CorpusExplorer

Der CorpusExplorer ist ein computerlinguistisches Tool zur Aufbereitung und Analyse von Korpora. Es kann zur explorativen Erforschung von Texten in digitaler Form genutzt werden und bietet eine Vielzahl an Auswertungsfunktionen.
Der CorpusExplorer ist ein computerlinguistisches Tool zur Aufbereitung und Analyse von Korpora. Es kann zur explorativen Erforschung von Texten in digitaler Form genutzt werden und bietet eine Vielzahl an Auswertungsfunktionen.
Mit dem DARIAH Topics Explorer kann Topic Modeling ohne Vorkenntnisse über eine grafische Nutzeroberfläche durchgeführt werden. Fragestellungen nach Themenfeldern in Textsammlungen, wie z. B. „Welche Themen kommen in Goethes Prosawerken gehäuft vor und wie verteilen sie sich über die einzelnen Texte?", können damit untersucht werden.
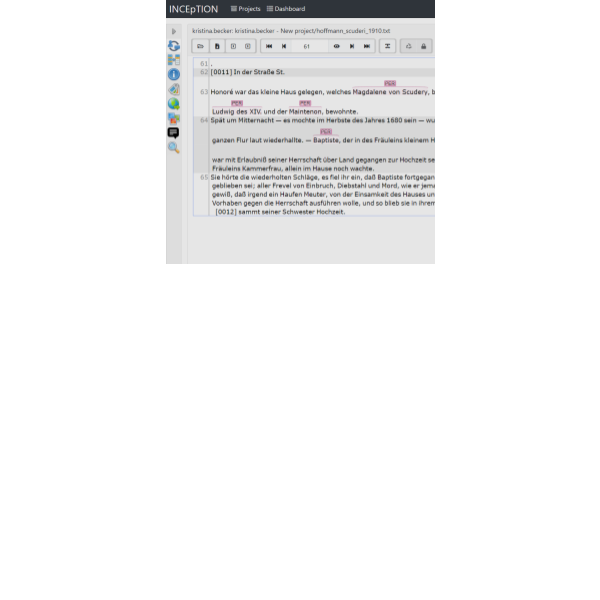
INCEpTION ist ein im Browser laufendes Tool zur manuellen und automatischen Annotation von großen Textsammlungen. Ferner unterstützt es kollaboratives Arbeiten an Texten und bietet das automatische Berechnen einer Übereinstimmung zwischen Annotator*innen (inter-annotator agreement) an.
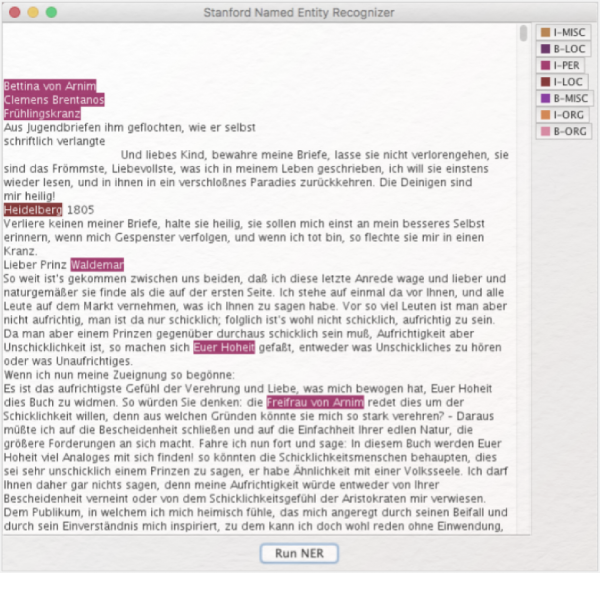
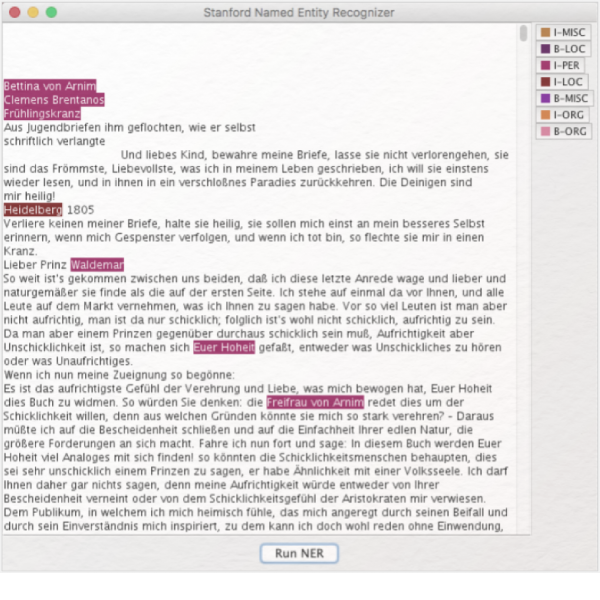
Mit Stanford-NER können vor allem Fragen nach quantitativen Aspekten von Figurennamen, Orten und Organisationen bearbeitet werden, wie etwa: Wie viele Figuren werden in einem Text benannt, und welche Figuren werden am häufigsten erwähnt? Was für Orte kommen vor, und wie ist die Verteilung von Ortsnennungen? Oder zum Beispiel: In welchem Kontext werden Organisationen genannt?
