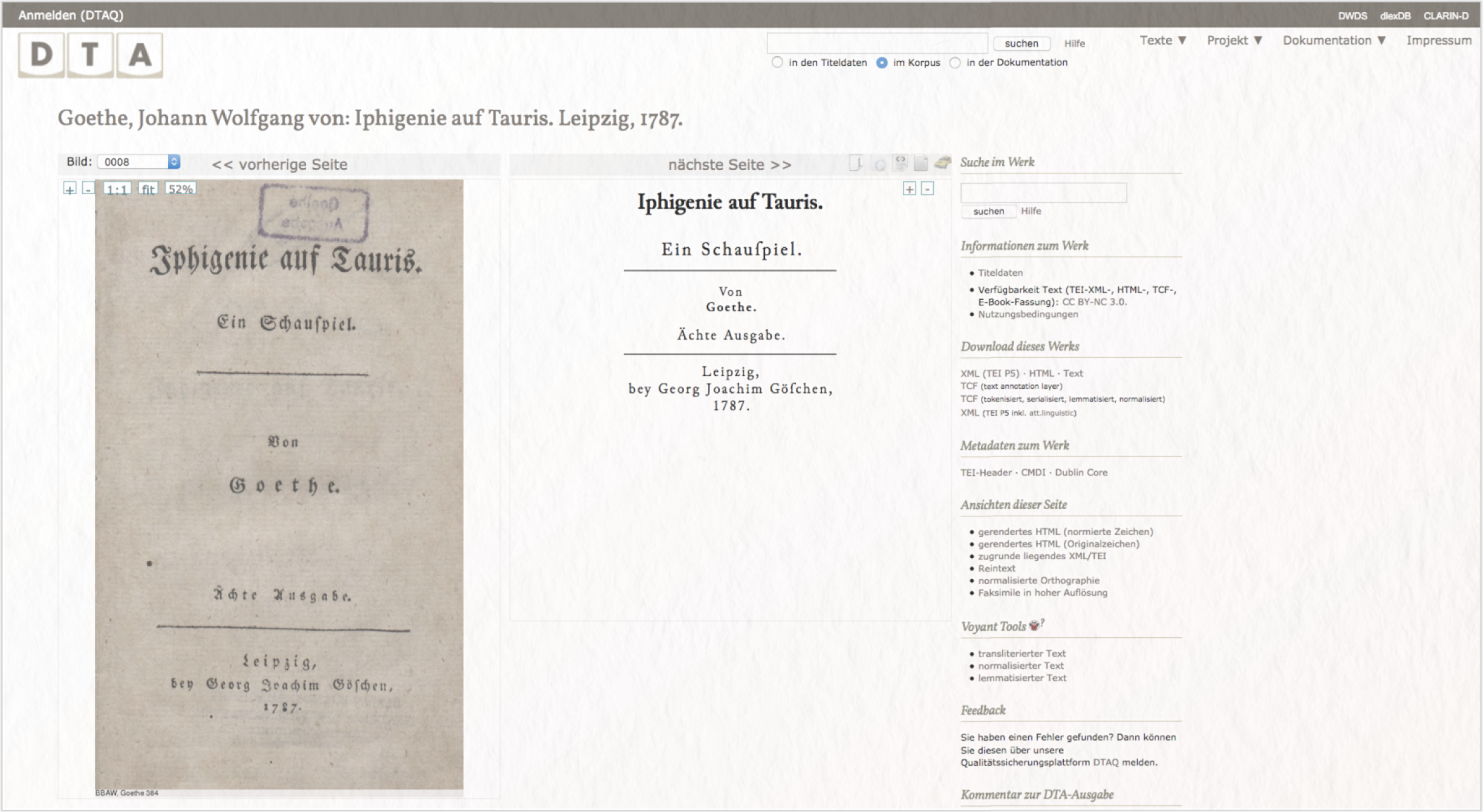
Sie wollen digital unterstützt das Frauenbild in Goethes Iphigenie auf Tauris analysieren. Eine wesentliche Voraussetzung für diesen Anwendungsfall ist, dass Ihnen ein (idealerweise zitierfähiger) digitalisierter Primärtext vorliegt. Je korrekter die zugrundeliegende Textquelle, desto genauer sind auch die an ihr durchgeführten digitalen Methoden der Textanalyse und -annotation. Für das Auffinden eines solchen Textes bietet sich die Suche im Deutschen Textarchiv (DTA) an. Im DTA sind Erstveröffentlichungen und historisch-kritische Ausgaben von Druckwerken, Zeitungen und Manuskripten insbesondere aus der Zeit von 1600 bis 1900 vorhanden, die über eine Schnellsuchfunktion unproblematisch gefunden und open access in unterschiedlichen Dateiformaten heruntergeladen werden können. Die Textsammlung wurde sorgfältig zusammengestellt und beinhaltet zahlreiche Werke einer Vielzahl von Autor*innen.
