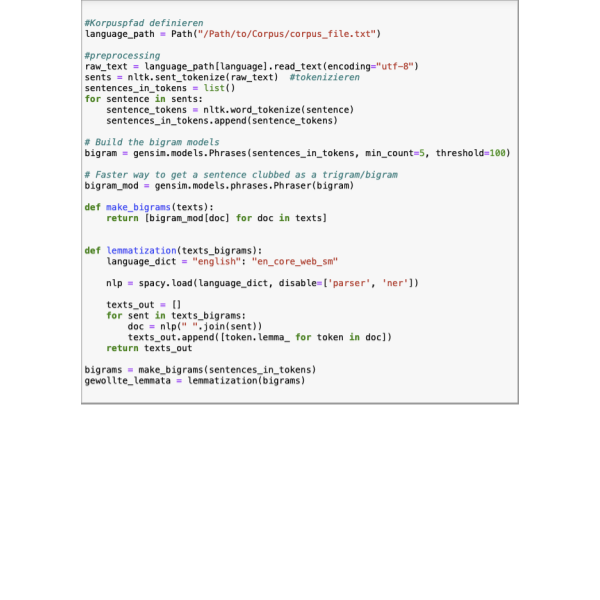
word2vec mit Gensim
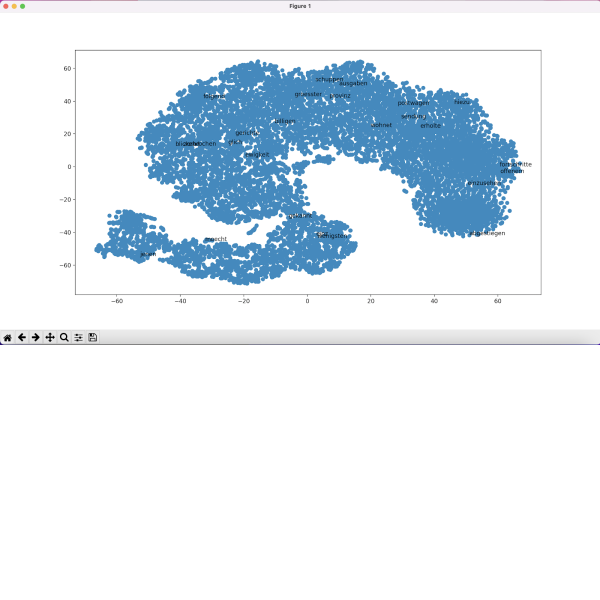
● Anwendungsbezug: Frauen- und Männerrollen in Goethes Erzähltexten und Dramen
● Methode: word2vec
● Angewendetes Tool: Gensim
● Lernziele: Trainieren eines word2vec-Modells, einfache Abfragen und Vektorarithmetik, erstellen von Visualisierungen zum gesamten Korpus und zu einzelnen semantischen Feldern
● Dauer der Lerneinheit: 60-90 Minuten
● Schwierigkeitsgrad des Tools: mittel