Unter kollaborativem literaturwissenschaftlichem Annotieren ist eine Praxis kooperativen Arbeitens zu verstehen, bei der sich mehrere Forschende gemeinsam der Annotation literarischer Texte annehmen. Während hierbei unterschiedliche Modi der Kooperation möglich sind, widmet sich der vorliegende Beitrag ausschließlich einer spezifischen Unterform des kollaborativen Annotierens: der gemeinsamen Arbeit an derselben Textgrundlage vor dem Hintergrund derselben Fragestellung.
Unter (digitalem) manuellem Annotieren versteht man die Praxis, in Texten digital Hervorhebungen oder Anmerkungen anzubringen. Diese können ganz unterschiedlichen Zwecken dienen – beispielsweise der Strukturierung von Texten, ihrer sprachlichen oder inhaltlichen Beschreibung, ihrer Kontextualisierung oder Interpretation.
Named Entity Recognition (NER) ist ein Verfahren, mit dem klar benennbare Elemente (z.B. Namen von Personen oder Orten) in einem Text automatisch markiert werden können. Named Entity Recognition wurde im Rahmen der computerlinguistischen Methode des Natural Language Processing (NLP) entwickelt, bei der es darum geht, natürlichsprachliche Gesetzmäßigkeiten maschinenlesbar aufzubereiten.
Topic Modeling ist ein auf Wahrscheinlichkeitsrechnung basierendes Verfahren zur Exploration größerer Textsammlungen. Das Verfahren erzeugt statistische Modelle (Topics) zur Abbildung häufiger gemeinsamer Vorkommnisse von Wörtern.
● Anwendungsbezug: Hans Christian Andersens Märchen
● Methodik: Topic Modeling in Prosatexten eines Autors
● Angewendetes Tool: DARIAH Topics Explorer
● Lernziele: Zusammenstellung und thematische Exploration einer kleinen bis mittelgroßen Textsammlung, Installation des Tools, Auswertung/Interpretation der Ergebnisse
● Dauer der Lerneinheit: ca. 90 Minuten
● Schwierigkeitsgrad des Tools: leicht bis mittel
● Thema der Sitzung: Themen und Topics bei Friedrich Schiller und Wilhelm Hauff
● Lernziele: Kenntnisse über die Methode des Topic Modeling, sicherer Umgang mit dem DARIAH Topics Explorer, kritische Bewertung der Methode, Autoren- und Epochenkenntnisse (Sturm und Drang, Weimarer Klassik, Romantik)
● Phasen: Einführende Begriffsdisskussion (Themen vs. Topics), Vorstellung und Diskussion der Methode, Demonstration der Toolfunktionen, Gruppenarbeit, Gruppenpräsentationen
● Sozialformen: Diskussion, Vortrag, Gruppenarbeit
● Medien/Materialien: Alle Lernenden müssen einen Laptop haben, auf dem der DARIAH Topics Explorer installiert ist; Lehrende benötigen einen Laptop und Beamer
● Dauer des Lehrmoduls: 2 x 90 Minuten
● Schwierigkeitsgrad des Tools: leicht bis mittel
word2vec ist eine computergestützte Methode, um Ähnlichkeiten zwischen Wörtern aufgrund ihrer kontextuellen Merkmale numerisch zu erfassen. Am häufigsten wird sie zur Analyse der semantischen Verbindungen zwischen Wörtern in einem Textkorpus eingesetzt. Dem Verfahren liegt eine Beobachtung über den Gebrauch von Wörtern in unserer Alltagssprache zugrunde: Semantisch ähnliche Wörter treten in ähnlichen Kontexten auf. Das Vorkommen eines Wortes kann demnach anhand seiner Kontexte (d.h. anhand seiner unmittelbaren Nachbarschaften in einem Satz) vorhergesagt werden, und umgekehrt.