3. Diskussion
3.1 Kann ich das DTA für wissenschaftliche Arbeiten nutzen?
Ja – denn die hohe Textqualität der DTA-Texte wird u. a. dadurch erreicht, dass sowohl formativ (d. h. vor der Texterfassung) als auch summativ (d. h. nach der Texterfassung) Qualitätskontrollen durchgeführt werden. Das DTA bemüht sich außerdem darum, den historischen Sprachstand der Werke zu bewahren. Deshalb werden möglichst Erst- bzw. frühe Original-Ausgaben der Texte zugrunde gelegt, die zudem strukturell in Kapitel, Unterkapitel und Absätze unterteilt werden. Dargestellt wird jeweils das originale Dokument als Bild in hoher Auflösung und eine entsprechende elektronische Version des Textes.
Die Überführung der für das DTA ausgewählten Texte in elektronische Form erfolgte für 200 Texte im automatischen Verfahren OCR und für ca. 1300 Texte im manuellen Verfahren, bei dem der Text zunächst von Nicht-Muttersprachlern eingegeben wird, um anschließend auf eventuelle Abweichungen hin überprüft zu werden (Double-Keying-Verfahren; s. → Möglichkeiten der Textdigitalisierung). Auch die 200 zunächst automatisch erfassten Texte wurden anschließend manuell korrigiert, um sie dem Qualitätsstandard des DTA anzugleichen. Die Texterfassung und -aufbereitung wird somit von einer ständigen Überprüfung begleitet, die nur dann Korrekturen vornimmt, wenn fehlerhafte Eingaben erkannt wurden oder das historische Dokument lückenhaft bzw. verfälscht ist.
Die formative Qualitätskontrolle umfasst schließlich auch eine ständige Pflege und Überarbeitung der generellen DTA-Richtlinien zur Texterfassung und -annotation, die im Menüpunkt „Dokumentation" verfolgt werden können.
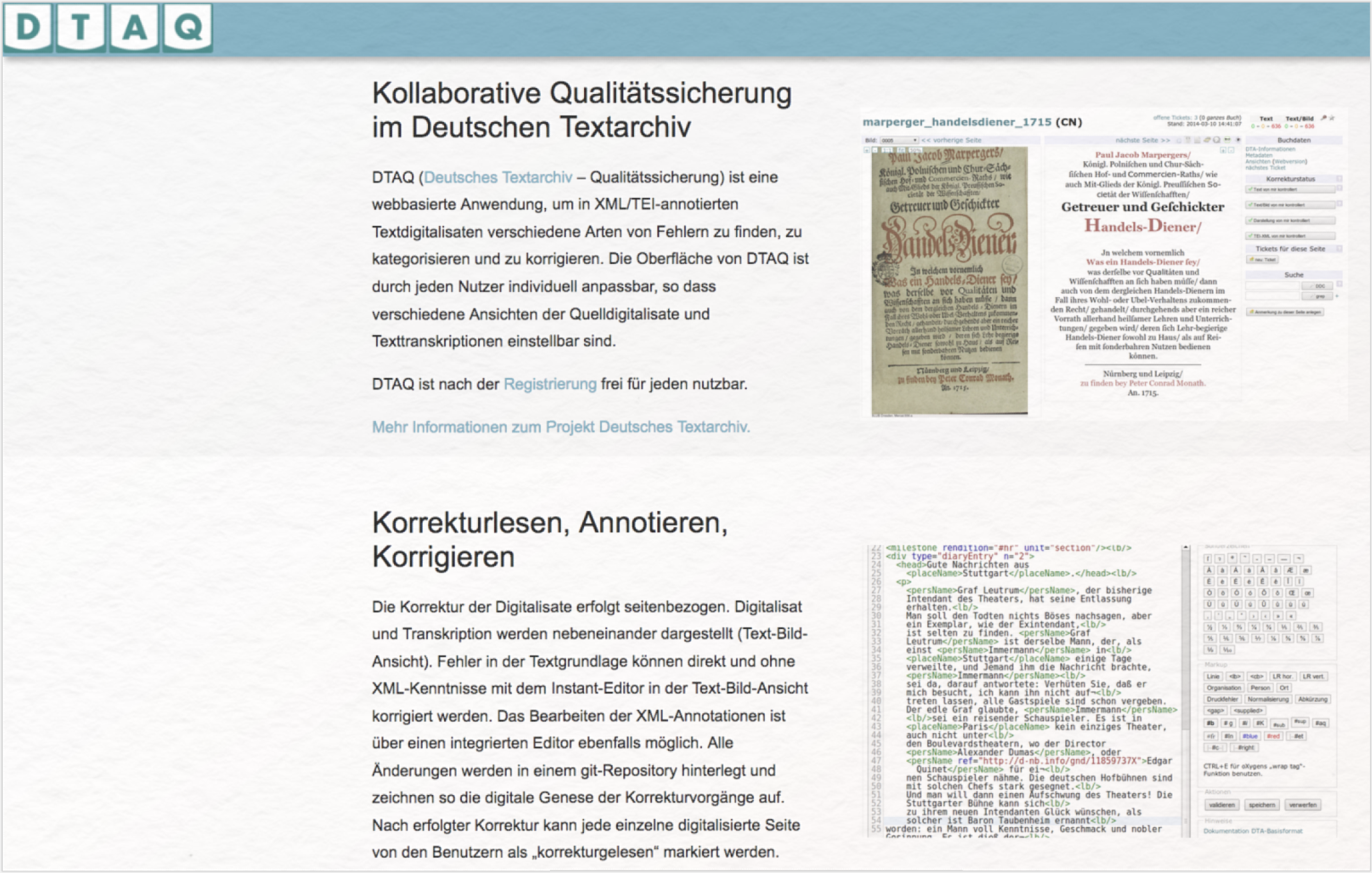
Die Überprüfung der digitalisierten Dokumente endet jedoch nicht mit den hier beschriebenen formativen Qualitätskontrollen, sondern wird summativ durch die webbasierte, kollaborative DTA-Qualitätssicherung (DTAQ) fortgesetzt (siehe Abb. 3). DTAQ ermöglicht registrierten Benutzer*innen, eigene Annotationen und Korrekturen im jeweiligen Text anzumerken, die vom DTA-Team kontrolliert und gegebenenfalls eingearbeitet werden. Außerdem können auch neue Texte eingespeist werden, die wiederum den aufgestellten Richtlinien des DTA für die Texterfassung und Annotation entsprechen müssen. Für ein solches Unterfangen stehen auf der Webseite Vorlagen bereit, die Ihnen anschaulich die einzelnen Schritte aufzeigen.
3.2 Wie benutzerfreundlich ist die Arbeit mit dem DTA?
Das DTA bietet Ihnen eine klar strukturierte, aber komplexe Arbeitsumgebung. In ihren Grundzügen kann sie jedoch auch von Erstnutzer*innen ohne größere Vorkenntnisse durch Ausprobieren erschlossen werden.
Auf der Homepage finden Sie zunächst eine horizontale Navigation mit den Menüpunkten „Texte", „Projekt", „Dokumentation" und „Impressum". Die Menüpunkte gliedern sich wiederum in mehrere Unterpunkte, wie beispielsweise „DTA-Leitlinien", „DTA-Textauswahl" und „DTA-Quellen". Einerseits bringt die große Menge an Unterpunkten den Vorteil mit sich, die Dokumentation der Textauswahl und -aufbereitung ausführlich nachvollziehen zu können, andererseits droht jedoch die Gefahr, dass unerfahrene Nutzer*innen schnell die Übersicht verlieren und nur schwer die wesentlichen Bedienschritte für eine Erstnutzung finden.
Unterstützung bei der Bedienung und Nutzung des DTA finden Sie unter dem Menüpunkt „Dokumentation", Unterkategorie „Hilfe". Hier werden u. a. die DTA-Leitlinien, die DTA-Richtlinien zur Texterfassung, das DTA-Basisformat, die sog. Korrekturfibel (für eigene Anmerkungen und Korrekturen) sowie die verschiedenen Ansichten der Texte komprimiert erklärt.
Mögliche Fragen bezüglich der Bedienung und Nutzung der Suchmaschinen bleiben dennoch unbeantwortet. Diese können jedoch in den Unterpunkten „linguistische Suche" bzw. „Projektüberblick" oder unter dem Button „Hilfe" (neben der Navigation) nachgelesen werden. Nachteil an einer solchen Form der Darstellung ist, dass vorrangig linguistische Suchanfragen bzw. die Nutzung der systemimmanenten Suchmaschine DDC beschrieben und mit Hilfe von Beispielen veranschaulicht werden. Unerfahrene Nutzer*innen können schnell durch die ausführlichen Beschreibungen verunsichert werden und erhalten keine konkreten Antworten auf Belange, die nicht linguistischer Natur sind.
Insgesamt erfordert die Bedienung der Schnellsuchfunktion, die vor allem für die Recherche nach bestimmten Texten nützlich ist, jedoch keine größeren Vorkenntnisse und kann auch von Erstnutzer*innen durch eigenes Ausprobieren erschlossen werden. Die Volltexte selbst werden seitenweise sowohl als Bild der originalen Vorlage als auch als HTML-Version dargestellt, die den historischen Text in eine moderne Schriftart überführt hat, sodass auch Texte, die ursprünglich in einer Frakturschrift oder handschriftlich veröffentlicht wurden, für alle Nutzer*innen lesbar sind.
Sollten sich bei der Nutzung größere Schwierigkeiten ergeben, können Sie das Team des DTA entweder schriftlich über ihre Mail-Adresse (Menüpunkt „Impressum") kontaktieren oder eine der vom DTA angebotenen Schulungen besuchen. Bei den Schulungen erhalten Sie einen Einblick über die DTA-Erfassungsrichtlinien sowie das DTA-Basisformat und lernen über praxisnahe Beispiele den Umgang mit der Suchmaschine DDC. Bei Bedarf bietet das DTA zudem an, Transkriptions- und Annotationsarbeiten kontinuierlich zu begleiten und zu kontrollieren.
4. Wie funktioniert die Textsuche im DTA?
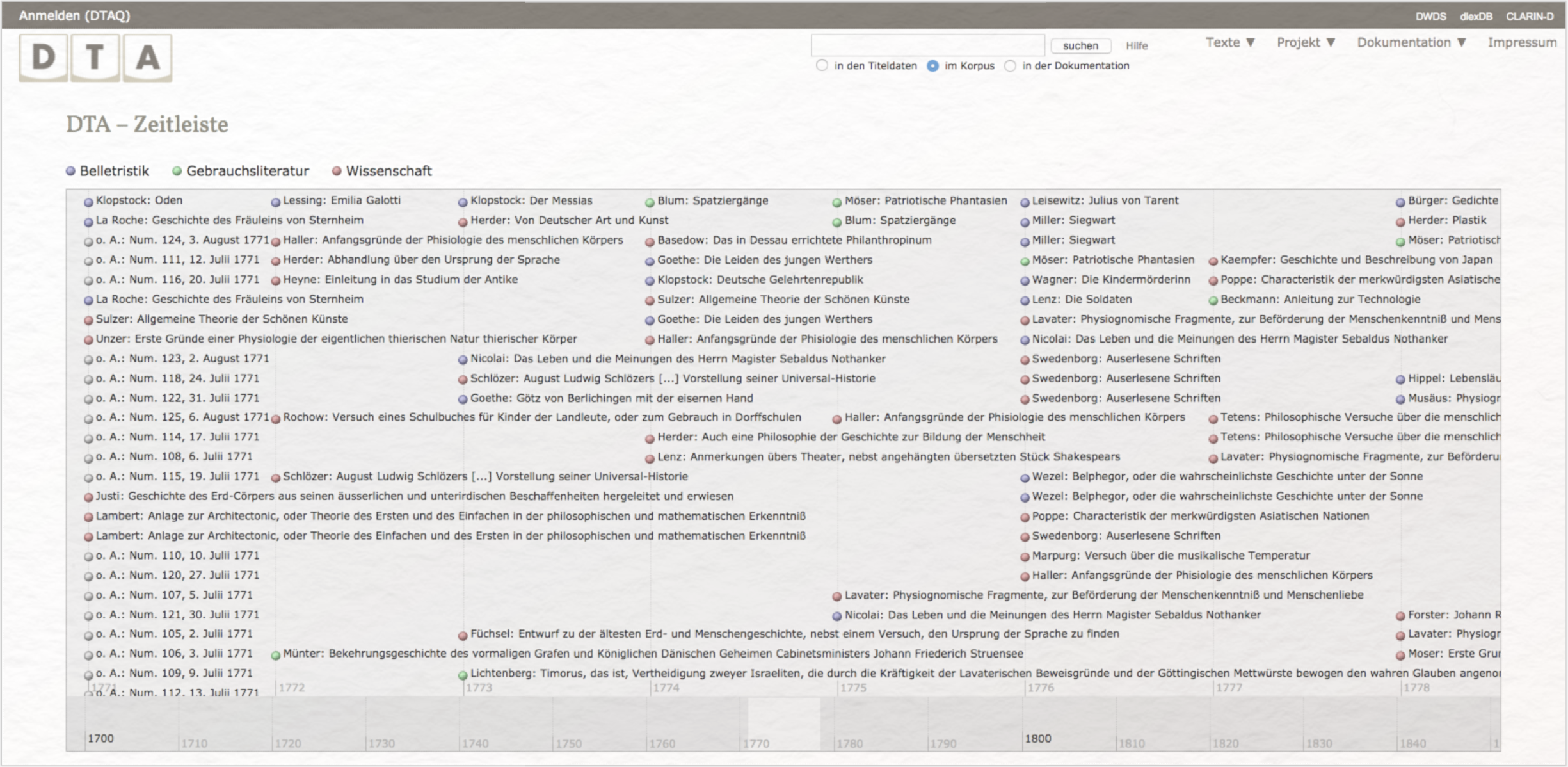
Sind Sie noch unschlüssig, welchen Primärtext Sie für Ihre Untersuchung heranziehen wollen, können Sie ohne viel Aufwand in der Textsammlung des DTA stöbern. Hierfür müssen Sie lediglich den Menüpunkt „Texte", Unterkategorie „Verfügbar" oder „Zeitleiste", auswählen, um eine alphabetisch oder zeitlich sortierte Auflistung (siehe Abb. 4) der Druckwerke zu erhalten.
Möchten Sie jedoch einen bestimmten Primärtext auffinden, empfiehlt es sich, die Schnellsuchfunktion auf der Startseite links neben der Navigation zu nutzen. In das Suchfeld können Sie den Autor*innennamen oder den Titel des Druckwerkes eingeben. Vor der Suche sollten Sie unter dem Suchfeld festlegen, ob Sie die „Titeldaten", das „Korpus" oder die „Dokumentation" durchsuchen wollen. Suchen Sie nach (literarischen) Primärtexten, sollten Sie entweder die Titeldaten oder das Korpus auswählen. Beide Fundorte leiten Sie zu einer neuen Ansichtsseite weiter, auf der die Suchergebnisse dargestellt werden. Die Informationen zu den einzelnen Suchergebnissen führen die wesentlichen Metadaten wie den Titel, die Auflage, den Autor*innennamen, das Erscheinungsjahr bzw. den -ort und den Umfang des Druckwerkes auf. Über einen Doppelklick auf den Titel kann das Druckwerk auf einer eigenen Ansichtsseite vollständig eingesehen werden.
Sollte bei den ersten Suchergebnissen das von Ihnen gesuchte Werk nicht dabei sein, können Sie Ihre Suche über weitere Angaben verfeinern. Für ein solches Unterfangen stehen Ihnen oben auf der Ansichtsseite der Suchergebnisse Filteroptionen, wie der Autor*innenname, der Titel, die Klassifikation, der Druckort, der Verlag oder auch das Erscheinungsjahr des Werkes zur Verfügung. Die einzelnen Filteroptionen sind zudem miteinander kombinierbar. Bei einer erfolgreichen Suche kann das Druckwerk in unterschiedlichen Formaten (verschiedene XML-, HTML-, Text- und TCF-Formate) und sogar in normalisierter Orthografie (was für einige Verfahren des Distant Reading sinnvoll sein kann) heruntergeladen und weiterverwendet werden.
Sie sind etwas experimentierfreudiger? Dann kann es zudem lohnend sein, sich genauer mit der Funktion der linguistischen Suchmaschine DDC zu beschäftigen. Sie ermöglicht es, nach einer exakten Wortform, einer flektierten (z. B. die Anfrage nach „sprach“ liefert u. a. die Ergebnisse für „sprechen“, „spricht“, „gesprochen“) oder graphematischen Variante für ein Wort (z. B. „Kleid“: „Kleidt“, „Kleydt“, „Cleyd“, „Cleit“ etc.) zu suchen und erleichtert es so, die sprachliche Ausgestaltung eines Textes zu erfassen.
5. Weiterführende Literatur
- Geyken, Alexander, Matthias Boenig, Susanne Haaf, Bryan Jurish, Christian Thomas und Frank Wiegand (2018): „Das Deutsche Textarchiv als Forschungsplattform für historische Daten in CLARIN“. In: Henning Lobin; Roman Schneider und Andreas Witt (Hrsg.): Digitale Infrastrukturen für die germanistische Forschung. Berlin, Boston: de Gruyter, 219–248.
- Geyken, Alexander und Thomas Gloning (2015): „A living text archive of 15th-19th-century German. Corpus strategies, technology, organization“. In: Jost Gippert und Ralf Gehrke (Hrsg.): Historical Corpora. Challenges and Perspectives. Tübingen: Narr, 165–180.
- Haaf, Susanne, Alexander Geyken und Frank Wiegand (2015): „The DTA 'Base Format': A TEI Subset for the Compilation of a Large Reference Corpus of Printed Text from Multiple Sources“. In: Journal of the Text Encoding Initiative. DOI: 10.4000/jtei.1114.
- Haaf, Susanne und Christian Thomas (2016): „Die Historischen Korpora des Deutschen Textarchivs als Grundlage für sprachgeschichtliche Forschungen“. In: Holger Runow; Volker Harm und Levke Schwiek (Hrsg.): Sprachgeschichte des Deutschen: Positionierungen in Forschung, Studium, Schule. Stuttgart: Hirzel, 217–234.
- Haaf, Susanne und Christian Thomas (2016): „Enabling the Encoding of Manuscripts within the DTABf: Extension and Modularization of the Format“. In: Journal of the Text Encoding Initiative (jTEI). DOI: 10.4000/jtei.1650. Text abrufbar unter: https://journals.openedition.org/jtei/1650.
- Haaf, Susanne (2017): „Das DTA-Basisformat in neuem Gewand“. In: Im Zentrum Sprache. Untersuchungen zur deutschen Sprache in Geschichte und Gegenwart, URL: https://sprache.hypotheses.org/147 [Zugriff: 13.7.2018].
- Wiegand, Frank, Christian Thomas, Susanne Haaf, Alexander Geyken, Bryan Jurish und Matthias Boenig (2018): „Recherchieren, Arbeiten und Publizieren im Deutschen Textarchiv: ein Praxisbericht“. In: Zeitschrift für Germanistische Linguistik. 46 (1), 147–161. DOI: 10.1515/zgl-2018-0009.
